Recurrent Neural Network(RNN)——循环神经网络
循环神经网络(RNN),附代码
参考:(代码目前版本基本是参考沐神的)
[1] https://www.bilibili.com/video/BV1BQ4y1R7V7?p=3
[2] https://www.bilibili.com/video/BV1kq4y1H7sw?spm_id_from=333.999.0.0
在小规模问题上,RNN可能效果还是不错。
特点:输入和输出长度无需固定,适合语音,文本等时序序列数据。
RNN架构
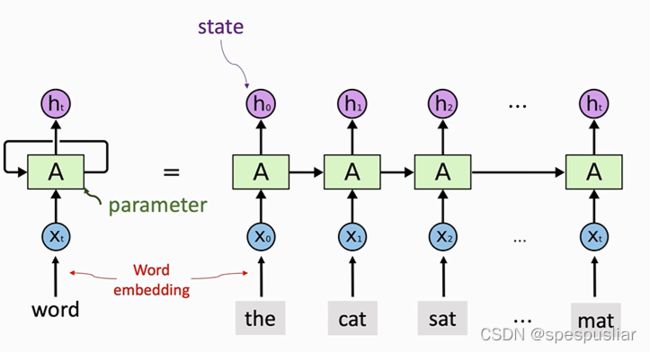
上图为RNN的整体架构,RNN每次看到一个词,通过状态hi来积累看到的信息。例如,h0包含x0的信息,h1包含x0和x1的信息,最后一个状态ht包含了整句话的信息,从而可以把它作为整个句子的特征,用来做其他任务,比如分类。这是从架构图中直观看到的信息。注意,无论RNN的链条有多长,都只有一个参数矩阵A,A可以随机初始化,然后再通过训练来学习。
RNN具体状态更新过程
![]()
这个公式是从沐神[2]视频中截取的,用架构图中的形式描述可以写为下式:
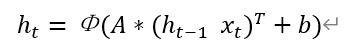
这个b(bias)加不加其实都是可以的,不加比较简单,就像刚上手神经网络的时候,y=Wx+b,就干脆省掉b,方便学习。
![]()
(h_t-1 x_t)^T这个表示h_t-1和x_t拼接起来的转置,A就是第一个公式中Whh和Whx的拼接,所以两个是一模一样的。
计算可视化
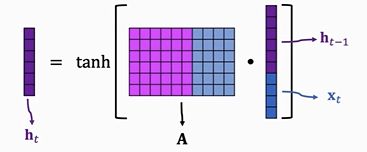
RNN的激活函数用的是tanh,非sigmoid和relu
计算过程上面也有说明了,就是将上一个隐藏状态h_t-1和当前的输入x_t拼接在一起,和参数矩阵A相乘,然后在外面套一个激活函数tanh
tanh激活函数是个什么
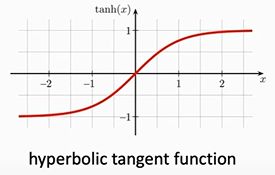
这个就是可以将自变量映射到-1到1之间的一个函数,叫双曲正切函数,定义式长这样。

那么为什么要用tanh作为激活函数?
设想一下,如果没有这个激活函数,输入的xi为全0向量,那么状态更新就变成了如下所示:
![]()
由此可以推导h_100 = Ah_99 = … = A^100h_0
若A的特征值是0.9,0.9的100次方是非常接近0的,h_100就几乎是一个0向量;同样地,若A的特征值是1.1,1.1的100次方是非常大的,h_100可能就溢出了。
用了tanh激活函数就会让每个数字映射到-1到1的这个合理的区间中。
RNN的用法
RNN的用法有两种,一种是直接将最后一个状态h_t拿出来作为最终的输出,也可以将所有状态一起拿出来作为最终的输出。
第二种用法的具体操作可以为:将h1,h2……ht拼接成一个大矩阵,然后用flatten将这个矩阵展开成一个向量,然后乘上一个参数矩阵套一层激活函数作为输出。
Simple RNN的缺陷
上述介绍的是Simple RNN,缺陷也是比较容易看出来的。
短期性:距离某个输入较远的隐状态h几乎不会受到这个输入的影响。
例如,h_100很可能和x_0已经无关了。
到这里可能就疑惑了,从架构图中不是看得出来h_100包含x0到x100的所有信息吗?但是h_100毕竟只是一个隐状态,而且离x0是非常远的,离x100是很近的,那它很明显要更关心和它更亲近的人,即h_100是和x100最相关的,这就是Simple RNN的短期性或者遗忘性的问题。
提升效果的办法:多层RNN,双向RNN
多层RNN(Stacked RNN)
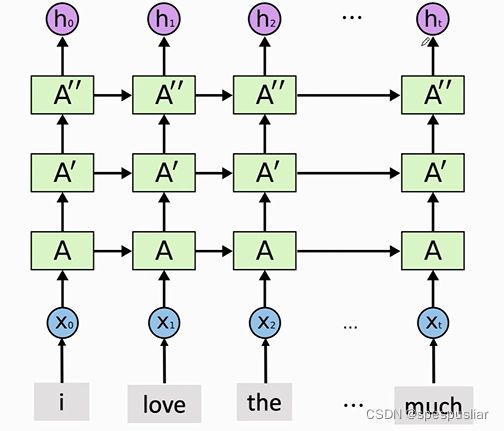
这个比较简单,就是将一层一层的RNN拼接起来,下层的输出作为上层的输入,注意这里需要下层的h1到ht的所有状态,而不是只要ht一个状态。
每一层都是自己的参数矩阵A
双向RNN(Bidirectional RNN)
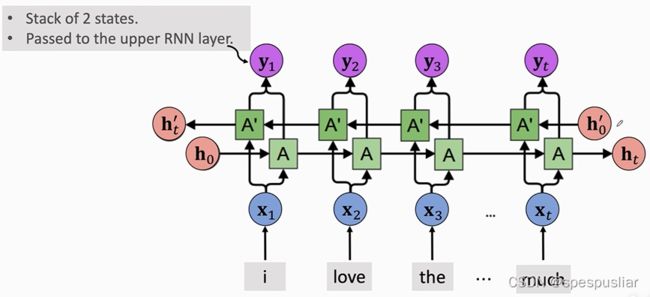
就是两条独立的RNN,一条从右往左读数据,一条从左往右读数据。
不共享参数,不共享状态,两条RNN各自输出自己的状态向量h,然后拼接起来成y,如果有多层,就把y作为上层的输入;如果没有多层,y可以都丢掉,只保留两条RNN最后的状态向量,ht和ht’,把他们拼接起来作为最后的特征来完成任务。
双向的RNN总是比Simple RNN效果好,这也是比较好理解的,Simple RNN容易忘掉早些的输入,双向的恰恰把早些的输入记的更深了。
还有个提升效果的办法的预训练,这个就不多说了,懂得都懂,不懂的可以搜一下,火的不得了。
代码实现:
先放沐神的版本,后面我自己写的版本。
import 模块
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' #不加这个我的程序在训练时候会报一个dll的错误
定义batch_size、num_steps,导入数据
batch_size, num_steps = 32, 35 #num_steps是时间T的大小,一次看多长的序列 输入是batch_size*vocab_size (因为输入的编码的char级别的onehot向量)
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab可以看成是一个dict,keys是包含26个字母和’’,’ '(空格)两个元素
train_iter是包含训练数据的内容,已经封装好了,由于不是RNN的重点,就不细说了。里面的内容如下

从X和Y中的内容和vocab可以看出,Xi表示一个字母,是char级别的,而非word级别的
所需求解的RNN层参数W_xh、W_hh、b_h、输出层参数W_hq、b_q
因为是手撸RNN,所以需要先将参数矩阵都显式写出来,后面需要用矩阵乘法来实现
至于为什么写成一个函数的形式,这是为了方便封装,实现模型时显得简洁
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01 #使得后面的矩阵按照正态分布初始化
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens))
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
RNN的运算实现
def rnn(inputs, state, params):
# `inputs`的形状:(`时间步数量`,`批量⼤⼩`,`词表⼤⼩`)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# `X`的形状:(`批量⼤⼩`,`词表⼤⼩`)
for X in inputs:
#W_xh:num_inputs, num_hiddens;W_hh:num_hiddens, num_hiddens
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
为什么inputs的形状是(num_steps,batch_size,vocab_size)而不是(batch_size,num_steps,vocab_size)
这是因为每次送入模型运算的是当前时间步Xi下的字符,而不能将所有时间步都送入,所以要先将inputs转置成(num_steps,batch_size,vocab_size),每次取一个时间步作为输入
从零开始实现的循环神经⽹络模型
class RNNModelScratch:
def __init__(self, vocab_size, num_hiddens, device, get_params, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state = (torch.zeros((batch_size, num_hiddens), device=device),)
self.forward_fn = forward_fn
self.num_hiddens = num_hiddens
def __call__(self, X, state):
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
return (torch.zeros((batch_size, self.num_hiddens), device=device),) #这是用了沐神的代码,为了后面lstm等模型修改方便,就写成了元组形式
定义预测函数
def predict_ch8(prefix, num_preds, net, vocab, device): #@save
"""在`prefix`后⾯⽣成新字符。"""
state = net.begin_state(batch_size=1, device=device) #batch_size是1,一次输入一个预测一个
outputs = [vocab[prefix[0]]]
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)) #每次都拿output中的最后一个,也就是已经预测的来预测下一个
for y in prefix[1:]: #
_, state = net(get_input(), state) #把state更新到目前输入的state
outputs.append(vocab[y]) #output中有目前已经有的是输入的字符,这个用真实的y
for _ in range(num_preds): # 预测`num_preds`步
y, state = net(get_input(), state) #更新一次,预测一次
outputs.append(int(y.argmax(dim=1).reshape(1))) #预测的添加到output里
return ''.join([vocab.idx_to_token[i] for i in outputs]) #转成字符串
实例化模型
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params, rnn)
可以试一下predict_ch8函数,net还未训练,应该是会胡言乱语

梯度剪裁(防止梯度爆炸)
def grad_clipping(net, theta):
"""裁剪梯度。"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
训练一个epoch
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练模型⼀个迭代周期(定义⻅第8章)。"""
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和, 词元数量,算perplexity
for X, Y in train_iter:
if state is None or use_random_iter:
# 在第⼀次迭代或使⽤随机抽样时初始化`state`
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# `state`对于`nn.GRU`是个张量
state.detach_()
else:
# `state`对于`nn.LSTM`或对于我们从零开始实现的模型是个张量
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
else:
l.backward()
grad_clipping(net, 1)
# 因为已经调⽤了`mean`函数
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
完整训练
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,
use_random_iter=False):
"""训练模型(定义⻅第8章)。"""
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(
net, train_iter, loss, updater, device, use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
结果
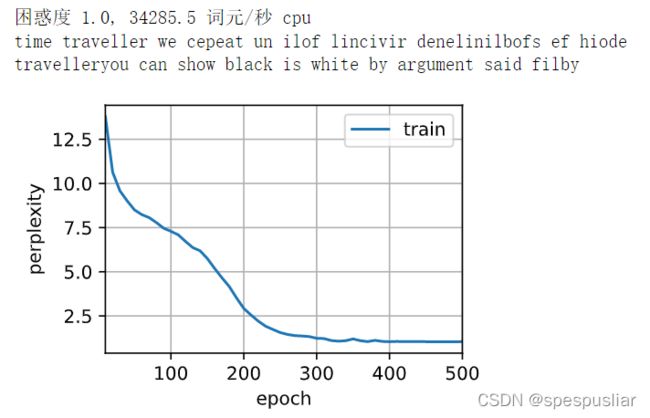
自己写的版本:
import 模块
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
batch_size, num_steps = 32, 35 #num_steps是时间T的大小,一次看多长的序列 输入是batch_size*vocab_size
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
梯度剪裁
def grad_clipping(net, theta): #@save
"""裁剪梯度。"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
模型定义
import torch.nn as nn
def normal(shape):
return torch.randn(size=shape,requires_grad=True) * 0.01
class SimpleRNN(nn.Module):
def __init__(self, batch_size, time_steps, embedding_size, num_hiddens,num_outputs):
super(SimpleRNN,self).__init__()
self.embedding_size = embedding_size
# 隐藏层参数
self.Linear1 = nn.Linear(embedding_size, num_hiddens,bias = False)
self.Linear2 = nn.Linear(num_hiddens, num_hiddens,bias = True)
self.acti = torch.tanh
# 输出层参数
self.out_layer = nn.Linear(num_hiddens, num_outputs,bias = True)
self.init_state = torch.zeros(batch_size, num_hiddens)
def forward(self, X, state=None):
if state == None:
H = self.init_state
else:
H = state
outputs = []
X = F.one_hot(X.T, self.embedding_size).type(torch.float32)
for x in X:
H = self.acti(self.Linear1(x)+self.Linear2(H))
Y = self.out_layer(H)
outputs.append(Y)
return torch.cat(outputs, dim=0), H
训练
net = SimpleRNN(32,35,28,512,28)
num_epoch = 3
loss = nn.CrossEntropyLoss()
lr=1
updater = torch.optim.SGD(net.parameters(), lr)
num_hiddens = 512
for epoch in range(500):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和, 词元数量
train_loss = 0.0
state = torch.zeros(batch_size, num_hiddens)
for X, Y in train_iter:
state.detach_()
y = Y.T.reshape(-1)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
metric.add(l * y.numel(), y.numel())
print(math.exp(metric[0] / metric[1]), metric[1] / timer.stop())
预测
prefix = 'time traveller '
num_preds = 20
state = torch.zeros(1, num_hiddens)
outputs = [vocab[prefix[0]]]
get_input = lambda: torch.tensor([outputs[-1]]).reshape((1, 1))
for y in prefix[1:]:
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds): # 预测`num_preds`步
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
print(''.join([vocab.idx_to_token[i] for i in outputs]))