图神经网络----GCN图卷积神经网络+代码理解
关于负采样:
-
负采样的长度, 肯定是和 有值的ui对的数量是一样的
- :
(文章写得非常好,看不懂的是傻瓜......)
GCN的概念首次提出于ICLR2017(成文于2016年):

一、GCN 是做什么的
在扎进GCN的汪洋大海前,我们先搞清楚这个玩意儿是做什么的,有什么用。
图片或者语言,都属于欧式空间的数据,因此才有维度的概念,欧式空间的数据的特点就是结构很规则。但是现实生活中,其实有很多很多不规则的数据结构,典型的就是图结构,或称拓扑结构,如社交网络、化学分子结构、知识图谱等等;即使是语言,实际上其内部也是复杂的树形结构,也是一种图结构;而像图片,在做目标识别的时候,我们关注的实际上只是二维图片上的部分关键点,这些点组成的也是一个图的结构。
图的结构一般来说是十分不规则的,可以认为是无限维的一种数据,所以它没有平移不变性。每一个节点的周围结构可能都是独一无二的,这种结构的数据,就让传统的CNN、RNN瞬间失效。所以很多学者从上个世纪就开始研究怎么处理这类数据了。这里涌现出了很多方法,例如GNN、DeepWalk、node2vec等等,GCN只是其中一种,这里只讲GCN,其他的后面有空再讨论。
GCN,图卷积神经网络,实际上跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据。GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding),可见用途广泛。因此现在人们脑洞大开,让GCN到各个领域中发光发热。
二、GCN 长啥样,吓人吗?
GCN的公式看起来还是有点吓人的,论文里的公式更是吓破了我的胆儿。但后来才发现,其实90%的内容根本不必理会,只是为了从数学上严谨地把事情给讲清楚,但是完全不影响我们的理解,尤其对于我这种“追求直觉,不求甚解”之人。
下面进入正题,我们直接看看GCN的核心部分是什么样子:
假设我们手头有一批图数据,其中有N个节点(node),每个节点都有自己的特征,我们设这些节点的特征组成一个N×D维的矩阵X,然后各个节点之间的关系也会形成一个N×N维的矩阵A,也称为邻接矩阵(adjacency matrix)。X和A便是我们模型的输入。
GCN也是一个神经网络层,它的层与层之间的传播方式是:

这个公式中:
- A波浪=A+I,I是单位矩阵
- D波浪是A波浪的度矩阵(degree matrix),公式为
- H是每一层的特征,对于输入层的话,H就是X
- σ是非线性激活函数
我们先不用考虑为什么要这样去设计一个公式。我们现在只用知道:
这个部分,是可以事先算好的,因为D波浪由A计算而来,而A是我们的输入之一。
所以对于不需要去了解数学原理、只想应用GCN来解决实际问题的人来说,你只用知道:哦,这个GCN设计了一个牛逼的公式,用这个公式就可以很好地提取图的特征。这就够了,毕竟不是什么事情都需要知道内部原理,这是根据需求决定的。
为了直观理解,我们用论文中的一幅图:
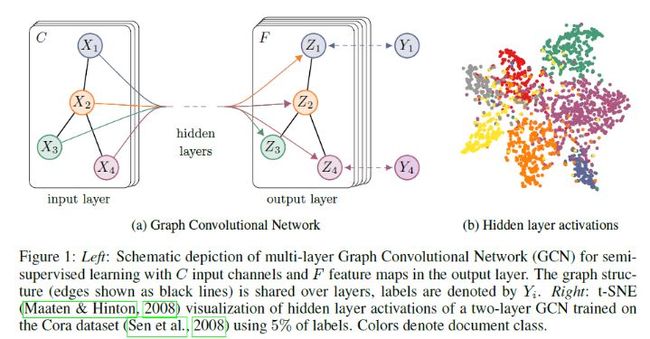
上图中的GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但是,无论中间有多少层,node之间的连接关系,即A,都是共享的。
假设我们构造一个两层的GCN,激活函数分别采用ReLU和Softmax,则整体的正向传播的公式为:
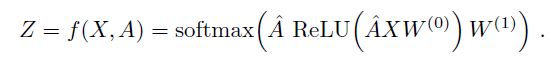
最后,我们针对所有带标签的节点计算cross entropy损失函数:
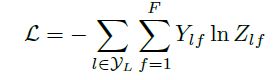
就可以训练一个node classification的模型了。由于即使只有很少的node有标签也能训练,作者称他们的方法为半监督分类。
当然,你也可以用这个方法去做graph classification、link prediction,只是把损失函数给变化一下即可。
三、GCN 为什么是这个样子
我前后翻看了很多人的解读,但是读了一圈,最让我清楚明白为什么GCN的公式是这样子的居然是作者Kipf自己的博客:http://tkipf.github.io/graph-convolutional-networks/ 推荐大家一读。
作者给出了一个由简入繁的过程来解释:
我们的每一层GCN的输入都是邻接矩阵A和node的特征H,那么我们直接做一个内积,再乘一个参数矩阵W,然后激活一下,就相当于一个简单的神经网络层嘛,是不是也可以呢?
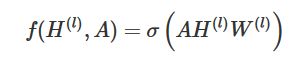
实验证明,即使就这么简单的神经网络层,就已经很强大了。这个简单模型应该大家都能理解吧,这就是正常的神经网络操作。
但是这个简单模型有几个局限性:
- 只使用A的话,由于A的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算一个node的所有邻居的特征的加权和,该node自己的特征却被忽略了。因此,我们可以做一个小小的改动,给A加上一个单位矩阵 I ,这样就让对角线元素变成1了。
- A是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以我们对A做一个标准化处理。首先让A的每一行加起来为1,我们可以乘以一个D的逆,D就是度矩阵。我们可以进一步把D的拆开与A相乘,得到一个对称且归一化的矩阵 :。
通过对上面两个局限的改进,我们便得到了最终的层特征传播公式:
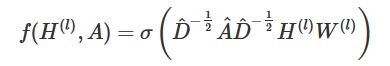
其中
公式中的与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。原论文中给出了完整的从谱卷积到GCN的一步步推导,我是看不下去的,大家有兴趣可以自行阅读。
。
四、GCN 有多牛
在看了上面的公式以及训练方法之后,我并没有觉得GCN有多么特别,无非就是一个设计巧妙的公式嘛,也许我不用这么复杂的公式,多加一点训练数据或者把模型做深,也可能达到媲美的效果呢。
但是一直到我读到了论文的附录部分,我才顿时发现:GCN原来这么牛啊!
为啥呢?
因为即使不训练,完全使用随机初始化的参数W,GCN提取出来的特征就以及十分优秀了!这跟CNN不训练是完全不一样的,后者不训练是根本得不到什么有效特征的。
我们看论文原文:

然后作者做了一个实验,使用一个俱乐部会员的关系网络,使用随机初始化的GCN进行特征提取,得到各个node的embedding,然后可视化:
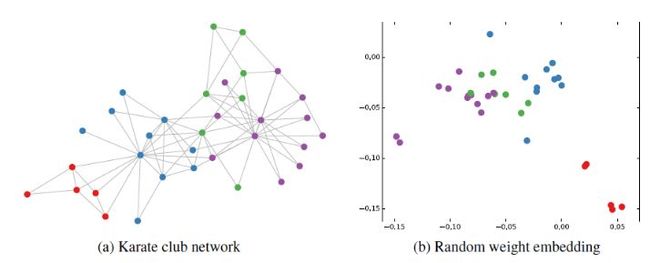
可以发现,在原数据中同类别的node,经过GCN的提取出的embedding,已经在空间上自动聚类了。
而这种聚类结果,可以和DeepWalk、node2vec这种经过复杂训练得到的node embedding的效果媲美了。
说的夸张一点,比赛还没开始,GCN就已经在终点了。看到这里我不禁猛拍大腿打呼:“NB!”
还没训练就已经效果这么好,那给少量的标注信息,GCN的效果就会更加出色。
作者接着给每一类的node,提供仅仅一个标注样本,然后去训练,得到的可视化效果如下:
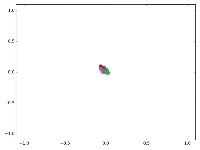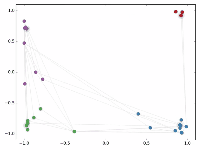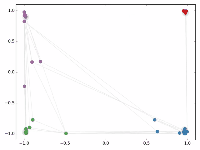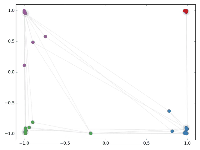
这是整片论文让我印象最深刻的地方。
看到这里,我觉得,以后有机会,确实得详细地吧GCN背后的数学琢磨琢磨,其中的玄妙之处究竟为何,其物理本质为何。这个时候,回忆起在知乎上看到的各路大神从各种角度解读GCN,例如从热量传播的角度,从一个群体中每个人的工资的角度,生动形象地解释。这一刻,历来痛恨数学的我,我感受到了一丝数学之美,于是凌晨两点的我,打开了天猫,下单了一本正版《数学之美》。哦,数学啊,你真如一朵美丽的玫瑰,每次被你的美所吸引,都要深深受到刺痛,我何时才能懂得你、拥有你?
其他关于GCN的点滴:
- 对于很多网络,我们可能没有节点的特征,这个时候可以使用GCN吗?答案是可以的,如论文中作者对那个俱乐部网络,采用的方法就是用单位矩阵 I 替换特征矩阵 X。
- 我没有任何的节点类别的标注,或者什么其他的标注信息,可以使用GCN吗?当然,就如前面讲的,不训练的GCN,也可以用来提取graph embedding,而且效果还不错。
- GCN网络的层数多少比较好?论文的作者做过GCN网络深度的对比研究,在他们的实验中发现,GCN层数不宜多,2-3层的效果就很好了。
转自博文:https://www.sohu.com/a/342634291_651893