论文笔记:Bag of Tricks for Long-Tailed Visual Recognition with Deep Convolutional Neural Networks

论文地址:http://www.lamda.nju.edu.cn/zhangys/papers/AAAI_tricks.pdf
代码地址:https://github.com/zhangyongshun/BagofTricks-LT
文章目录
-
- 1、动机
- 2、 Dataset
-
- 2.1、 Long-tailed CIFAR(CIFAR10、CIFAR100)
- 2.2 iNaturalist 2018
- 2.3 ImageNet-LT
- 3、Tricks gallery
-
- 3.1 Re-weighting
- 3.2 Re-sampling
- 3.3 Mixup Training
- 4、Two-stage training
- 5、Trick combinations
作者对于现有的对于long-tailed visual recognition中的tricks做了系统性的实验。
- 通过大量的实验来验证哪些tricks组合到一起能提升精度,哪些却不能(论文更偏向于实验性报告,对于一些实验结果作者并没有详细说明其中的原因)
- 作者发现了Mixup对于long-tailed 分类任务方面效果很好,尤其是先在input的时候做Mixup然后再在训练完成之后进行fine-tuning.
- 作者基于CAM提出了一种新的数据增广方式:CAM-based,并证实了其和class-balance sampling组合到一起效果最好。
1、动机
作者先表明metric learning、meta learning和knowledge transfer在long-tailed任务上已经取得了成功,但仍然存在几大问题。
-
现有的一些方法在训练时对于超参数很敏感
-
训练的过程很复杂
-
在真实场景下使用这些tricks实际上很难。
不同的tricks单独使用效果好,但是混合起来使用效果不一定会更好,有的甚至可能会更差。原因是其实有很多的tricks起到的作用相似,比如re-sampling和re-weighting都是让模型对于tailed classes更加注意,重叠到一起使用后可能会造成tailed classes的过拟合。
2、 Dataset
2.1、 Long-tailed CIFAR(CIFAR10、CIFAR100)
1、采样方式使用函数 n = n t ∗ μ t n=n_t*\mu^t n=nt∗μt 其中 t t t为类别的下标(从0开始), μ ∈ ( 0 , 1 ) \mu\in(0,1) μ∈(0,1), n t n_t nt是原始的训练图片数量, i m b a l a n c e f a c t o r = n l a r g e s t n s m a l l e s t imbalance factor=\frac{n_{largest}}{n_{smallest}} imbalancefactor=nsmallestnlargest其值可以取到 10 ∼ 200 10\sim200 10∼200实验一般选择50和100。
2、Preprocessing :
train:
- 在每条边填充4 pixels
- 随机裁减32*32区域
- 0.5概率随机翻转
- normalization
val:
- 保证图片长宽比的情况下将短的边resize到36 pixels
- 中心裁减32*32区间大小
- normalization
3、 backbone: ResNet-32
4、training details:
-
batchsize:128
-
epoch:200
-
optimizer:momentum: 0.9
-
weight decay: 2 ∗ 1 0 − 4 2*10^{-4} 2∗10−4
-
learning rate scheduler: warmup (前5个epoch)+stepdecay(epoch到160和180时lr下降100倍)
2.2 iNaturalist 2018
1、这篇文章在iNaturalist2018的train和val上做的实验
2、Preprocessing:
train:
-
use scale and aspect ratio data augmentation(Szegedy et al 2015)
-
224*224的随机裁减
-
随机翻转
-
normalization
val:
- 保证图片长宽比的情况下将短的边resize到256 pixels
- 中心裁减224*224
- normalization
3、backbone:ResNet-50
4、training details:
- batchsize:512
- epoch:90
- optimizer:momentum:0.9
- weight decay: 1 ∗ 1 0 − 4 1*10^{-4} 1∗10−4
- learning rate scheduler:stepdecay(epoch到30、60、80下降10倍)
2.3 ImageNet-LT
1、(Liu19cvpr)用Pareto distribution在原本的ImageNet上面采样得到,1000类别,每类别 5 ∼ 1280 5\sim1280 5∼1280,共19K训练集
2、Preprocess:同iNaturelist2018
3、backbone:ResNet-10
3、training details:同iNaturalist2018
3、Tricks gallery
3.1 Re-weighting
给尾部类更多的权重,让模型更加关注尾部类的表达。
参数说明:
c ∈ 1 , 2 , ⋯ , C c\in{1,2,\cdots, C} c∈1,2,⋯,C:图片类别
z = [ z 1 , z 2 , ⋯ , z C ] z=[z_1, z_2, \cdots, z_C] z=[z1,z2,⋯,zC]:预测输出
C:类别总数
n m i n n_{min} nmin:样本数量最少的类别
n c n_c nc:c类别训练图片数量
1、CE(cross entropy loss):

2、CS_CE(Cost-sensitive softmax cross-entropy loss)

3、Focal loss


其中 p i = s i g m o i d ( z i ) = 1 1 + e z i p_i=sigmoid(z_i)=\frac{1}{1+e^{z_i}} pi=sigmoid(zi)=1+ezi1
4、CB_Focal(Classi-balanced loss)

实验数据:

参照原loss原论文超参数设置,在CIFAR-10-LT上奏效,但是在CIFAR-100-LT上表现不好,实验结论是:在不同的数据集上直接使用re-weighting不work
3.2 Re-sampling
通过对实验数据重新采样,来得到均匀分布的数据集,论文中用到的方法有:
1、Random over-sampling:增加对于尾部类的采样,但是可能造成尾部类的过拟合
2、Random under-sampling:减少对于头部类采用,构造平衡数据集。
3、Class-balanced sampling:通过公式:

计算采样概率。(选择一个类别,再随机选择里面的样本)。
4、Square-root sampling:将公式(7)中的q取 1 2 \frac{1}{2} 21,来采样一个更加平衡的数据集
5、Progressively-balanced sampling:在训练的过程中不断调整采样概率。
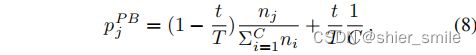
t:为当前的epoch数, T全部epoch数。
(4,5,6都来自于论文:DECOUPLING REPRESENTATION AND CLASSIFIERFOR LONG-TAILED RECOGNITION有兴趣的可以去看看)
实验数据:

实验结论:直接使用re-sampling能带来轻微的提升。
ps:从这个实验结果来看,在CIFAR-10-LT上,只有Class-balance sampling带来了轻微提升,而在CIFAR-100-LT上却只有Progressive-balance sampling有提升。感觉比较玄学,作者也并未给出理由,不知道是不是为了对比实验,超参数的设置原因导致的,只能具体做完实验后才能得出判断。(后补)
3.3 Mixup Training
作者对两种Mixup在long-tailed 数据集上进行实验,并和fine-tuning进行结合做了实验。
1、Input Mixup
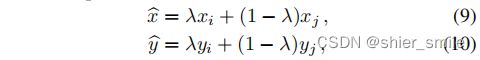
作者只在训练阶段使用了Mixup,通过将两张图片之间进行线性插值的方式来减缓CNN的对抗性干扰。
2、Manifold mixup
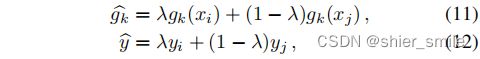
(通过对网络中间层的输出做mixup)
3、fine-tuning
论文:Rethinking the distribution gap between clean and augmented data中表明:先使用mixup训练好模型后,再去掉mixup继续训练几个epoch,能让精度上升。
实验结果:


实验结论:
1、Input mixup和maniflod mixup都能带来提升,具体在不同的部分使用Mixup产生不同的结果,当 α \alpha α取1, 在pooling层做mixup时效果最好,需要和其他的trick做更多的实验。
2、在Input Mixup后使用fine-tuning能带来提升,但是对于Manifold mixup却使结果变差
ps:对于这两个两个实验结果,作者并未给出理由。
4、Two-stage training
两阶段训练就是先进行imbalance training 然后再使用balance training 进行fine-tuning。作者做了(deferred re-balancing by re-sampling)DRS和(deferred re-balancing by re-weighting)DRW两部分实验。并且作者提出了一种基于CAM的图像增广方式。先通过imbalance training后的模型对原图片进行预测得到class acivate map,然后将模型关注的区域提取出来,更换不同的背景(这里的背景图会先进行背景图片增强)后进行其他的数据增广来得到一张新的图片。
ps: 这里更换不同的背景,是指对这张图片本身的背景进行增强之后再把前景图片贴上去。(背景增广的方式有:1、rotate and scale, 2、translate, 3、horizontal filp)

作者对CAM-based+re-sampling和DRW进行了实验。


CAM-based+Class-balanced sampling效果最好,而DRW中CS_CE效果最好。
5、Trick combinations
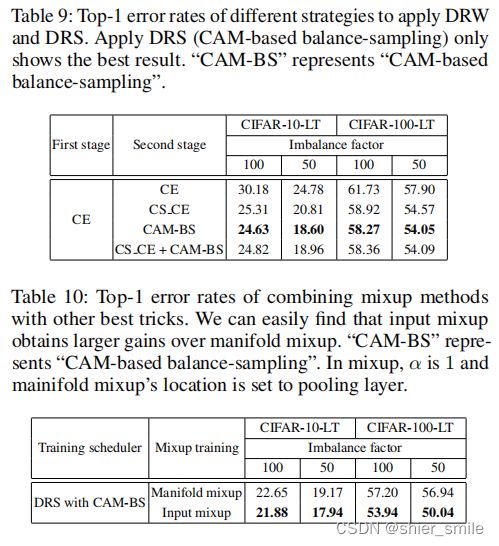
1、作者将表7和表8中表现最好的两个Trick(CS_CE和CAM-BS)组合到一起,却发现效果反而变差了一些,作者说原因是CS_CE和Class-balance sampling都是让模型更注重与尾部类的表达导致了尾部类的过拟合。
2、将Input mixup和manifold mixup组合后Input mixup效果比manifolde mixup好
ps: 1、从表9和表10中可以发现,使用了Manifold mixup之后对于imbalance factor=100的情况变好了。但是对于imbalance factor=50的情况变差了。挺好奇这里原因是什么
最后一个表:
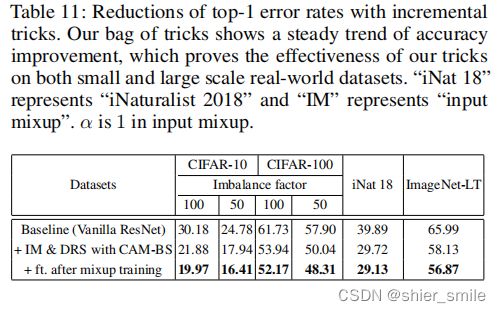
作者将Input Mixup和DRS+CAM-BS+fine-tuning进行组合达到了最好的效果。
总体效果:

作者没有给CAM-base单独做实验,感觉可以去试一下单独用CAM-base做实验效果如何。
以上ps的地方为个人看法,如有错误请指出,非常感谢。
ps:本贴写于2022-8-04, 未经本人允许,禁止转载。