专注嵌入式设备:轻量化神经网络mobilenet全系列
为了追求更高的准确率,自从AlexNet以来,神经网络更加倾向于更深、更复杂的设计结构,这就导致对GPU的需求提高,在现实生活中很难达到,因为在实际生活中,识别任务更需要是在有限的计算环境下实时计算(基本都是在移动端)。
因此,谷歌团队在2017年提出了专注于移动端或嵌入式设备中的轻量级神经网络-MobileNet,到如今已发展了三个版本。
1、MobileNet_V1
MobileNet的基本单元是深度可分离卷积,它是将标准卷积拆解为深度卷积(depthwise convolution) 和逐点卷积(pointwise convolution)。
标准卷积的卷积核是作用在所有输入通道上,而深度卷积是针对每个输入通道采用不同的卷积核,即一个卷积核对应一个通道,而点卷积其实就是普通的卷积,只不过是采用1x1的卷积核, 如图1所示,下面对比一下各自的计算量。
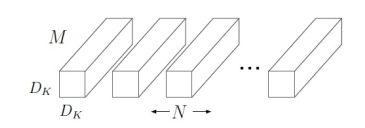
(a) 标准卷积
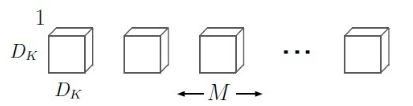
(b) 深度卷积
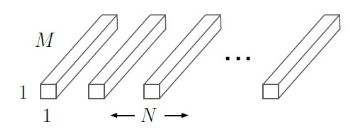
(c) 点卷积
图1 标准卷积与深度可分离卷积计算对比
令输入尺寸为DFxDFxM,标准卷积核的尺寸为DKxDKxMxN,若采用标准卷积进行操作,步长为1且存在padding,则计算量为DKxDKxMxNxDFxDF。
采用深度卷积的方式进行卷积,先使用 M个深度卷积核对输入的M个通道分别进行卷积得到的尺寸为 DF x DF x M,这一步的计算量为 DK x DK x M x DF x DF;
再使用N个 1 x 1 x M的卷积核进行逐点卷积得到输出尺寸为 DF x DF x M x N,这一步的计算量为 M x N x DF x DF;故总的计算量为 DK x DK x M x DF x DF + M x N x DF x DF。所以深度可分离卷积与标准卷积相比得:
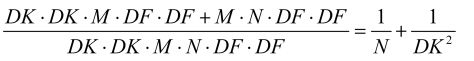
一般情况下,N取值较大,若采用常用的3x3卷积核,则深度可分离卷积的计算量则是标准卷积的九分之一。
在实际使用深度可分离卷积时,会添加BN层和RELU层(RELU6),其对比结果如图2所示。

(a)带RELU的标准卷积 (b)带BN和RELU的深度可分离卷积
图2 标准卷积与深度可分离卷积机构对比
最终MobileNet_V1的网络结构如图3所示。一共是28层(不包括平均池化层和全连接层,且把深度卷积和逐点卷积分开算),除了第一层采用的是标准卷积核之外,剩下的都是深度可分离卷积层。
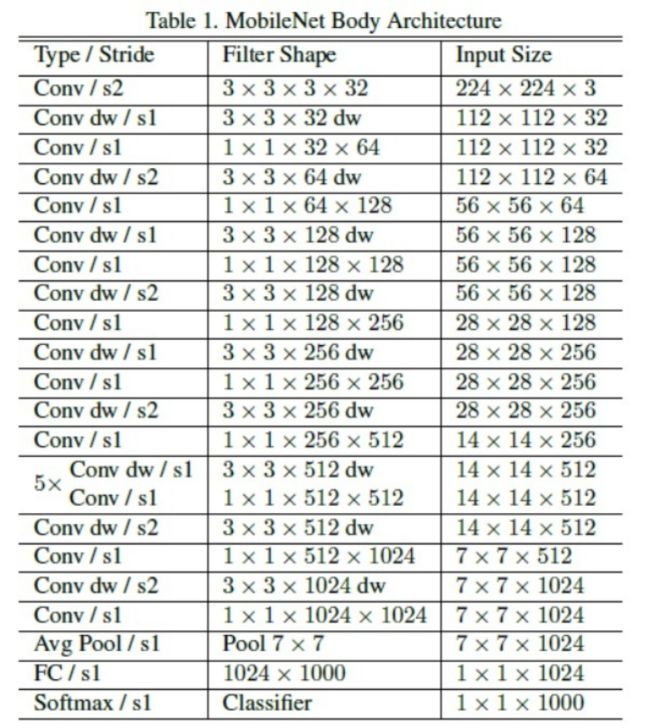
图3 MobileNet_V1网络结构
虽然MobileNet_V1的延迟已经比较小了,但更多时候在特定应用下需要更小更快的模型,因此引入了宽度因子,作用是在每层均匀地稀疏网络,为每层通道乘以一定的比例,从而减少各层的通道数,常用值有1、0.75、0.5、0.25。
引入的第二个超参数是分辨率因子,用于控制输入和内部层表示,即控制输入的分辨率,常在(0,1]之间。
值得注意的是,计算量量减少程度与未使用宽度因子之前提高了1/(**2 xρx ρ)倍,参数量没有影响。最终实验结果证明在尺寸、计算量和速度上比许多先进模型都要优秀。
2、MobileNet_V2
MobileNet_V2发表于2018年,是在MobileNet_V1的基础上引入了倒置残差连接和线性瓶颈模块。
残差结构是先用1× 1的卷积实现降维,然后通过3 × 3卷积,最后用 1 × 1 卷积实现升维,即两头大中间小。在MobileNet_V2 中,则是将降维和升维的顺序进行了调换,且中间为3 × 3 深度可分离卷积,即两头小中间大。对比图如图4所示。
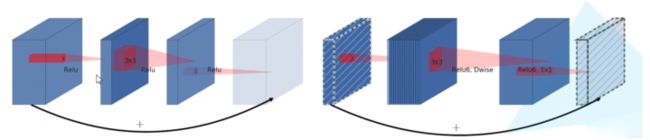
(a)残差结构 (b)倒置残差结构
图4 残差与倒置残差结构对比图
那为什么会先升维再降维呢?这是因为倒置残差结构包含深度可分离卷积外,还使用了Expansion layer和 Projection layer。先通过1 × 1 卷积的Expansion layer将低维空间映射到高维空间,之后在用深度可分离卷积来提取特征,然后使用1 × 1卷积的Projection layer把高维特征映射到低维空间进行压缩数据,让网络从新变小。
这里的Expansion layer 和 Projection layer 都是有可以学习的参数,所以整个网络结构可以学习到如何更好的扩展数据和重新压缩数据。
还有一个是线性瓶颈块(linear bottleneck),这是由于当输入一个二维矩阵时,采用不同的矩阵T把它进行升维到更高的维度上,使用激活函数ReLU, 然后再使用T 的逆矩阵对其进行还原。
结果发现,当T的维度为2或者3时,还原回来的特征矩阵会丢失很多信息,但随着维度的增加,丢失的信息越来越少。
可见,ReLU 激活函数对低维特征信息会造成大量损失,所以在倒置残差块最后输出低维特征的激活函数是线性激活函数,同时实验证明,使用 linear bottleneck 可以防止非线性破坏太多信息。整体网络结构如图5所示。

图5 MobileNet_V2网络结构
图5中t表示1 × 1卷积的升维倍率,c是输出特征矩阵的通道数,n表示倒置残差块结构重复的次数,s表示步距。最终实验表明,参数量仅为3.4M,CPU上预测一张图不到0.1秒,几乎是实时!
3、MobileNet_V3
MobileNet_V3发布于2019年,依旧结合了V1的深度可分离卷积、V2的倒置残差和线性瓶颈层,同时采用了注意力机制,利用神经结构搜索进行网络的配置和参数。
V3分为两个版本,分别为MobileNet_V3 Large和MobileNet_V3 Small,分别适用于对资源不同要求的情况。
首先对于模型结构的探索和优化来说,网络搜索是强大的工具。研究人员首先使用了神经网络搜索功能来构建全局的网络结构,随后利用了NetAdapt算法来对每层的核数量进行优化。
对于全局的网络结构搜索,研究人员使用了与Mnasnet中相同的,基于RNN的控制器和分级的搜索空间,并针对特定的硬件平台进行精度-延时平衡优化,在目标延时(~80ms)范围内进行搜索。
随后利用NetAdapt方法来对每一层按照序列的方式进行调优。在尽量优化模型延时的同时保持精度,减小扩充层和每一层中瓶颈的大小。
其次在MobileNet_V3引入了压缩-激励(Squeeze-and-Excitation, SE)注意力结构,如图所示。SE结构通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
将SE结构加入核心结构中,作为搜索空间的一部分,得到了更稳定的结构。虽然SE结构会消耗一定的时间,但作者将expansion layer的通道数变为原来的1/4,这样即提高了精度也没有增加时间消耗。
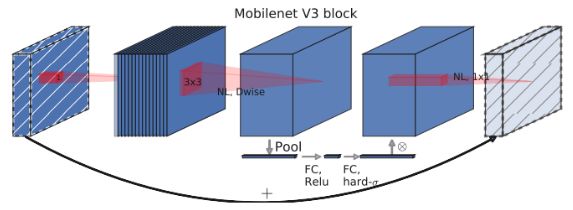
图5 添加SE注意力的倒置残差块
对于尾部结构,原先的V2在平均池化之前存在一个1x1的卷积层,目的是提高特征图的维度,但这带来了一定的计算量,但在V3中,作者为了降低计算量,池化后再接上1x1卷积,同时去掉了原中间3x3和1x1卷积,最终发现精度并没有损失,时间降低了大约15ms。
最后对于激活函数的改进,作者发现swish激活函数能够有效提高网络的精度,但swish的计算量太大了,因此提出h-swish激活函数:
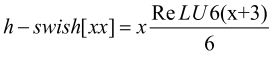
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。这一非线性改变将模型的延时增加了15%。
但它带来的网络效应对于精度和延时具有正向促进,剩下的开销可以通过融合非线性与先前层来消除。
最终MobileNet_V3结构如图6所示。

(a) MobileNet_V3 Large (b) MobileNet_V3 Small
图6 MobileNet_V3网络结构
图6中exp size表示倒置残差结构的通道数,out表示输入到线性瓶颈时特征层的通道数。SE表示是否引入注意力机制,NL表示激活函数种类(HS表示h-swish,RE表示RELU),s表示步长。
最终实验结果表明MobileNetV3-Large在ImageNet分类上的准确度与MobileNetV2相比提高了3.2%,同时延迟降低了15%。
4、参考文献
[1] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861, 2017.
[2] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
[3] Howard A, Sandler M, Chen B, et al. Searching for MobileNetV3[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2020.
[4] https://zhuanlan.zhihu.com/p/58554116
来源公众号:深蓝前沿教育
阅读至此了,分享、点赞、在看三选一吧