神经网络学习笔记
最近在学习一门深度学习与机器视觉的专业课,感觉自己的深度学习的基础很是不牢固,所以打算从最简单的神经网络整理一下知识
在B站发现了一个神经网络可视化的视频,很nice,推荐给大家神经网络可视化
这篇文章很是实用《深度学习》课程总结-深度学习的实用层面
在这里记录一下有关epoch、iteration、batch_size的概念
- batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
- iteration:1个iteration等于使用batchsize个样本训练一次;
- epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子,我现在训练集有1840个样本,设置batchsize=8,iteration=4000
那么:等我训练到第230个iteration时,就是一个epoch,一共有17个epoch
当然也可以直接设置epoch个数而不是迭代轮数
神经网络学习笔记
• 机器学习(Machine Learning,ML):是人工智能研究的一部分,研究计算机智能体如何根据经验或数据改善其感知、知识、思维或行动。为此,ML借鉴了计算机科学、统计学、心理学、神经科学、经济学和控制理论。
• 监督学习(supervised learning):计算机学会预测人类给定的标签;
• 无监督学习(unsupervised learning):不需要标签,有时会自己做预测任务;
• 强化学习(reinforcement learning):让一个主体学习动作序列,以优化其总回报
一、BP for NN
二、From NN to CNN
全连接 =》 空间信息丢失
巨量参数 =》 过拟合(overfitting)
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
三、卷积神经网络CNN
通常包含卷积层(convolution)、池化层(pooling)、全连接层(fully connected)、输出层(output)
1.卷积层——提取图像特征
滤波器(卷积核):如k×k×3 分别为width×height×channel/depth,滤波器通道数一般与图像通道数一致
- 大小,也可以简单理解为边长。滤波器越大,过滤后得到的图像特征就越模糊,或者说是得到的越小。
- 步长,也就是每次移动的格数。
- 个数,也就是通道数或者深度。比如彩色照片,可以理解为能过滤成红黄蓝三基色的三层图片的叠加。
卷积:
- 多个滤波器(filter)与图像卷积
- 滤波器在图像上滑动,滤波器与图像对应像素相乘,输出特征图
- 不同滤波器能够生成不同特征图
激活函数:
CNN基础——激活函数
- 激活函数对模型学习、理解非常复杂和非线性的函数具有重要作用。
- 激活函数可以引入非线性因素。如果不使用激活函数,则输出信号仅是一个简单的线性函数。线性函数一个一级多项式,线性方程的复杂度有限,从数据中学习复杂函数映射的能力很小。没有激活函数,神经网络将无法学习和模拟其他复杂类型的数据,例如图像、视频、音频、语音等。
- 激活函数可以把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。

Summary
- 输入特征图 W1 × H1 × D1
- 滤波器超参
滤波器个数:K, 滤波器大小:F, 滤波器步长:S
特征图填充:P
滤波器参数初始化方法、填充方法 - 输出特征图 W2 × H2 × D2
W2 = (W1 − F + 2P)/S + 1
H2 = (H1 − F + 2P)/S + 1
D2 = K - 滤波器训练参数个数:F × F × D1 × K + K
卷积层滤波器常用设置:
- 滤波器大小:F={3, 5, 1, 7, …} ;
- 滤波器步长:stride=1 ;
- 填充大小:P=(F-1)/2
- 输出特征图大小:(N+2P-F)/stride+1
- 输出特征图通道数:滤波器个数(K)
2.池化层——降维、防止过拟合
在激活之后进行,池化不是必选项
缩小卷积后依然很大的图片,同时保留图片主要特征。
池化类型也有很多种,比如说最大池化,最小池化,平均池化等。
3.全连接层——输出结果
4.CNN Summary
- 神经网络
==》减少参数
==》保持空间信息 - 卷积神经网络(CNN)通常包含卷积层(Conv),池化层(Pooling)以及全连接层(Fully Connected,FC)
- 典型的CNN网络结构
[(Conv) * N + Pooling] * M + FC * L + SoftMax
N < 5, M > 3, 0 ≤ L ≤ 2 - CNN倾向使用更小的滤波器、更深的网络结构
- CNN倾向减少Pooling及FC层(仅使用Conv层)
- CNN倾向使用更多Skip-Connection
四、CNN Models
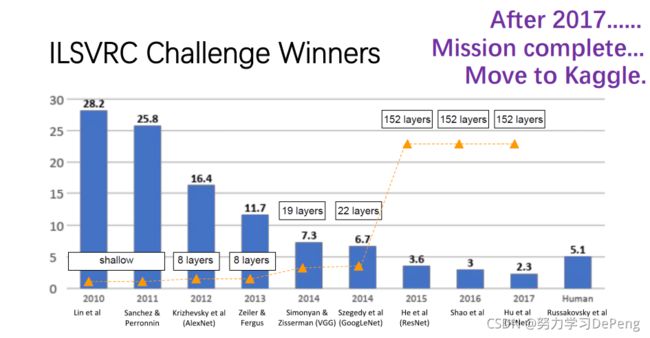
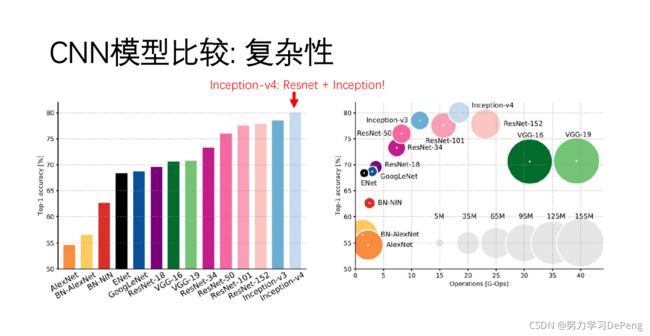
1.AlexNet:在视觉任务中第一个成功的CNN网络模型
深度学习卷积神经网络-AlexNet
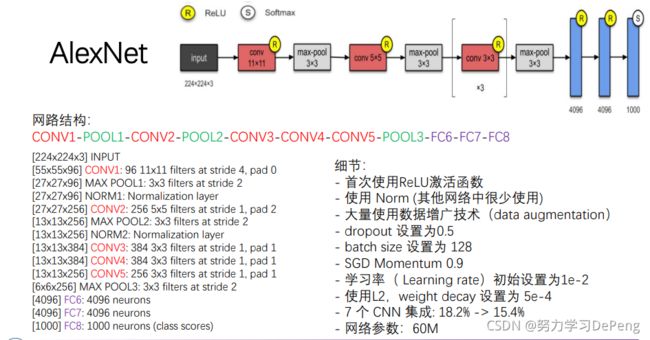
1.1 网络结构

非线性ReLU函数、多GPU训练、局部响应归一化(Local Response Normalization,LRN)、重叠池化(Overlapping Pooling)
1.2 减少过拟合
- Data Augmentation(数据增量)——镜像反射和随机剪裁、改变训练样本RGB通道的强度值
- Dropout正则化(随机失活)
2.ZFNet、VGG:复杂模型可以实现更高的性能
ZFNet使用与AlexNet相似的网络结构,区别:
- Conv1:滤波器大小11x11,步长4==》7x7,步长2
- Conv3,4,5:滤波器数目384,384,256 ==》512, 1024,512
- 单GPU实现 ==》 特征图 plus
VGG
一文读懂VGG网络
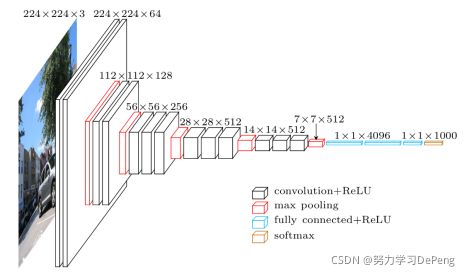
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5),例如使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
3.GoogLeNet:大量1x1卷积(通道融合)、全局池化代替FC
深入理解GoogLeNet结构(原创)

inception模块的基本机构如下图,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。这样输出的特征图就是由各滤波器输出的特征图叠加构成,是一种并行、多尺度(感知域)的特征提取与融合。
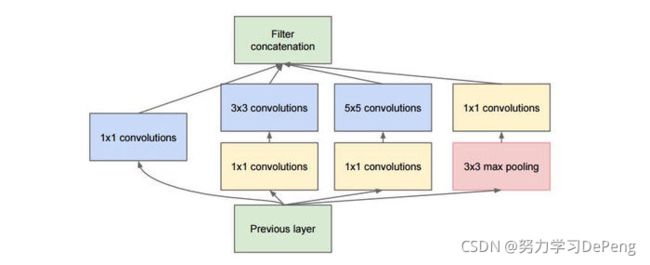
4.ResNet:实现更深的网络训练(只受GPU内存约束)
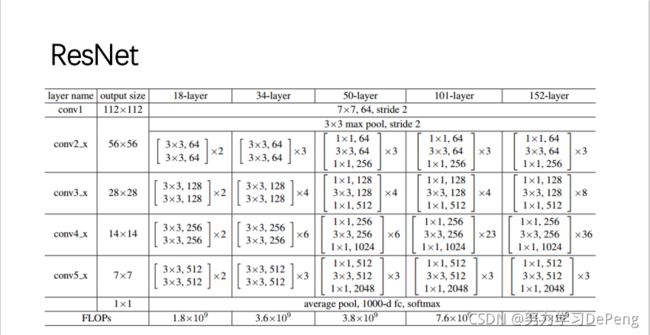
你必须要知道CNN模型:ResNet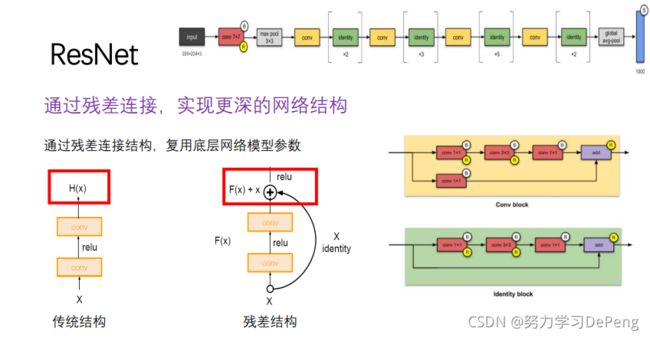
网络训练细节:
- 每个卷积层后使用Batch Normalization
- MSRA初始化
- SGD+Momentum(0.9)
- 初始Learning rate 0.1,手动调节0.1(loss平稳)
- Batch size 256
- Weight decay 1e-5
- 无dropout (无全连接)
- 网络模型参数26M(ResNet-50)
手写pytorch实现ResNet网络
import torch
import torch.nn as nn
import torch.nn.functional as f
# 定义一个保留输入的模块
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
# 定义残差模块ResBlock
class ResBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResBlock, self).__init__()
# 定义残差块内连续的2个卷积层
'''
class torch.nn.Sequential(* args) 一个时序容器。Modules 会以他们传入的顺序被添加到容器中
class torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True) 在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1;在验证时,训练求得的均值/方差将用于标准化验证数据
'''
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
if stride != 1 or inchannel != outchannel:
# shortcut,这里为了跟2个卷积层的结果结构一致,要做处理
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.left(x)
# 将2个卷积层的输出跟处理过的x相加,实现ResNet的基本结构
out = out + self.shortcut(x)
out = f.relu(out)
return out
class ResNet18(nn.Module):
"""
class torch.nn.Module 所有神经网络模块的基类
"""
def __init__(self, inchannel=64, numberclass=10):
super(ResNet18, self).__init__()
self.inchannel = inchannel
# stem layers 因为使用的是cifar10数据集,所以第一层7*7改为了3*3卷积核
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=inchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(inchannel),
nn.ReLU()
)
# blocks
self.layer1 = self.makelayer(64, 2, stride=1)
self.layer2 = self.makelayer(128, 2, stride=2)
self.layer3 = self.makelayer(256, 2, stride=2)
self.layer4 = self.makelayer(512, 2, stride=2)
# head layers
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(512, numberclass)
def makelayer(self, outchannel, num_blocks, stride):
layers = []
layers.append(ResBlock(self.inchannel, outchannel, stride))
self.inchannel = outchannel
for i in range(1, num_blocks):
layers.append(ResBlock(self.inchannel, outchannel, stride))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
print(out.shape) #查看torch.Tensor的维度
out = self.layer1(out)
print(out.shape)
out = self.layer2(out)
print(out.shape)
out = self.layer3(out)
print(out.shape)
out = self.layer4(out)
print(out.shape)
out = self.avgpool(out) #只需要给定输出特征图的大小就好,其中通道数前后不发生变化,其实这里可省去
print(out.shape)
out = out.flatten(1) # & out = out.view(-1, 512)
print(out.shape)
out = self.fc(out)
return out
def main():
model = ResNet18()
# print(model)
'''
torch.randn(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
返回一个符合均值为0,方差为1的正态分布(标准正态分布)中填充随机数的张量
'''
x = torch.randn([4, 3, 32, 32]) # 生成一个[batch, channel, height, width]的张量
out = model(x)
print('输出Tensor维度:', out.shape)
if __name__ == '__main__':
main()
