目标跟踪——End-to-end Flow Correlation Tracking with Spatial-temporal Attention
FlowTrack CVPR2018
- Abstract
- End-to-end flow correlation tracking
-
- Training network architecture
- Correlation filters layer
- Aggregation using optical flow
- Spatial-temporal attention
-
- 空间注意
- 时间注意
- Online Tracking
-
- Tracking network architecture
- Model updating
- Scales
- Experiments
Abstract
具有深度卷积特征的判别相关滤波器(DCF)在最近的跟踪基准测试中取得了良好的性能。然而,现有的DCF跟踪器只考虑当前帧的外观特征,很难从运动和帧间信息中获益。时间信息的缺乏降低了在部分遮挡和变形等挑战中的跟踪性能。本文提出了流道算法,旨在利用连续帧中丰富的流信息来提高特征表示和跟踪精度。流迹将单独的组件,包括光流估计、特征提取、聚合和相关滤波器跟踪作为网络中的特殊层。据我们所知,这是第一个在深度学习框架中联合训练流和跟踪任务的工作。然后,通过流动的引导,将历史特征图与当前特征图进行扭曲和聚合。对于自适应聚合,我们提出了一种新的时空注意机制。在实验中,该方法在OTB2013、OTB2015、VOT2015和VOT2016上均取得了领先的性能。
End-to-end flow correlation tracking
在本节中,首先给出了流相关网络来描述整体的训练体系结构。然后介绍了相关滤波器层和光流的聚合问题。为了在每个空间位置和时间通道上对聚合帧进行自适应加权,设计了一种新的时空注意机制。最后,描述了由模型更新和尺度组成的在线跟踪。
Training network architecture
我们的跟踪器的整体训练框架包括特征网(特征提取子网络)、FlowNet[10]、warping模块、时空注意模块和CF跟踪层。如图2所示,整体培训架构采用了由历史和当前分支组成的Siamese network。在历史分支中,FeatureNet 和 FlowNet首先提取外观特征和流信息。然后,在流信息的引导下,将之前的帧以预定义的间隔(实验中为5帧,t=6)warp到t−1帧。同时,设计了一个时空注意模块来对warp的特征图进行加权。在另一个分支中,利用特征网提取了当前帧的特征图。最后,将这两个分支都输入到后续的相关滤波器层中进行训练。所有模块都是可区分的,训练端到端。

简而言之:作者用了Siamese的网络,分为历史帧和当前帧t,上面的蓝色part是histroical branch(历史分支),前若干帧 i i i都和 t − 1 t-1 t−1帧做光流,然后用光流warp第 i i i帧的feature,最后把这些warp之后的特征merge到一起,得到一个比较好的特征,然后再将t-1帧到t-T帧得到的warp特征过一个Spatial-Temporal网络相融合,得到 ϕ ( x ) \phi(x) ϕ(x),再与当前帧t过了FeatureNet的 ϕ ( z ) \phi(z) ϕ(z)做一个相关操作,得到最终的响应图。
注:warp不晓得咋翻译个人觉得是特征对齐的意思
Correlation filters layer
具有深度卷积特征的鉴别相关滤波器(DCF)在最近的基准测试[25,32,5]中显示出了良好的性能。然而,所选择的CNN特征总是在不同的任务中被预先训练,并且在跟踪系统中的单个组件中被单独学习,因此所获得的跟踪结果可能是次最优的。最近,CFNet[37]和DCFNet[40]将相关滤波器解释为Siamese framework中的一个可微层,从而执行端到端表示学习。
在DCF跟踪框架中,目的是从训练样本 ( x k , y k ) k = 1 : t (\mathbf x_k, \mathbf y_k)_{k=1:t} (xk,yk)k=1:t中学习一系列卷积滤波器f,每个样本都使用特征网络从图像区域提取。假设样本的空间大小为 M × N M×N M×N,输出的空间大小为 m × n ( m = M / s t r i d e M , n = N / s t r i d e N ) m×n(m=M/stride_M,n=N/stride_N) m×n(m=M/strideM,n=N/strideN)。所需的输出 y k \mathbf{y_k} yk是一个响应映射,其中包含示例 x k \mathbf{x_k} xk中每个位置的目标分数。滤波器对样本 x \mathbf x x的响应为
R ( x ) = ∑ l = 1 d ϕ l ( x ) ∗ f l (1) R(\mathbf x)=\sum_{l=1}^{d}\phi^l(\mathbf x)*f^l \tag{1} R(x)=l=1∑dϕl(x)∗fl(1)∗表示循环相关操作。滤波器可以通过在样本 x k \mathbf{x_k} xk上的响应 R ( x k ) R(\mathbf{x_k}) R(xk)和相应的高斯标签 y k \mathbf{y_k} yk之间获得的最小化误差来训练: e = ∑ k ∣ ∣ R ( x k ) − y k ∣ ∣ 2 + λ ∑ l = 1 d ∣ ∣ f l ∣ ∣ 2 (2) e=\sum_k||R(\mathbf x_k)-\mathbf{y_k}||^2+\lambda\sum_{l=1}^{d}||f^l||^2 \tag{2} e=k∑∣∣R(xk)−yk∣∣2+λl=1∑d∣∣fl∣∣2(2)上式的解可以从[6]中获得:
f l = F − 1 ( ϕ ^ l ( x ) ⊙ y ^ ∗ ∑ k = 1 D ϕ ^ k ( x ) ⊙ ( ϕ ^ k ( x ) ) ∗ + λ ) (3) \mathbf f^l=\mathcal F^{-1}(\frac{\hat \phi^l(\mathbf x)\odot \hat y^*}{\sum_{k=1}^D\hat \phi^k(\mathbf x)\odot (\hat \phi^k(\mathbf x))^*+\lambda}) \tag{3} fl=F−1(∑k=1Dϕ^k(x)⊙(ϕ^k(x))∗+λϕ^l(x)⊙y^∗)(3) 其中,帽子符号表示各变量的离散傅里叶变换F,*表示各变量的复共轭,D为信道数, ⊙ \odot ⊙表示阿达玛乘积。
在测试阶段,训练后的滤波器用于评估以预测目标位置为中心的图像片:
R ( z ) = ∑ l = 1 d ϕ l ( z ) ∗ f l (4) R(\mathbf z)=\sum_{l=1}^{d}\phi^l(\mathbf z)*f^l \tag{4} R(z)=l=1∑dϕl(z)∗fl(4)其中, ϕ ( z ) ϕ(\mathbf z) ϕ(z)表示从包括上下文在内的最后一帧的跟踪目标位置中提取的特征图。
为了统一端到端网络中的相关滤波器,我们将上述解表示为相关滤波器层。给定搜索patch ϕ ( z ) ϕ(\mathbf z) ϕ(z)的特征映射,损失函数表示为: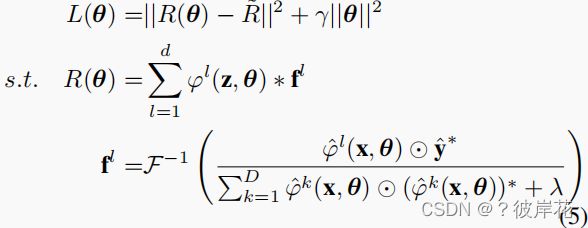
其中 R ~ \tilde R R~是期望的响应,它是一个以真实目标位置为中心的高斯分布。θ是指整个网络的参数。损失相对于 ϕ ( x ) ϕ(\mathbf x) ϕ(x)和 ϕ ( z ) ϕ(\mathbf z) ϕ(z)的反向传播被表示为[40]:
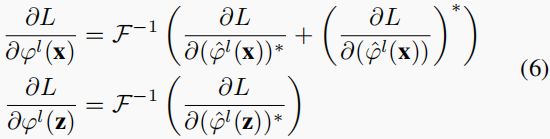
一旦导出了反向传播,相关滤波器就可以表示为网络中的一个层,在下一节中称为CF层。
Aggregation using optical flow
光流编码两个输入图像之间的对应关系。我们根据流程将特征映射从相邻帧warp到指定的帧:
ϕ i → t − 1 = W ( ϕ i , F l o w ( I i , I t − 1 ) ) (7) \phi_{i\to t-1}=\mathcal W(\phi_i,Flow(I_i,I_{t-1})) \tag{7} ϕi→t−1=W(ϕi,Flow(Ii,It−1))(7)其中, ϕ i → t − 1 \phi_{i\to t-1} ϕi→t−1表示从前一帧i扭曲到指定的t−1帧的特征映射。 F l o w ( I i , I t − 1 ) Flow(I_i,I_{t-1}) Flow(Ii,It−1)是通过光流网络[10]估计的光流场,它将一个帧i中的位置p投影到指定帧t−1中的位置 p + δ p p+δp p+δp,warping操作是通过应用于特征图中每个通道的所有位置的双线性函数来实现的。某些通道中的warping执行如下:
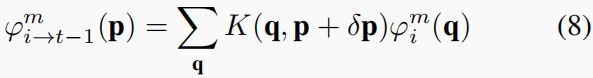
其中, p = ( p x , p y ) p=(p_x,p_y) p=(px,py)表示2D位置, δ p = F l o w ( I i , I t − 1 ) ( p ) δp=Flow(I_i,I_{t−1})(p) δp=Flow(Ii,It−1)(p)表示不同位置的流,m表示特征图 ϕ ( x ) ϕ(x) ϕ(x)中的一个通道, q = ( q x , q y ) q=(q_x,q_y) q=(qx,qy)枚举了特征图中的所有空间位置,K表示双线性插值核。
由于我们采用端到端训练, ϕ i → t − 1 ϕ_{i→t−1} ϕi→t−1相对于 ϕ i ϕ_i ϕi和flow δ p δ_p δp(即 F l o w ( I i , I t − 1 ) ( p ) Flow(I_i,I_{t−1})(p) Flow(Ii,It−1)(p))的反向传播被推导为:

一旦以前的帧中的特征映射被warping到指定的帧,它们就会为同一对象实例提供不同的信息,如不同的视点、变形和不同的照明。因此,通过聚合这些特征映射,可以增强被跟踪对象的外观特征。聚合结果如下:
ϕ ( x ) = ϕ ˉ t − 1 = ∑ i = t − T t − 1 w i → t − 1 ϕ i → t − 1 (10) \phi(x)=\bar \phi_{t-1}=\sum_{i=t-T}^{t-1}w_{i\to t-1}ϕ_{i→t−1} \tag{10} ϕ(x)=ϕˉt−1=i=t−T∑t−1wi→t−1ϕi→t−1(10)其中T是预定义区间,其中 w i → t − 1 w_{i\to t-1} wi→t−1是在不同空间位置和特征通道上的自适应权值。自适应权值由所提出的新的时空注意机制来决定,这将在下一小节中详细描述。
Spatial-temporal attention
自适应权重表示聚合帧在每个空间位置和时间通道上的重要性。对于空间定位,我们采用余弦相似度度量来度量扭曲特征与从指定的t−1帧中提取的特征之间的相似性,对于不同的通道,我们进一步引入时间注意来自适应地重新校准时间通道
空间注意
空间注意表示在不同空间位置上的不同权重。首先,一个瓶颈子网络将 ϕ ϕ ϕ投影到一个新的嵌入 ϕ e ϕ^e ϕe中,然后采用余弦相似度度量来度量扭曲特征与从指定的t−1帧中提取的特征之间的相似性:
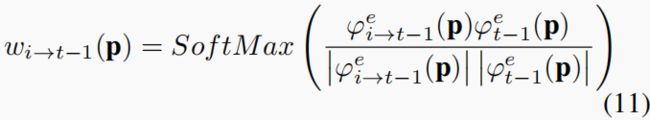
其中,在通道处应用SoftMax操作,以规范化附近帧上每个空间位置p的权重 w i → t − 1 w_{i→t−1} wi→t−1。直观地说,在空间注意中,如果扭曲的特征 ϕ i → t − 1 e ( p ) ϕ^e_{i→t−1}(p) ϕi→t−1e(p)接近于特征 ϕ t − 1 e ( p ) ϕ^e_{t−1}(p) ϕt−1e(p),则被赋予更大的权重。否则,将分配一个较小的权重。
时间注意
空间注意得到的权重 w i → t − 1 w_{i→t−1} wi→t−1在t−1帧的每个位置上的值最大,因为根据余弦测量,t−1帧与自己的权重最相似。我们进一步提出了时间注意机制,通过自适应地重新校准时间通道来解决这个问题,如图所示。空间注意输出的信道数等于聚合的帧数T,我们期望通过引入时间信息来重新加权信道的重要性

具体来说,空间注意模块的输出首先通过一个全局池化层来生成一个信道级描述符。然后添加三个完全连接的(FC)层,其中通过一个基于通道依赖的自门控机制对每个通道进行学习。然后对原始特征映射进行重新加权,以生成时间注意模块的输出。
在时间框架(通道)中的权重被可视化,以说明我们的时间注意力的结果。在下图中,第一行和第二行分别表示了正常的场景和具有挑战性的场景。如每一帧的左上角所示,在正常情况下,权重近似相等。在具有挑战性的场景中,在低质量帧中的权重较小,而在高质量帧中的权重较大,这显示了时间注意模块的重新校准作用。

Online Tracking
In this subsection, tracking network architecture is described at first which is denoted as FlowTrack.
在本小节中,首先描述了跟踪网络的体系结构,并记为流道。通过尺度处理和模型更新等方面介绍了跟踪过程。
Tracking network architecture
经过上述的离线训练后,利用学习到的网络通过方程(4)进行在线跟踪。首先,将图像通过经过训练的特征网和流量网进行传递。然后,根据流信息,将前一帧中的特征映射扭曲为当前的特征映射。弯曲的特征图和当前帧被嵌入,然后使用时空注意进行加权。通过寻找得分图中的最大响应来获得当前目标状态的估计。
Model updating
大多数跟踪方法在每一帧或以固定的间隔[15,14,25,8]更新它们的模型。然而,当跟踪不准确、目标被遮挡或看不见时,该策略可能会引入错误的背景信息。本文在同时满足标准峰值噪声比(PNR)和响应图最大值的情况下进行模型更新。详情请参阅[48]。仅将CF跟踪模块更新为:
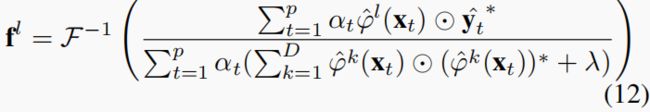
其中, α t α_t αt表示样本 x t x_t xt的影响,p等于帧索引。
Scales
为了处理尺度变化,我们遵循[43]中的方法,并使用具有尺度因子的斑块金字塔![]()
Experiments
实验在四个具有挑战性的跟踪数据集上进行:OTB201350个视频,OTB2015有100个视频,VOT2015和2016VOT60个视频。所有的跟踪结果都使用报告的结果来确保一个公平的比较。
