深度学习入门--Transformer中的Encoder详解:Multi-Head-Attention及Feed-Forward
大家好,我是CuddleSabe,目前大四在读,深圳准入职算法工程师,研究主要方向为多模态(VQA、ImageCaptioning等),欢迎各位佬来讨论!
我最近在有序地计划整理CV入门实战系列及NLP入门实战系列。在这两个专栏中,我将会带领大家一步步进行经典网络算法的实现,欢迎各位读者(da lao)订阅
Transformer中的Encoder详解:Multi-Head-Attention及Feed-Forward
- Self-Attention
-
- Self-Attention的由来
- Self-Attention的公式推导
- 通俗解释
- 从Self-Attention到Multi-Head-Attention
-
- 如何并行化
- 实现代码
- Add&Norm层
-
- 实现代码
- Feed-Forward层
-
- 实现代码
- Positional Encoding
- Encoder各模块组合
-
- Encoder代码
Self-Attention
2017年,谷歌提出了 Transformer结构:《Attention is all you need》
其作为RNN的替代品,输入输出和RNN相同,都为有序序列。但是在计算时为并行化计算。
Self-Attention的由来
Transformer首次创新性地抛弃了传统RNN类结构(RNN,LSTM,GRU)。
传统的RNN类结构输入有序序列,但是在计算输出序列时,需要在上一个step结果计算完成后,将上一个step的结果也作为输入才能得到下一个step的结果,这样便会导致程序训练和推断缓慢的问题。
一种解决方案是采用CNN来同时提取周围附近token的特征,一层层累加,这样在并行化计算的同时也能扩大全局视觉野。

但是这样会造成一个问题:随着序列长度的增加,CNN金字塔的深度会爆炸
因此,谷歌提出了Self-Attention及Multi-Head-Attention来代替传统RNN类网络:
相同:输入和输出与RNN相同,都为有序序列。
不同:无需在上一个step计算完成后才能计算下一个step,所有step并行化计算。
Self-Attention的公式推导
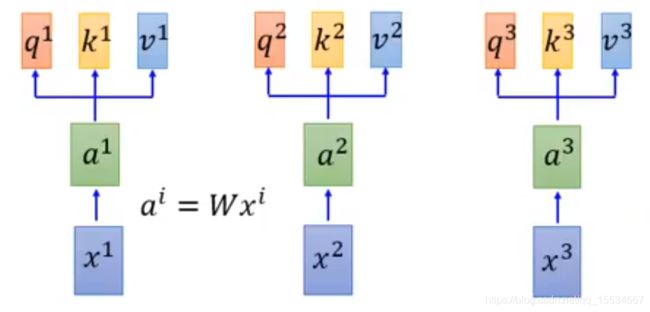
首先对于序列 x 1 , x 2 , x 3 , x 4 , x 5 . . . . x l e n x^{1},x^{2},x^{3},x^{4},x^{5}....x^{len} x1,x2,x3,x4,x5....xlen中的每个 x i x^{i} xi,都进行如下计算:
a i = W a i a^{i}=Wa^{i} ai=Wai
| 矩阵 | 公式 | 含义 |
|---|---|---|
| q i q^{i} qi | q i = W q a i q^{i}=W^{q}a^{i} qi=Wqai | query(查找) |
| k i k^{i} ki | k i = W k a i k^{i}=W^{k}a^{i} ki=Wkai | key(关键字) |
| v i v^{i} vi | v i = W v a i v^{i}=W^{v}a^{i} vi=Wvai | value(值) |
即
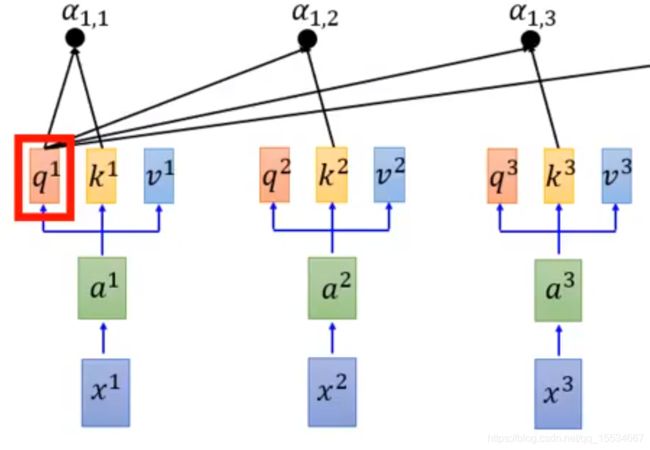
之后计算权重 α i , j \alpha _{i,j} αi,j
以 α 1 , j \alpha _{1,j} α1,j为例,
α 1 , i = q 1 ⋅ k i / d \alpha _{1,i}=q^{1}\cdot k^{i}/\sqrt[]{d} α1,i=q1⋅ki/d
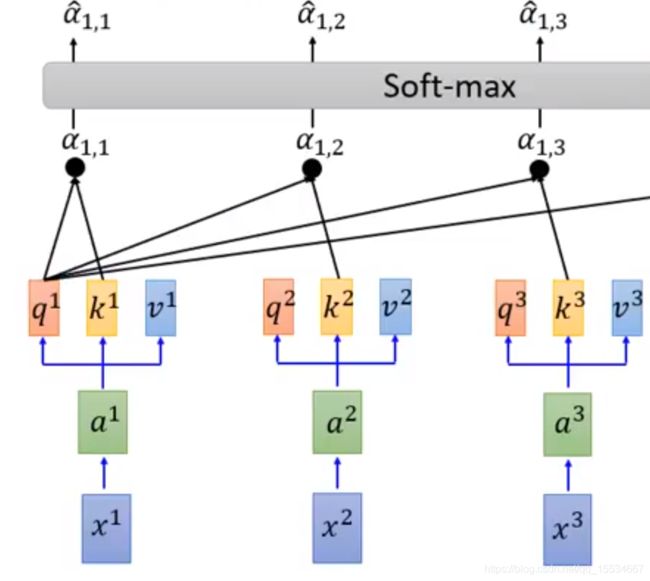
之后将 α i , j \alpha _{i,j} αi,j进行 s o f t − m a x soft-max soft−max来归一化,得到权重系数
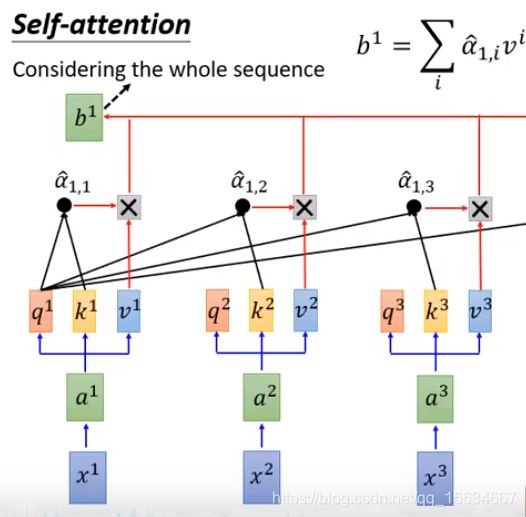
将权重与 v a l u e value value进行加权和,得到第一个 b i b _{i} bi
通俗解释
打个通俗的比喻:小明想从一堆书中学习到有关“复仇者联盟”的知识。
于是:
| q q q | k k k | v v v |
|---|---|---|
| 书的综述 | 复仇者联盟 | 书本内容 |
那么,没有Attention的网络就是相当于小明把每本书都认认真真读了一遍.
而含有Attention的网络便是,先得到每本书的综述 q q q,然后将关键字 k k k----“复仇者联盟”与书的综述 q i q _{i} qi做比对,得到每本书的权重 a i a_{i} ai,再对每本书的内容做加权和: K o n w l e d g e = ∑ a i v i Konwledge=\sum a^{i}v^{i} Konwledge=∑aivi
K o n w l e d g e Konwledge Konwledge便是最终小明学习到的知识,其中有关“复仇者联盟”的书的权值会更大,因此小明看了更多有关“复仇者联盟”的书,看了更少无关的书。这种有针对性的学习特征的方式叫做 A t t e n t i o n Attention Attention
从Self-Attention到Multi-Head-Attention
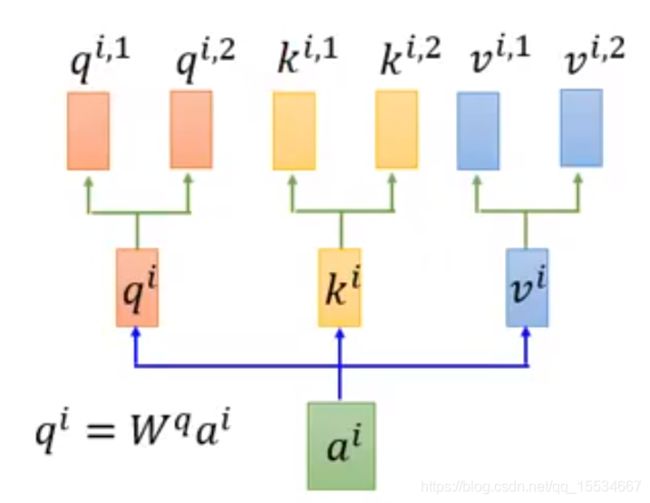
这种一个token会产生多个 q , k , v q,k,v q,k,v的 A t t e n t i o n Attention Attention叫做 M u l t i − H e a d − A t t e n t i o n Multi-Head-Attention Multi−Head−Attention。
其中,每个 H e a d Head Head的注意力会执行不同的任务。
如何并行化


实现代码
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
实现MultiHeadedAttention。
输入的q,k,v是形状 [batch, L, d_model]。
输出的x 的形状同上。
"""
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) 这一步qkv变化:[batch, L, d_model] ->[batch, h, L, d_model/h]
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) 计算注意力attn 得到attn*v 与attn
# qkv :[batch, h, L, d_model/h] -->x:[b, h, L, d_model/h], attn[b, h, L, L]
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) 上一步的结果合并在一起还原成原始输入序列的形状
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# 最后再过一个线性层
return self.linears[-1](x)
Add&Norm层
A d d Add Add实际为一个残差结构
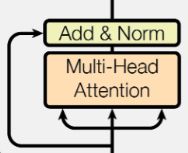
而 N o r m Norm Norm则为 N o r m l i z a t i o n Normlization Normlization;来将分布标准化。
实现代码
class LayerNorm(nn.Module):
"""构造一个layernorm模块"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
"Norm"
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""Add+Norm"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"add norm"
return x + self.dropout(sublayer(self.norm(x)))
Feed-Forward层
F e e d − F o r w a r d Feed-Forward Feed−Forward可以细分为有两层,第一层是一个线性激活函数,第二层是激活函数是 R e L U ReLU ReLU,较为简单。
实现代码
# Feed-Forward
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
Positional Encoding
这里详见我的另一篇文章:Transformer中的Positional Encoding详解
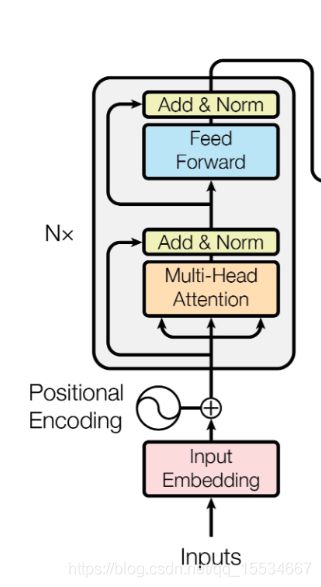
Encoder各模块组合
至此, T r a n s f o r m e r Transformer Transformer中的各模块已经完成了,只需按照下面的结构图进行组装
Encoder代码
def clones(module, N):
"产生N个相同的层"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"""N层堆叠的Encoder"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"每层layer依次通过输入序列与mask"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)