图像超分辨率:调制Modulating Image Restoration with Continual Levels via Adaptive Feature Modification Layer
文章目录
-
- 2. Modulating Image Restoration with Continual Levels via Adaptive Feature Modification Layers
-
- 2.1 研究目的
- 2.2 作者的两个发现
- 2.3 因此只需要两个网络,比如 f15-net, 然后固定f15-net的卷积层,finetune卷积层后面添加一个自适应卷积层,类似图中g的功能,可以得到f50-net 和 g.
- 2.4 aAdaFM layer 设计
- 2.5 λ \lambda λ 和实际的映射关系
- 2.6 一些结果显示
2. Modulating Image Restoration with Continual Levels via Adaptive Feature Modification Layers
set5 数据集 4倍超分,psnr为32.13,state-of-art

2.1 研究目的
现有图像修复方法是不可调节的,因此训练得到的模型不一定适用于图像真是的degradation level,因此作者提出一种方法,可以调节修复的强度。
比如下图,DeJPEG模型q10和q80 来处理degradation q30的图像,并不能产生一个比较适合的结果。
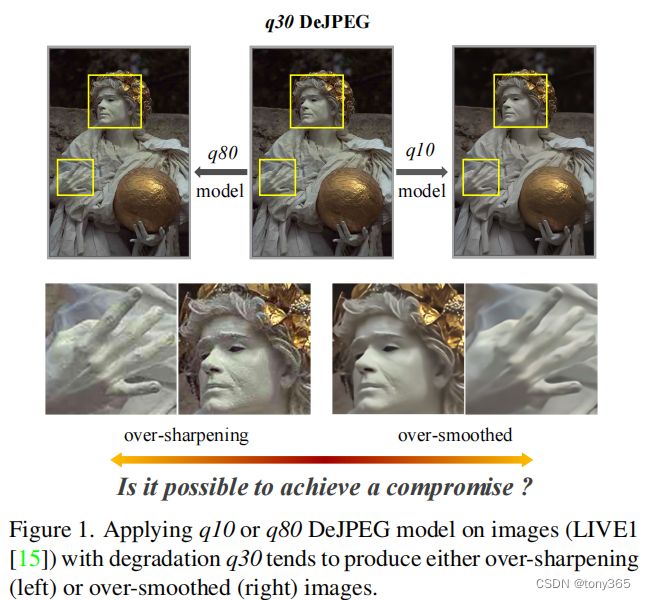
当前的深度学习模型是在一个固定的退化程度的数据集上训练的,不能进行调节。
本文目标是在一个统一的CNN框架中实现任意级别的图像恢复的模型,以达到下面的效果,输入一个类似强度的超参数,可以对图像不同强度的修复。

2.2 作者的两个发现
- 利用ARCNN去噪网络分别训练方差为 15 和 50的数据集, 得到的filter map具有相似的形状,但是均值和方差有差异。如下图a和c,
我好像看不太出均值和方差有差异?
其实就是加了一个卷积层

可以通过一个分离卷积层 将 f15转换为f50,类似:
![]()
- 通过输入一个调制参数来控制 f15 到 f50的转换,比如在卷积层后面加上一个 g卷积。该参数可以连续输出 f15到f50的转换,比如f15到f20,f30.
如何实现的呢?

λ \lambda λ 为0的时候,输出f15;
λ \lambda λ 为1的时候,输出f50.
λ \lambda λ 在0-1之间输出不同强度的去噪filter。
2.3 因此只需要两个网络,比如 f15-net, 然后固定f15-net的卷积层,finetune卷积层后面添加一个自适应卷积层,类似图中g的功能,可以得到f50-net 和 g.
然后利用上面的公式可以得到 f 15 n e t f_{15} net f15net 和 f 50 n e t f_{50} net f50net之间的 net。
网络结构如下:
大概是 1 conv + 16 residual block + 1 conv + 1 pixelshuffle + 2 conv

class AdaResNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, norm_type='batch', act_type='relu',
res_scale=1, upsample_mode='upconv', adafm_ksize=1):
super(AdaResNet, self).__init__()
norm_layer = B.get_norm_layer(norm_type, adafm_ksize)
fea_conv = B.conv_block(in_nc, nf, stride=2, kernel_size=3, norm_layer=None, act_type=None)
resnet_blocks = [B.ResNetBlock(nf, nf, nf, norm_layer=norm_layer, act_type=act_type, res_scale=res_scale)
for _ in range(nb)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_layer=norm_layer, act_type=None)
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok
elif upsample_mode == 'pixelshuffle':
upsample_block = B.pixelshuffle_block
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
upsampler = upsample_block(nf, nf, act_type=act_type)
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_layer=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_layer=None, act_type=None)
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*resnet_blocks, LR_conv)),
upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
上面是整体的框架,然后再看conv_block函数,
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_layer=None, act_type='relu'):
'''
Conv layer with padding, normalization, activation
'''
padding = get_valid_padding(kernel_size, dilation)
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
padding = padding if pad_type == 'zero' else 0
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
dilation=dilation, bias=bias, groups=groups)
a = act(act_type) if act_type else None
n = norm_layer(out_nc) if norm_layer else None
return sequential(p, c, n, a)
重点是 norm_layer,就是根据不同的设置获得不同的正则化函数
def get_norm_layer(norm_type, adafm_ksize=1):
# helper selecting normalization layer
if norm_type == 'batch':
layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
elif norm_type == 'instance':
layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
elif norm_type == 'basic':
layer = functools.partial(Basic)
elif norm_type == 'adafm':
layer = functools.partial(AdaptiveFM, kernel_size=adafm_ksize)
else:
raise NotImplementedError('normalization layer [{:s}] is not found'.format(norm_type))
return layer
比如basic和adafm的代码如下
groups=in_channel 是一个分通道卷积
class AdaptiveFM(nn.Module):
def __init__(self, in_channel, kernel_size):
super(AdaptiveFM, self).__init__()
padding = (kernel_size - 1) // 2
self.transformer = nn.Conv2d(in_channel, in_channel, kernel_size, padding=padding, groups=in_channel) # 分通道卷积
def forward(self, x):
return self.transformer(x) + x
class Basic(nn.Module):
def __init__(self, in_channel):
super(Basic, self).__init__()
self.in_channel = in_channel
def forward(self, x):
return x
在训练的时候首先设置为basic,进行训练,比如得到了f15(被设置为 return x直接返回不做处理)
然后设置为adafm进行训练,卷积层的weight可以类比为公式中的g, 卷积后得到filter map(f50)
实际公式:
f 15 w e i g h t = 1 f_{15} weight = 1 f15weight=1
f 50 w e i g h t = g f_{50} weight = g f50weight=g
f m i d w e i g h t = λ ∗ g f_{mid} weight = \lambda * g fmidweight=λ∗g
实际代码设置 λ \lambda λ后,对训练后的adafm net中的adafm norm layer乘上缩放系数 λ \lambda λ得到新的网络参数, 下面代码中coef是 λ \lambda λ的含义,即对AdaptiveFM的weight直接乘上 λ \lambda λ
interp_dict = model_dict.copy()
for k, v in model_dict.items():
if k.find('transformer') >= 0:
interp_dict[k] = v * coef
model.update(interp_dict)
2.4 aAdaFM layer 设计
-
一个分离通道的卷积, 卷积核的大小,影响效果

-
训练的方向影响精度,比如是从难度低的 2X分辨率 训练到 4X分辨率还是从 4Xfinetune到2X?
答案是 前者,从易到难训练。 -
训练的模型的跨度
跨度越大,效果越不太好,因此可以考虑多训练几个模型,插值得到新的模型。
关键就是一个卷积层
class AdaptiveFM(nn.Module):
def __init__(self, in_channel, kernel_size):
super(AdaptiveFM, self).__init__()
padding = (kernel_size - 1) // 2
self.transformer = nn.Conv2d(in_channel, in_channel, kernel_size, padding=padding, groups=in_channel)
def forward(self, x):
return self.transformer(x) + x
class Basic(nn.Module):
def __init__(self, in_channel):
super(Basic, self).__init__()
self.in_channel = in_channel
def forward(self, x):
return x
2.5 λ \lambda λ 和实际的映射关系
就是你训练了 方差 15 ,50的两个数据集,得到两个去噪网络,对应 λ \lambda λ分别是0,1 ,但是现在有个图像是噪声方差为20, 你应该设设置 λ \lambda λ 为多少?
一个deJPEG的例子,从80到10 和 从80 到 40。可以考虑多训练几个模型,然后每段近似线性,这样可以进行线性插值得到中间阶段的卷积weight
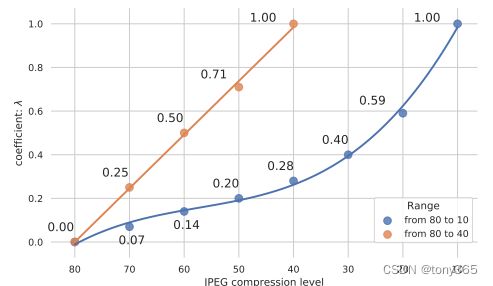
2.6 一些结果显示
有图可以看出设置不同的 λ \lambda λ参数,会得到相应程度的图像恢复,再去噪,去jpeg压缩,超分上的表现如下:

超分问题如何调节的?还没详细研究, adafm 不改变尺寸?待续