OUC2022秋季软件工程第16组第二周作业
OUC2022秋季软件工程第16组第二周作业
目录
文章目录
- OUC2022秋季软件工程第16组第二周作业
-
- 目录
- 一、视频学习心得及问题总结
-
- 1、学习心得
-
- 张欣悦:
- 赵艳蕊:
- 杨婷:
- 郑欣欣:
- 张维娜:
- 2、问题总结:
-
- 张欣悦:
- 赵艳蕊:
- 杨婷:
- 郑欣欣:
- 张维娜:
- 二、代码练习(关键步骤截图、想法和解读)
一、视频学习心得及问题总结
1、学习心得
张欣悦:
1、人工智能的初步认知:
在第一节绪论内容中,首先了解了人工智能的发展历史和定义。概括来说就是让机器像人一样进行感知、认知、决策、执行的人工程序或系统。人工智能的核心在于三个层面:计算智能、感知智能、认知智能。从视频中可以了解到人工智能具有多领域广泛应用的特点,在如今具有良好的发展趋势。
2、机器学习:
无论是从常用定义、可操作定义还是统计学定义来看,机器学习的意义在于从数据中自动的提取知识。学习机器的关键在于:模型、策略、算法。重点的了解了模型的分类即有监督和无监督其中有监督学习中比较有名的就是支持向量机(SVM)模型。

3、深度学习:
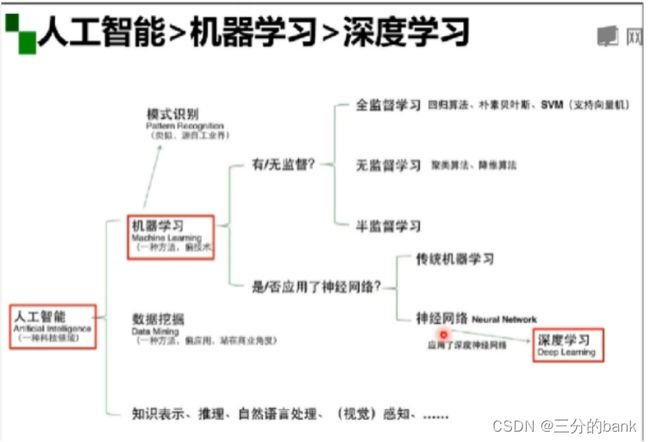
通过这个思维导图我们不难看出各个阶层的相互关系。在绪论视频的学习中,我们对传统的机器学习和深度学习进行了对比。除了视频学习,在参考了其他相关文档后,可认为有以下对比结果:
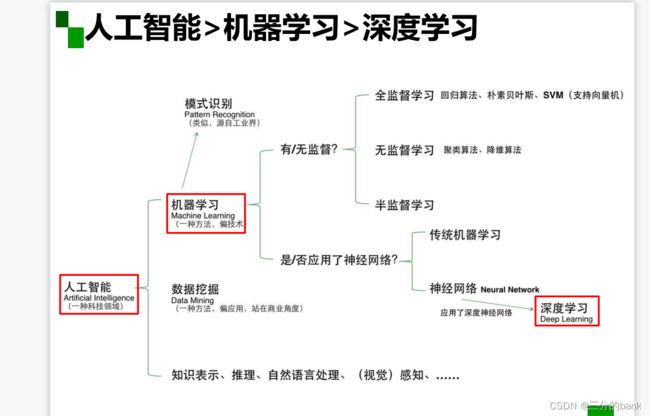
(1)数据依赖性 深度学习算法一般需要大量的数据支撑,在数据量不够的情况下,传统的机器学习算法使用制定的规则,性能或许会更好。 (2)硬件依赖 与传统机器学习算法相比,深度学习的计算更加复杂,计算量庞大,为保证速度,通常需要GPU来加速运算。(3) 特征处理 大多数机器学习算法的性能依赖于所提取的特征的准确度,深度学习尝试从数据中直接获取高等级的特征。(4)问题解决方式传统机器学习通常会将问题分解为多个子问题并逐个子问题解决,最后结合所有子问题的结果获得最终结果,而深度学习提倡直接的端到端的解决问题。(5)可解释性 相较于深度学习,类似于决策树这样的机器学习算法为我们提供了清晰的规则,告诉我们什么是它的选择以及为什么选择了它,很容易解释算法背后的推理。
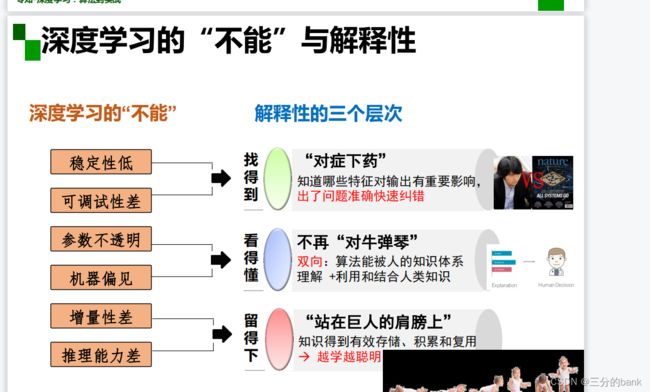
深度学习也有它的明显弱势:
4、神经网络学习:
首先从生物上的神经元特性引入,我们所要构造的神经网络可以认为是对神经元处理信息的模拟。如果没有激活函数,那么每一层的输出都是上一层输入的线性函数,无论有多少层,输出的都是输入的一个线性组合。但是使用了激活函数就可以引入非线性的因素,让它可以逼近任何的非线性函数。
其次,我了解了几种常见的激活函数,如S性函数、ReLU、双极S性函数、Leaky ReLU等等激活函数,以及从单层感知器单层感知器如何实现线性分类问题,进而到多层感知器实现非线性分类问题。万有逼近定理解释了当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼近任意非连续函数:可以解决任何复杂的分类问题。

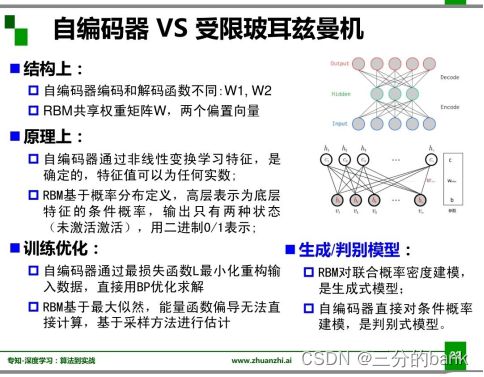
自编码一般是多层神经网络,是一种尽可能复现输入信号的神经网络。RBM是两层神经网络,包含可见层v(输入层)和隐藏层h 。
赵艳蕊:
首先,在绪论的学习中,我了解了人工智能的定义、起源和发展史,学习了人工智能的三个层面,了解了人工智能在金融、内容创作和机器人等领域的应用。老师通过几个例子对比讲解了专家系统和机器学习,让我懂得了机器学习具有效率和准确性更高、减少了人工的主观因素等优点。之后,老师对机器学习展开了具体的讲解。在机器学习中,应用了神经网络的学习为深度学习。从传统机器学习到深度学习,我们可以看到深度学习不再依赖人工设计特征,具有很多的优点。但是,深度学习也有很多“不能”:稳定性低、可调试性差、参数不透明、机器偏见、增量性差、推理能力差。
在第二节的学习中,我首先学习了浅层神经网络,了解了生物神经元的结构,懂得了为什么需要激活函数,认识了单层感知器,即首个可以学习的人工神经网络。但是单层感知器无法解决异或,这是多层感知器才能实现的。紧接着学习了万有逼近定理,即如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。在后面,老师又讲解了神经网络每一层的作用,对于“更宽or更深”的问题,我明白了在神经元总数相当的情况下,增加网络深度可以比增加宽度带来更强的网络表示能力。后面,我又学习了梯度和梯度下降和误差反向传播,认识到梯度消失的现象。在从神经网络到深度学习的章节中,我懂得了解决梯度消失的方法:逐层预训练。而逐层预训练用到了受限玻尔兹曼机和自编码器。预训练初衷用于无监督逐层预训练,但逐层预训练无法本质上解决梯度消失问题。
杨婷:
在这次学习中,我首先学习了人工智能的定义及起源,然后了解了人工智能的应用领域及其相关的三个层面,然后学习了实现人工智能的方法——机器学习,了解了机器学习的定义,以及学什么,怎么学的问题。如果机器学习应用了神经网络,且是深度的神经网络,则称为深度学习。
了解了深度学习的含义之后,我了解到深度学习在理论研究中的从能到不能,深度学习虽然有诸多优点,但依旧存在稳定性差,可调试性差,参数不透明,机器偏见,增量型差,推理能力差的缺点。
在第二节中,我学习了神经网络的有关内容。首先从浅层神经网络入手,我了解到了什么是激活函数以及为什么要应用激活函数,并了解了几种较为常见的激活函数。然后通过学习了单层感知器如何实现线性分类问题,进而到多层感知器实现非线性分类问题。通过万有逼近定理,我明白神经网络的层数越多越强大。在神经元总数相当的情况下,增加网络深度可以比增加宽度带来更强的网络表示能力。

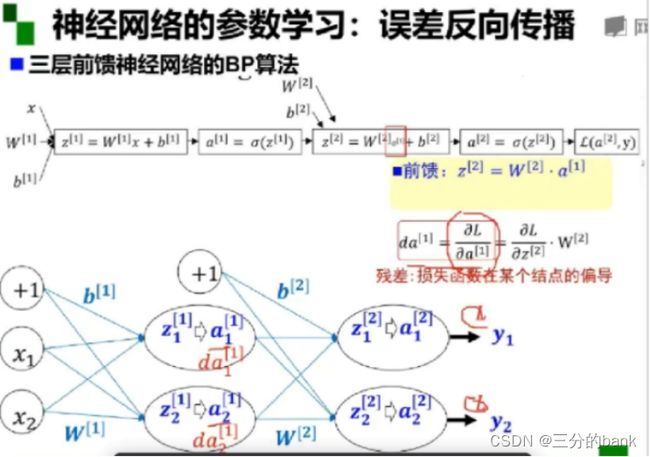
但是随着层数增加,会出现训练比较困难,梯度消失,局部极小值的现象,这是因为神经网络的参数学习是通过误差反向传播的(链式函数求导),参数沿着负梯度方向更新使得函数值下降,前馈与反馈过程相反,这一部分不是很懂。
随着神经网络的发展,在多层神经网络中,梯度消失和局部极小值的现象可以通过逐层预训练得到改善,但不能从本质上解决该问题。逐层预训练需要解决没有监督信息的问题,可以通过使用受限玻尔兹曼机和自编码机这两种方法解决。
自编码机假设输出与输入相同,是一种尽可能复现输入信号的神经网络,一般是一个多层神经网络(最简单:三层)。自编码机的编码和解码函数不同,在原理上通过非线性变换学习特征,特征值可以为任何实数;在训练优化上通过损失函数L最小化重构输入数据,用BP优化求解。自编码器直接对条件概率建模,是判别式模型。
受限玻尔兹曼机是两层神经网络,包含可见层和隐藏层。RBM在结构上共享权重矩阵,有两个偏置向量;在原理上基于概率分布定义,高层表示为底层特征的条件概率,输出只有两种状态;在训练优化上基于最大似然。RBM对联合概率建模,是生成式模型。
郑欣欣:
在第一节绪论中,我们了解到:
1.人工智能的发展对于国家是十分重要的,目前各国均加大对人工智能的投资,并且进行了国家层面的部署,对人工智能的发展高度重视。人工智能的人才缺口较大,加强高校对于人工智能学科的建设。人工智能是使一部机器人像人一样进行感知、认知、决策、执行的人工智能或系统。对人工智能的起源有了一定的了解。人工智能发展标志性事件和人工智能发展阶段。
2.人工智能的三个层面,代表了人们对人工智能从低到高的期望,由计算智能到感知智能再到认知智能,目前的人工智能只能做到感知智能,认知智能还未实现。人工智能可以和多个行业或者生活相结合,对生活或者行业提供便利,例如人工智能+金融,人工智能+内容创作,人工智能+机器人等。
3.从专家系统到机器学习
专家系统是人为的设定一系列既定的规则,机器对所需要解决的问题的判断依据是人工设定的规则。
机器学习是通过对大量的数据进行学习,由机器自动训练,通过训练生成模型,由生成的模型对输入进行判定。
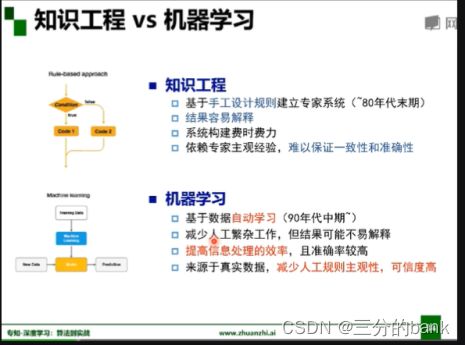
机器学习相关概念以及机器学习学什么,怎么学的问题,对于机器学习的模型进行了详细的介绍

-
传统机器学习到深度学习
传统机器学习中对特征的提取一般是由人工完成的,难以得到好的特征,而深度学习是由机器自动学习特征,寻找最合适的模型。

-
深度学习的能与不能
深度学习有三个助推器:大数据,算法,计算力。
深度学习仍有很多缺点:算法输出不稳定,容易被“攻击”;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端到端训练方式对数据依赖性强,模型增量性差;专注直观感知类问题,对开放性推理问题无能为力;人类知识无法有效引入进行监督,机器偏见难以避免。
在深度学习概述中,
- 浅层神经网络:生物神经元到单层感知器,多层感知器,反向传播和梯度消失。
了解神经元的结构,构建M-P模型,单层感知器是首个可以学习的人工神经网络。但是单层感知器无法解决异或问题,可以通过多层感知器(与非或)实现异或。
万有逼近定理,(如果一个(双)隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的(非)连续函数)。
神经网络“瘦高”相较于“矮胖”更有效,即在神经元总数相当的情况下,增加网络深度可以比增加宽度带来更强的网络表示能力:产生更多的线性区域。
误差反向传播:将误差信号回传,通过梯度利用回传的误差重新更新神经元,提高准确度。
多层神经网络的问题:梯度消失。每一层的对激活函数求导可能会很小,很多个很小的数相乘导致梯度消失。 - 神经网络到深度学习:逐层预训练,自编码器和受限玻尔兹曼机。
逐层预训练,可以改善梯度消失和局部最小值的问题,但缺少监督信息,可通过自编码机和受限玻尔兹曼机解决
张维娜:
1、1绪论,我认识到了学习人工智能的重要性,各个国家在人工智能上争斗,而我国在人工智能的企业虽不少,但是具有人工智能研究方向的高校占比及少,输出的人工智能方向的人才更少,我们要努力学习人工智能,这个是我们的责任了,进一步认识了人工智能的三个层面:计算智能、感知智能、认知智能和人工智能的应用,人工智能与金融、机器人、内容创作的融合应用具有十分重大的意义。

半监督学习和强化学习
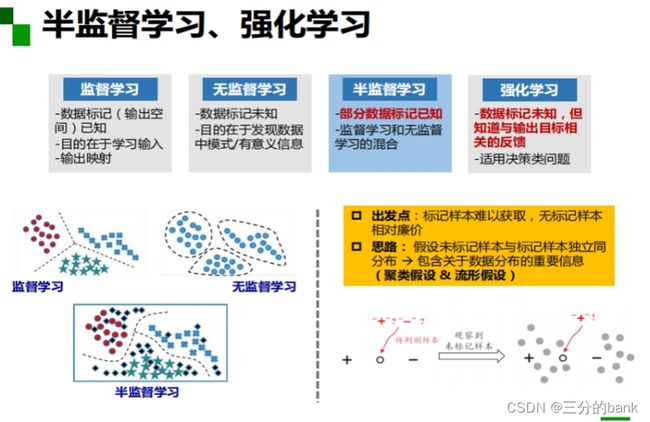
1、2 我通过传统机器学习与深度学习的对比,从各个方面了解了深度学习,感受深度学习的魅力,也知道了深度学习的三个助推剂:大数据、算法、计算力。进一步研究开发深度学习可以从这几个方面入手,不断深入研究大数据、算法、计算力。

2、问题总结:
张欣悦:
由于视频学习中结合了很多数学方面的知识,并且是第一次接触到关于神经算法的知识,导致很多东西没有看明白,整理起来比较的混乱,BP算法这块感觉思路很混乱。不太理解为什么增加深度会导致梯度消失?
赵艳蕊:
在本次学习中,我觉得绪论部分的内容比较容易理解,在后面的神经网络的学习中,由于数学基础比较薄弱,再加上一些理论比较复杂,对于一些知识的学习不太透彻,感觉比较难的是误差的反向传播以及后面讲的受限玻尔兹曼机。
杨婷:
在学习中,我对于高数和概率统计的知识有所淡忘,学习的时候也没有学扎实,所以对于误差的反向传播理解的不是很透彻,以及残差的计算,感觉有点糊涂。其次,我对于RBM感觉也不是很懂,希望老师在课堂上解惑。
郑欣欣:
在深度学习中,机器的结果如果出现了错误,能否人为插入使其输出正确的结果。绪论部分较为简单,但后面的神经网络到深度学习知识较为困难,对于数学知识的遗忘,对于RMB的讲解不太明白。
张维娜:
在本次学习中,我觉得绪论部分的内容比较容易理解,在后面的神经网络的学习中,由于数学基础比较薄弱,再加上一些理论比较复杂,对于一些知识的学习不太透彻,感觉比较难的是误差的反向传播以及后面讲的受限玻尔兹曼机。
二、代码练习(关键步骤截图、想法和解读)
第一部分的代码
- 数据定义
定义的数据可以是一个数,可以是一个一维数组(向量),二维数组(矩阵),甚至是多维数组(张量),如下图:

也可以通过方法来定义数据,如下图:

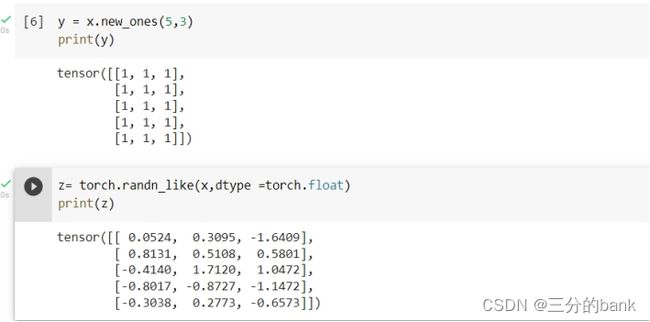
可以通过现有的tensor,创建新的tensor,如下图:
- 数据操作
· 基本运算,加减乘除,求幂求余
· 布尔运算,大于小于,最大最小
· 线性运算,矩阵乘法,求模,求行列式
可以通过切片形式访问数据,如下图:

基本运算:

通过matplotlib绘图,如下图:

第二部分的代码:
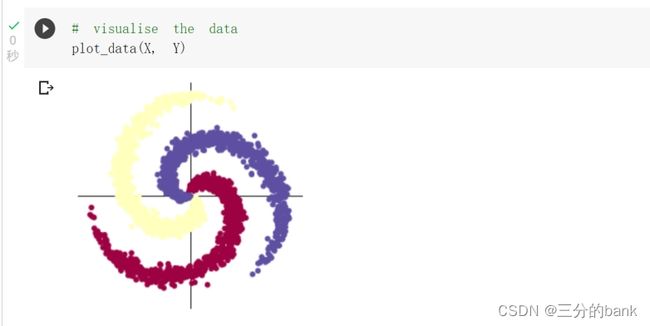
首先引入基本的库并初始化数据,下图主要是初始化数据,构建了两个矩阵X和Y,其中X是3000×2的矩阵,因为有两个特征,所以列数为2,存储的数据是随机产生的;Y是3000×1的标签矩阵,存
储的样本的类型(分别为:[0,1,2])

输出图形为:
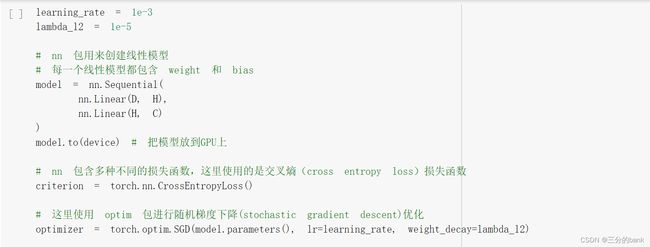
- 线性模型分类
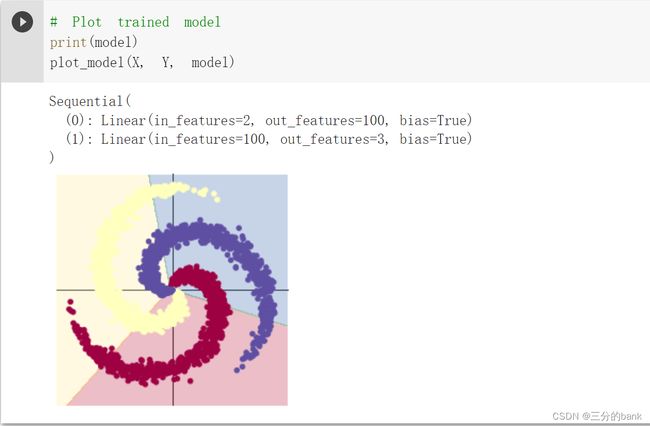
使用Adam优化器,最后一轮训练结果如下:
- 双层神经网络分类
在之前的线性模型的基础上添加ReLU激活函数
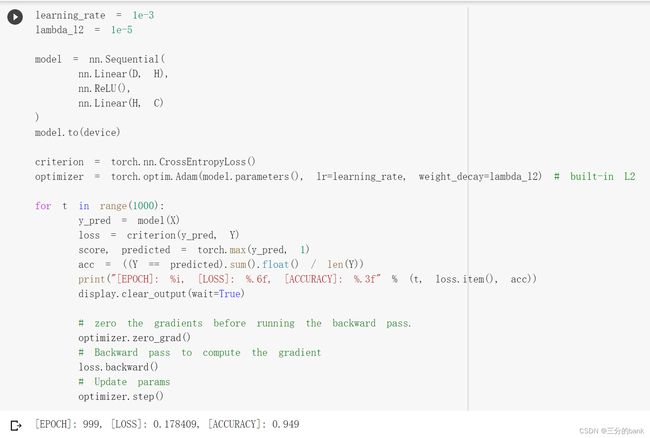
使用Adam优化器,最后一轮训练结果:
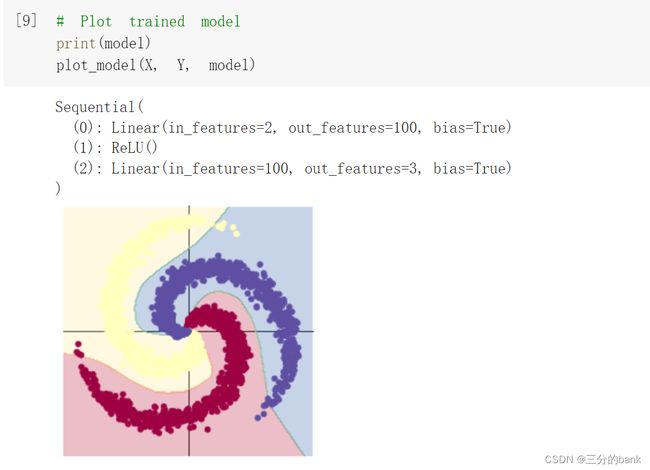
加入激活函数之后,模型具有了一定的非线性拟合能力,准确率能达到95.4%,相比单纯的线性模型有了很大提高