Recent advances in biomedical literature mining
Abstract
随着生物医药领域的文献逐渐增加,隐藏在其中的领域知识对医药领域的研究和应用至关重要。这对生物医药文献挖掘提出了新的要求。生物医药信息学(BMI)社区关注具体的应用场景,计算机科学(CS)追求性能和泛化能力。本文旨在回顾这个领域的进展并激发新的研究方向。
Introduction
生物医药研究发展很快,难以让人了解所有感兴趣的内容,因此生物医药文献的自动信息抽取和挖掘技术需求很高。
生物医药文献挖掘(Biomedical literture mining,BLM)指利用文本挖掘和自动知识抽取和挖掘技术从医药文献中挖掘信息。医药文献相比其他医药文本(譬如临床记录),更加容易获取且形式规范、多样、新颖。BLM成功应用于医药文献检索,医药问答系统,临床决策支持等。
过去十年BMI针对特定问题,CS致力于开发新算法,都做出了很多努力。
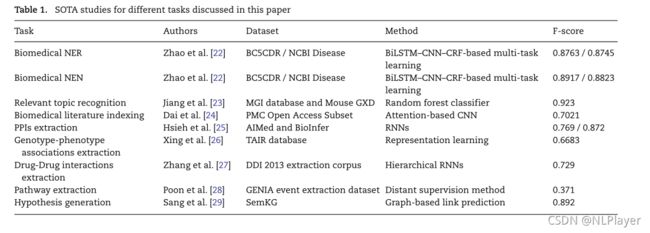
深度学习技术飞速发展,出现了许多NLP领域的SOTA模型,并取得了巨大的进步。
5个不同种类的生物医药研究:生物医药NER和规范化、文本分类、关系抽取、路径抽取、假设生成。路径抽取通过联合它们去生成路径并连接关系。假设生成可以促进新的有潜力的生物医药发现。生物医药NER和规范化和文本分类是其他任务的基础,是下游任务关系抽取的必要步骤。路径抽取和假设生成通常建立在关系抽取之上。
SOTA model
 Biomedical NER and Normalization
Biomedical NER and Normalization
NER的目的: 为了将BML中的非结构文本结构化用于分析研究,NER通常识别化学成分、基因、蛋白质、医药、药物、疾病、症状等生物医药实体以便研究。
NER在生物医药中的应用:搜索引擎、组织并且来链接BM文档、从生物医药文献中挖掘实体关系。
NER的限制:由于有限且可用的高质量标签数据,以及文本语言的变化(使用缩写、非标准名称、冗长的描述),这使得建立一个高性能的生物医药NER系统具有很大的挑战性。
Task definition
NER和NEN都是序列标注问题,NEN可以视作NER的下游任务,用来将NER从文本中找到的实体边界映射到可控的词汇表中。
Methods of biomedical NER
传统的生物医药NER方法:基于词典的方法,语义方法和统计方法。
基于词典的方法:通过匹配去找出相同的实体,但是难以泛化出词典中没有的实体。
语义方法:语义方法要求丰富的领域知识构造NER的规则或模式。
统计方法:将NER视为分类问题去训练统计模型(例如决策树、支持向量机、基于马尔可夫模型的序列标注问题,如HMM、CRF等)
深度学习在NER领域中取得了重大的进展,一种经典的处理NER的神经网络模型如下:
1.character embeding 代表单词中每个字符的字符向量
2.CNN以character embeding为输入生成单词的向量表示
3.生成的单词向量表示和外部与训练的单词嵌入向量相结合输入到BiLSTM层中, 并对医学文本中方的长程依赖结构进行建模。BiLSTM为序列中每个单词计算两个单独的潜在嵌入变量,该序列捕捉单词序列的前向和后向语义依赖关系。这两个向量将被串联起来。
4.解码层通过仿射变换来改变BiLSTM表示。
5.条件随机场层计算词序列的相似性。
Bert模型:BERT模型的主要构建是Transformer,Transformer应用注意力机制去学习一句话中词之间的文本关系。BERT是Transformer的一个新范式,通过在注意力层中同时关注上下文,预先训练为标记文本的深度双向表示。BERT的两个步骤:pre-training和fine-tuning.预训练期间,模型被用于训练像预测被缺失token或者预测下一个句子这样的大规模未标注文本。微调期间,所有的参数都被使用下游任务的标注文本来微调完成。和传统的从左到右的语言模型不同的是,BERT用来预测随机的缺失token和预测两个句子是否有前后关系。
Methods of biomedical NEN
1.基于规则;2. a pairwise learning to rank(两两学习排序);3.词典查找。
NER的精确率直接影响NEN的性能。
Methods of joint modeling biomedical NER and normalization
因为NER和NEN的内部依赖,所以最近将他们联合研究。
semi-CRF用来联合实体识别并且消歧;维特比解码用来指定词性并且规范不标准的token。semi-Markov用来联合疾病实体识别和规范化
Challenges
1.单词的同义词和可替代性导致词汇表的激增;
2.长实体的边界很难被探测到;
3.实体被缩写或者其他的方式所替代;
4.歧义或者模糊也是有潜力的问题;
5.nested NER也是一个问题。
NEN留下的问题:1.句法多样性,2.相同实体的不同形式;3.语义多样性,命名实体不存在于参考字典,甚至需要额外的知识库去获取命名实体的同义词。
Biomedical literature classification
Task definition
两种类型的医药文章分类任务:1.文章主题识别分类;2.医药文献检索。
Methods:
Conventional:
relevant topic recognition:supervised maching learning models, ranking models and ontology matching models. Examples:SVM:identity the abstracts related to PPIs, biomedical literature into topics; PLC(probabilistic latent categoriser概率潜在分类器) with KL(kullback-Leibler) divergence (KL熵) : to re-rank documents;ontology alignment algorithm(本体论对齐算法):classfy a collection of biomedical abstracts.
Assigning MeSH terms(指定医学主题词)(Multi-label classfication):k-nearest neighbor(KNN),Naive Bayes,SVM,learning to rank。feature engineering instead of the classfier:integrating multiple tyupes of evidence generated from BOW representation in the framework of learning to rank;incorporating the deep semantic information to generate large-scale MeSH indexing.
deeplearning:
dl在文本分类任务中取得了SOTA模型,相比传统的机器学习需要特征工程,深度学习实现了端到端的学习。
深度学习在MeSH terms上的两个模块:1、对每个MeSH term产生likelihood sores;2、分类器决定term之间是否是相关或是不相关的;
applied models: 多层前向反馈神经网络、CNN,RNNs,BERT and ELMo(都是预训练模型),基于注意力机制的模型。FullMeSH模型对每个section训练了 attention-based CNN,在不常见的MeSH标题上达到了SOTA模型。
Challenges:
标签空间过大;标签关系复杂;标签偏置:过大的标签空间导致很难提供精确的训练数据,影响分类器的质量。
Biomedical RE:
Task definition:
实体之间的关系检测和分类。难点在于相比实体识别,实体关系更加具有多样性。现存的研究方向:1.基于模板/规则的方法使用领域专家生成的模式从文本中提取关系和相关概念。2.统计方法从经常一起出现的概念对中寻找关系。3.基于NLP的方法执行句子分析,将文本分解为一种结构,很容易提取关系。
Methods for different relation ectraction tasks
4类关系抽取研究:1.protein-protein interactions; 2.genotype-phenotype relations; 3.chemical-protein interactions; 4.drug-drug interactions.
1.protein-protein interactions(PPIS)
目的:用于理解复杂疾病的机制并且设计治疗方法。
Methods:
a.基于规则/模板,早期,缺点是误报率(FP rates)较高;b.人工标注规则,fp较低,但是召回率较高;c.机器学习从标注文本中学习语言规则,在降低误报率和提升覆盖率优于基于规则的方法。examples:动态规划算法可以从带有词性标签的句子中提取;基本核的方法来学习基因和蛋白质-蛋白质相互作用模式;基于贝叶斯网络的方法从非结构化文本中提取PPI三元组;利用NLP技术提取的每个PPI三元组中的语法关系,并构建基于最短路径的特征,以构建用于PPI提取的分类器。
2.Genotype-phenotype associations(GPA)
研究应用:从医药文献中识别GPA是精确医药的中心任务。
研究方向:specic type(human genes and phenotypes),entity type(focus on specific phenotypes such as disease and gene associations)。
研究方法:基于模式;基于学习方法。
3.Chemical-protein interactions(CPI)
研究用途:药物发现和研发的基础任务。
研究背景:领域专家很难从文献中找到大规模的化学化合物和基因。
研究方法:1.概率论模型:mixture aspect model(MAM) to mini implicit CPIs in the text based on compound-target co-occurrence patterns; 2.linguistic pattern-aware dependency tree kernel to extracts CPIs; 3.构建CPIs pairs and triplets and exploited sophisticated features by analyzing the sentence structures.
4.Drug-drug interantions(DDI)
研究应用:DDI识别是post-market 药物安全和药物警戒的必要任务。
研究方法:DDI检测通常被视为一个二分类问题。方法通常为基于规则、基于同时出现、机器学习。有了更好的语料之后,机器学习和深度学习开始发挥作用。
application:biomedical knowledge base curation
医药关系抽取有效地支持医药知识库的整理,医药知识库包括医药实体与关系和医药NER与关系抽取的自然集合。
recent advances with Deep Learning:
背景:通过机器学习可以解决本质上为分类问题的关系抽取技术。机器学习手写特征作为输入,但是人工特征是困难且耗时的。开始研究基于CNNs和RNNs的神经网络。
BERT模型在关系抽取任务中取得了巨大的成功。
Challenges:
1、医药实体表达不规范;2、相对于常规的关系抽取的二元关系,生物医药实体可能是一元、二元和多元的关系。3、可用的标注语料较少,这需要领域专家的帮助。4、医药领域一直有新的发现,导致很难进行实体的识别。
Biological pathway extraction
应用:理解复杂疾病的根本潜在机制。自动从生物医学文献中提取生物通路。
Task definition
医药路径包括基因、基因工程和小分子之间的相互反应。
Methods
1、基于规则的方法:由于文本表示的可流动性通常导致低召回率。
2、机器学习:优于机基于规则的方法,但是需要大量标注数据,任然需要人工标记。
3、基于机器学习和规则的混合方法:
存在的问题:
Conclusions
这个领域的关键任务:生物医学NER和规范化,文本分类,关系抽取,生物途径抽取,假设生成。介绍了应用场景并强调了深度学习模型的潜力。