matlab 特征降维方法,降维和特征选择的关键方法介绍及MATLAB实现
目录
概念理解
降维:
特征选择:
降维的方法
主成分分析(Principle Component Analysis, PCA)方法
偏最小二乘法(Partial Least Squares, PLS)
MATLAB实现
重点函数解读:
【例】光谱数据主成分回归分析(PCR)
【例】偏最小二乘法(PLS)
特征选择的方法
Filter vs. Wrapper
搜索法
随机搜索
启发式搜索
正则化方法
可视化评价指标
概念理解
降维:
比如现在有100维的变量来表征一个东西,我们觉得太冗余复杂了,想降低到10维。但是我们没有确定的筛选依据,直接使用数学工具来实现降维,就好像丢进了一个黑箱,经过抽象、提炼,得到了新的10维特征,这新的10维特征可能失去了物理意义,我们也不知道它们具体是怎么来的,表征什么,但是确实是可以用它们表征这个东西,而且是经过了原先100维特征的信息的融合、取舍过程。它的过程是比较高级的。
特征选择:
选择出100维特征里面最重要的10个特征,这个筛选过程是有依据的。比如苹果有很多特征, 大小,形状,颜色,味道,生长季节,……。我们选择:颜色红、味道甜等几个非常明显的重要的特征出来就足以表示苹果了。当然,颜色和味道可能也有一定的耦合关系,生成地点、时间也有耦合关系,如果懒得管特征之间的耦合关系,直接丢进降维的黑箱中,也可以得到新的几个降维后的特征,但我们可能就说不出这个特征的含义了,只是一些数据信息而已了。
降维的方法
主成分分析(Principle Component Analysis, PCA)方法
推导过程详见:《主成分分析(PCA)的线性代数推导过程》。




主成分回归分析PLR = 主成分分析 + 多元线性回归分析,利用提取出来的主成分来做回归模型。
偏最小二乘法(Partial Least Squares, PLS)
解决了PCA中不足的地方。
• PCA方法提取出的前若干个主成分携带了原输入变量矩阵的大部分信息,消除了相互重叠部分的信息。但没有考虑主成分对输出变量的解释能力,方差贡献率很小但对输出变量有很强解释能力的主成分将会被忽略掉,这无疑会对校正模型的性能产生一定的影响。偏最小二乘法(PLS)可以很好地解决这个问题。
• PLS的基本思路是逐步回归,逐步分解输入变量矩阵和输出变量矩阵,并综合考虑提取的主成分对输入变量矩阵和输出变量矩阵的解释能力,直到满足性能要求为止。
设标准化的输入变量矩阵和输出变量矩阵分别为:




MATLAB实现
重点函数解读:
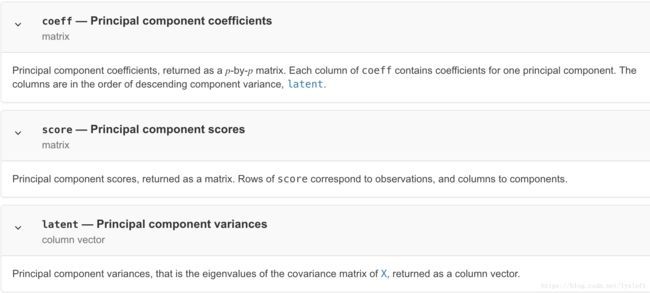
• princomp 提取主成分 高级的MATLAB版本使用pca替换了 请查阅matlab文档
COEFF = princomp(X) performs principal components analysis (PCA) on the n-by-p data matrix X, and returns the principal component coefficients, also known as loadings.
https://ww2.mathworks.cn/help/stats/princomp.html?s_tid=doc_ta
我们的代码中使用到:[PCALoadings,PCAScores,PCAVar] = princomp(NIR),亦即[coeff,score,latent] = pca(___)方法。其输出参数含义是:
• regress 多元线性回归
b = regress(y,X) returns a p-by-1 vector b of coefficient estimates for a multilinear regression of the responses in y on the predictors in X.
https://ww2.mathworks.cn/help/stats/regress.html?s_tid=doc_ta
• plsregress 偏最小二乘回归
[XL,YL] = plsregress(X,Y,ncomp) computes a partial least-squares (PLS) regression of Y on X, using ncomp PLS components, and returns the predictor and response loadings in XL and YL, respectively.
https://ww2.mathworks.cn/help/stats/plsregress.html?s_tid=doc_ta
【例】光谱数据主成分回归分析(PCR)
60个样本,每个样本包含401维度特征的汽油辛烷值光谱测量值。
%% I. 清空环境变量
clear all
clc
%% II. 导入数据
load spectra;
%% III. 随机划分训练集与测试集
temp = randperm(size(NIR, 1));
% temp = 1:60;
%%
% 1. 训练集――50个样本
P_train = NIR(temp(1:50),:);
T_train = octane(temp(1:50),:);
%%
% 2. 测试集――10个样本
P_test = NIR(temp(51:end),:);
T_test = octane(temp(51:end),:);
%% IV. 主成分分析
%%
% 1. 主成分贡献率分析
[PCALoadings,PCAScores,PCAVar] = princomp(NIR);
figure
percent_explained = 100 * PCAVar / sum(PCAVar);
pareto(percent_explained)
xlabel('主成分')
ylabel('贡献率(%)')
title('主成分贡献率')
%%
% 2. 第一主成分vs.第二主成分
[PCALoadings,PCAScores,PCAVar] = princomp(P_train);
figure
plot(PCAScores(:,1),PCAScores(:,2),'r+')
hold on
[PCALoadings_test,PCAScores_test,PCAVar_test] = princomp(P_test);
plot(PCAScores_test(:,1),PCAScores_test(:,2),'o')
xlabel('1st Principal Component')
ylabel('2nd Principal Component')
legend('Training Set','Testing Set','location','best')
%% V. 主成分回归模型
%%
% 1. 创建模型
k = 4;
betaPCR = regress(T_train-mean(T_train),PCAScores(:,1:k));
betaPCR = PCALoadings(:,1:k) * betaPCR;
betaPCR = [mean(T_train)-mean(P_train) * betaPCR;betaPCR];
%%
% 2. 预测拟合
N = size(P_test,1);
T_sim = [ones(N,1) P_test] * betaPCR;
%% VI. 结果分析与绘图
%%
% 1. 相对误差error
error = abs(T_sim - T_test) ./ T_test;
%%
% 2. 决定系数R^2
R2 = (N * sum(T_sim .* T_test) - sum(T_sim) * sum(T_test))^2 / ((N * sum((T_sim).^2) - (sum(T_sim))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
%%
% 3. 结果对比
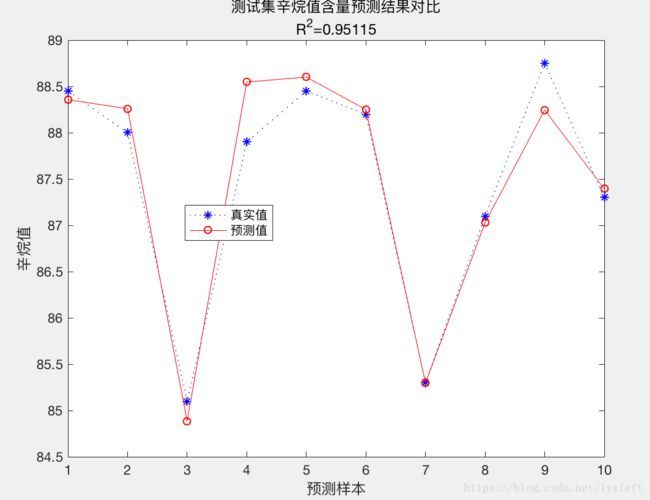
result = [T_test T_sim error]
%%
% 4. 绘图
figure
plot(1:N,T_test,'b:*',1:N,T_sim,'r-o')
legend('真实值','预测值','location','best')
xlabel('预测样本')
ylabel('辛烷值')
string = {'测试集辛烷值含量预测结果对比';['R^2=' num2str(R2)]};
title(string)
(由于代码中训练集和测试集是随机划分的,所以结果可能不同。)
大家使用时,只需要替换:
N = size(P_test,1);
T_sim = [ones(N,1) P_test] * betaPCR;
改成自己的数据集。
【例】偏最小二乘法(PLS)
同样的例子,编程实现PLS:
%% I. 清空环境变量
clear all
clc
%% II. 导入数据
load spectra;
%% III. 随机划分训练集与测试集
temp = randperm(size(NIR, 1));
% temp = 1:60;
%%
% 1. 训练集――50个样本
P_train = NIR(temp(1:50),:);
T_train = octane(temp(1:50),:);
%%
% 2. 测试集――10个样本
P_test = NIR(temp(51:end),:);
T_test = octane(temp(51:end),:);
%% IV. PLS回归模型
%%
% 1. 创建模型
k = 2;
[Xloadings,Yloadings,Xscores,Yscores,betaPLS,PLSPctVar,MSE,stats] = plsregress(P_train,T_train,k);
%%
% 2. 主成分贡献率分析
figure
percent_explained = 100 * PLSPctVar(2,:) / sum(PLSPctVar(2,:));
pareto(percent_explained)
xlabel('主成分')
ylabel('贡献率(%)')
title('主成分贡献率')
%%
% 3. 预测拟合
N = size(P_test,1);
T_sim = [ones(N,1) P_test] * betaPLS;
%% V. 结果分析与绘图
%%
% 1. 相对误差error
error = abs(T_sim - T_test) ./ T_test;
%%
% 2. 决定系数R^2
R2 = (N * sum(T_sim .* T_test) - sum(T_sim) * sum(T_test))^2 / ((N * sum((T_sim).^2) - (sum(T_sim))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
%%
% 3. 结果对比
result = [T_test T_sim error]
%%
% 4. 绘图
figure
plot(1:N,T_test,'b:*',1:N,T_sim,'r-o')
legend('真实值','预测值','location','best')
xlabel('预测样本')
ylabel('辛烷值')
string = {'测试集辛烷值含量预测结果对比';['R^2=' num2str(R2)]};
title(string)
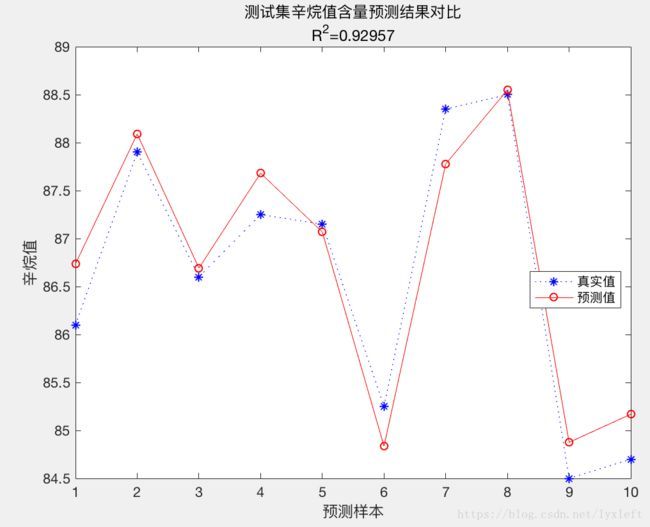
在上述两个方法中,我们可以做一个对比:若将训练集和测试集选定不变,采用PLS和PCR方法同时运行,可以发现PLS所需的主成分更少,而且准确率更高。可见考虑了主成分对输出矩阵的贡献后,PLS性能更强。请大家自行修改程序操作一下,比较简单,这里就不贴代码了。
特征选择的方法
Filter vs. Wrapper
最经典的两种特征选择的思路。
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
Wrapper需要建立学习模型,通过模型的性能进行评价特征的优劣。
Filter无需利用学习模型的性能,即可进行特征选择,主要依赖一些评价准则,如:相关系数、互信息、信息熵等。
举个例子,决策树中采用了信息熵的准则,它就是Filter的一种。
搜索法
随机搜索
如遗传算法。遗传算法特征选择概述:
• 将N个输入变量用一个长度为N的染色体表示,染色体的每一位代表一个输入变量。
• 每一位的基因取值只能是“1”和“0”两种情况。这一步要注意如何转化,比如如何将二进制编码转化为0或1。
• 如果染色体的某一位值为“1”,表示该位对应的输入变量被选中,参与模型建立。
• 反之,如果染色体的某一位值为“0”,则表示对应的输入变量未被选中,不参与模型建立。
启发式搜索
• 前向选择法
- 自下而上的选择方法,又称集合增加法。
- 特征集合初始化为一个空集。
- 每次向特征集合中添加一个输入变量,当新加入的变量致使模型性能更优时,则保留该输入变量,否则不保留。
举例:输入500x30的矩阵,即500个样本,每个有30维的特征(变量)x1,x2,...,x30。
那么我们先随便选择一个特征x1(30维的向量),计算它映射到输出Y的模型,并计算偏差err1(或自己设计的评价指标)。
然后我们增加一个特征x2,组成{x1 x2},计算它映射到输出Y的模型,并计算偏差err2,比较err2和err1。如果err2更小了,那就决定使用{x1 x2}这个新组合。否则就放弃x2。
以此类推,不断扩充我们的集合,从而得到最佳的特征变量组合,比如{x1,x2,x5,x10...x29}。
• 后向选择法
- 自上而下的选择方法,又称集合缩减法
- 特征集合初始化为全部的输入变量
- 每次从特征集合中剔除一个输入变量,当剔除后致使模型性能更优时,则剔除该输入变量,否则保留该输入变量。
这个方法和前向选择法是相反的,很好理解了,就不举例了。
• 广义方法
上述前向或者后向选择方法有些缺点。比如,x1和x2组合效果不好,我们剔除了x2,但是x1,x2,x3的效果实际上很好,但是我们已经回不去了。本质上讲,我认为这种缺点源于它们方法中的单一顺序操作。所以又有大牛发明了以下两种广义方法:
1)一次增加或剔除多个变量
这个很好理解,就是字面意思。
2)区间法
将30个特征分成几组,组之间可能有一些关联。分别计算每组对Y的贡献。如果贡献不大,我们就将这一组全部剔除!
区间法一定程度上可以缩减工作量。
区间法在化学分析、光谱分析中比较常用。比如,我们之前做到的汽油的辛烷值预测的例子中,我们知道物体的吸收光谱变化明显的其实就几个地方,401维特征实在太多了,如果分个组,就可以把几乎没有作用的几个区间的特征值给剔除掉,大大减少工作量。
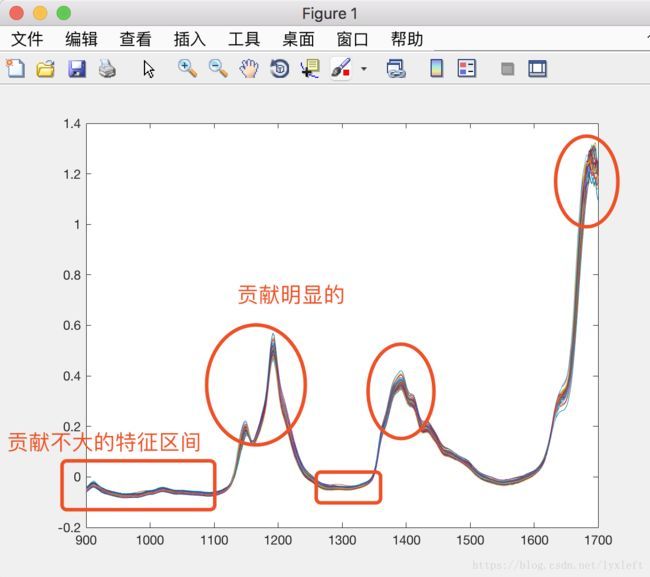
区间的宽度怎么设置,区间如何划分?是区间法要研究的关键问题。可以查阅相关的文献。
正则化方法
L1范数、LASSO、稀疏优化……
此处不展开讲,大家自行查阅相关文献。
关于正则化方法,我觉得还是很有必要了解一下:
《深度学习:正则化方法》
《正则化方法:L1和L2 regularization、数据集扩增、dropout》
参考文献:
N. Meinshausen, P. Buhlmann, “Stability selection”, Journal of the Royal Statistical Society, 72 (2010)
F. Bach, “Model-Consistent Sparse Estimation through the Bootstrap”
推荐:https://www.cnblogs.com/stevenlk/p/6543628.html
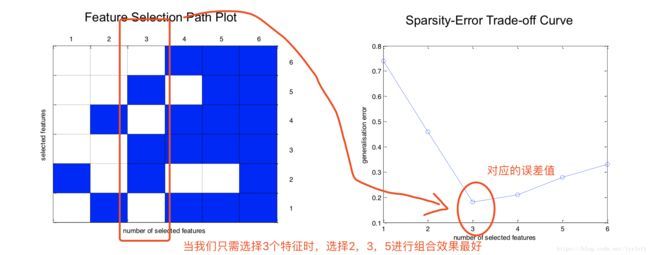
可视化评价指标
当我们选择好变量组合后,如何直观地看出其性能好坏?
可以用好两个可视化工具:FSP Plot and SET Curve
常用数据集(本博客中其他机器学习算法实例代码通用):
链接:https://pan.baidu.com/s/1wqVzwcL1xQ_Uh50XoYqyrw 密码:5wq2
链接:https://pan.baidu.com/s/1XwhynjKuJOVsa5Nxi9NVaA 密码:d0u7