菜菜学paddle第五篇:卷积神经网络概念深度解析
前言:
计算机视觉作为一门让机器学会如何去“看”的学科,具体的说,就是让机器去识别摄像机拍摄的图片或视频中的物体,检测出物体所在的位置,并对目标物体进行跟踪,从而理解并描述出图片或视频里的场景和故事,以此来模拟人脑视觉系统。因此,计算机视觉也通常被叫做机器视觉,其目的是建立能够从图像或者视频中“感知”信息的人工系统。
对人类来说,识别猫和狗是件非常容易的事。那么对计算机来说,如何让计算机也能像人一样看懂周围的世界呢?
卷积神经网络的定义:
1、数学定义:
“卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一”。你会不会蒙圈?什么是卷积计算?我们先搁置一旁。
2、生物学定义:
卷积神经网络是计算机视觉技术最经典的模型结构,它仿照生物的视知觉(visual perception)机制构建,通过卷积核提取输入数据的关键特征,经过多次网络的转换,得到我们想要的输出。类似于我们人观察识别一个物体,总是提取它的关键特征。
卷积核:
卷积核(kernel)一般是二维的,假设卷积核的高和宽分别为H和W,则将其称为H*W卷积,比如3*5的卷积,就是指卷积核的高为3, 宽为5。有些地方也被叫做过滤器(filter),其实二者是有差别的,对于单通道输入的时候,二者是等价的,对于多通道输入的时候,过滤器是多维的,维度与通道数相同,而卷积核还是二维的。再直白一点:过滤器=通道数*卷积核,当通道数等于1的时候,二者是等价的。
卷积计算:
卷积是数学分析中的一种积分变换的方法,而在卷积神经网络中,卷积层的实现方式实际上是数学中定义的互相关 (cross-correlation)运算:

大家从图中就能看到,输入源是3*3的数组,卷积核大小是2*2,经过横向卷积和纵向卷积之后,最终得到2*2的输出结果,卷积的计算过程非常简单,对应位相乘再相加。
填充(padding)
从卷积计算上面的图中我们可以看到,3*3的图片被2*2卷积核卷积之后就变成了2*2的图片了,我们这样想一下,既然是多层网络,那么经过多次卷积之后,我们的输出数据会越来越小,有没有什么办法来解决呢?这就用到了填充。
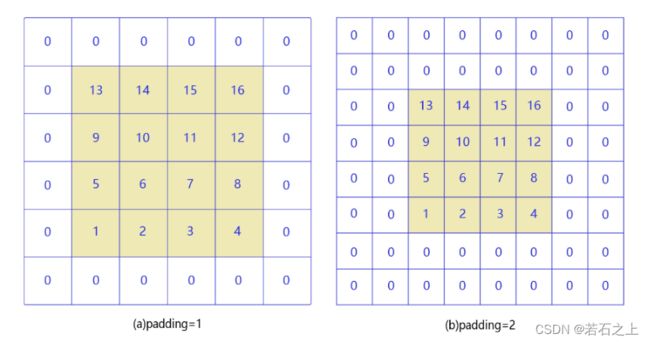
经过填充之后原始图片的大小就改变了,这样就能让我们的输出结果不会一直变小。
步幅(stride)
简单来说,步幅就是卷积核一次向右或者向下移动几个像素点,当然步幅大的话,计算的量级就会小很多。
感受野(Receptive Field)
输出特征图上每个点的数值,是由输入图片上大小为H*W的区域的元素与卷积核每个元素相乘再相加得到的,所以输入图像上H*W区域内每个元素数值的改变,都会影响输出点的像素值。我们将这个区域叫做输出特征图上对应点的感受野。
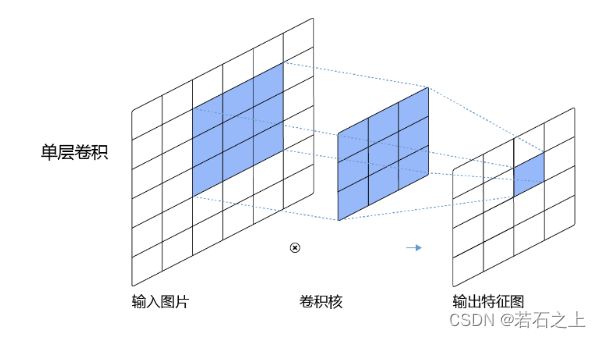
通俗一点理解就是输出的像素点是由受到输入多大的区域影响,上图就是一个3*3的感受野。
多输入通道
很多时候我们处理的数据是多通道的,对于黑白图片我们的输入数据是单通道的,但彩色图片有RGB三个通道。
多输出通道
为什么还有多输出通道呢?假如我们要对一张图片提取多维的特征,比如既提取动物,又提取植物,那么我们就需要2个过滤器,有时候我们也称作2个卷积核,那么输出的时候,就是两个通道。通常我们将卷积后的输出通道数叫做过滤器(卷积核)的个数。
批量操作
在卷积神经网络的计算中,通常将多个样本放在一起形成一个mini-batch进行批量操作
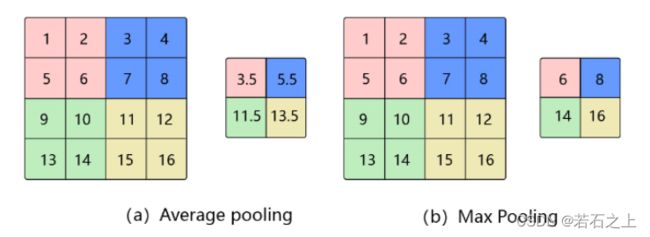
池化(Pooling)
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。常用的有最大池化、最小池化、平均池化:
批归一化(Batch Normalization)
对于深度神经网络来说,由于参数是不断更新的,即使输入数据已经做过标准化处理,但是对于比较靠后的那些层,其接收到的输入仍然是剧烈变化的,通常会导致数值不稳定,模型很难收敛。通常我们会对神经网络的数据进行标准化处理,处理后的样本数据集满足均值为0,方差为1的统计分布,这样当输入数据的分布比较固定时,有利于算法的稳定和收敛。BatchNorm能够使神经网络中间层的输出变得更加稳定,并有如下三个优点:
- 使学习快速进行(能够使用较大的学习率)
- 降低模型对初始值的敏感性
- 从一定程度上抑制过拟合
丢弃法(Dropout)
丢弃法(Dropout)是深度学习中一种常用的抑制过拟合的方法,其做法是在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元将不对外传递信号。
