李理:从Image Caption Generation理解深度学习(part I)

本系列文章希望通过Image Caption Generation,一个有意思的具体任务,来介绍深度学习的知识,涉及到很多深度学习流行的模型,如CNN,RNN/LSTM,Attention等。本文为第一篇。
作者李理,目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。李理也是MDCC 2016 移动开发者大会人工智能与机器人专场的出品人,邀请人工智能一线专家担任演讲嘉宾,从无人驾驶、智能机器人、智能应用开发实战等方面解读人工智能技术的内涵及其对移动开发工作的影响。敬请关注。(更多介绍详见:深扎实战技术 带你走进MDCC 2016移动开发者大会)
0. 前面的话
建丁让我写一篇深度学习相关小文章,目标读者是国内的开发者。刚接到这个任务时我是颇为忐忑的,写文章要讲究厚积薄发,如果“水之积也不厚”,“则其负大舟也无力”。因为我自知水平很有限,又不是在学校和科研机构做研究,只不过因为工作和个人的兴趣,对深度学习有一点点粗浅的了解,所以担心写出来的东西不但于人无益,甚至还让人误入歧途。但后来又一想,如果把自己作为一个深度学习的学习者,和对它感兴趣的普通开发者分享一些学习的经历,包括学习过程中遇到的问题,可能也是有一些意义的。毕竟读论文或者听学术大牛的讲座只能看到“成功”的经验,而且大部分开发者相对来说没有太多的背景知识,而很多圈内的人都是假设读者拥有这些知识的。但是对于普通的开发者来说,很多基础知识比如线性代数和微积分在上完大学后估计就还给老师了,因此可能理解起来难度更大。而从另外一个角度来说,工程师(开发者)和科学家(科研工作者)关注的点也是不一样的。科学家更关注理论的东西,比如一个模型是怎么提出来的,为什么要这么设计模型,这样的模型怎么转化成一个优化问题。而工程师则更关注这个东西能够做什么,具体这个优化问题怎么求解更高效。学术界每年有大量的论文发表,大量的idea被提出,其中有好有坏,有的工作可能看起来理论很漂亮,但实际应用起来很难;有些工作可能不被太多人关注,但却是某些工业界非常需要的。
另外从人工智能的发展来说,我个人觉得在传统行业的普及也是非常重要的。现在很多人工智能创业公司,很多想用人工智能创造一个全新的产品,比如早期类似Siri的语音助手到现在火热的机器人。但我个人觉得目前的人工智能的水平还很难做出达到用户预期的产品,尤其是很多初创公司吹牛吹得有些过分,导致用户期望过高,而真正使用产品后则形成巨大的反差。我觉得目前阶段人工智能更大的用处是提升现有系统,用我自己的话来说就是目前的人工智能只是锦上添花而不是雪中送碳。也就是说光靠人工智能是不能吸引用户来购买你的产品的。
比如现在国外很火的Amazon的智能音箱产品Echo,如果我不想买一个音箱,估计你很难这样说服我购买Echo——我们的Echo有非常智能的语音交互功能,可以问天气,可以设置闹钟,可以Uber打车,可以控制家里的智能冰箱。但是如果我想购买一个音箱,现在面临两个选择:一个是传统的音箱,另一个是Echo。那么你对我说Echo有多么牛逼的智能可能会打动我,反正也差不了多少钱,能有这么多听起来很酷炫的功能也挺不错的。
由于Echo的成功,国内很多人也想“山寨”一个类似的产品,不过可能很多人忽略了美国和中国的一些细小差异,那就是音箱似乎不是大城市居民的必备品。就我个人的朋友圈来说,每个家庭肯定都有个电视,但是有音箱寥寥无几。为什么会这样呢,因为中国的大城市居民大都是住楼房,很多老破小隔音效果都很差,你整个音箱弄家里还没high两分钟,估计邻居就该敲门了。倒是耳机,屌丝们挤公交地铁时的必备利器,也许会更好卖。
说了这么多,想表达的就是目前人工智能应该更多的提高现有产品。比如提到Google,大家可能会想到它收购的Deepmind的AlphaGo,但是我们可能没有意识到日常使用的很多产品中都使用了深度学习。比如搜索引擎的排序,邮件的智能回复生成,都大量使用了深度学习。而AlphaGo的作用则更多的是一种市场PR,一种宣传作用,让大家知道人工智能目前的一些进展,而现在AlphaGo团队则是想将其技术用到医疗行业帮助医生诊断疾病。
也就是说人工智能在未来也许就像计算机,互联网,云计算一样是一个非常基础的设施,在任何需要用机器来替代或者减少人力的场景都是有用武之地的。目前不论是国内还是国外,人工智能的人才都是非常稀缺的,而且都是集中在少数学校的实验室和大公司的研究院里。因此向普通开发者传播相关的知识就显得尤为重要。基于这样的考虑,虽然自己的能力不够,但还是愿意把自己学习的一些经验和问题向大家分享。
1. 为什么分享Image Caption Generation这个话题?
这篇小文章并没有限定什么范围,只要是深度学习相关的就行。这反倒让人烦恼,就和人生一样,选择太多了也是一种烦恼。因为最近工作有空之余正在学习斯坦福的课程CS231N,Convolutional Neural Networks for Visual Recognition。这个课程非常好,除了详尽的slides和notes,最值得一提的就是它的作业。每个作业包含完整的模型,比如CNN、LSTM,所有的模型的代码都只是用最简单的python代码实现,而不是用现成的库比如TensorFlow/Theano/Caffe。纸上得来终觉浅,绝知此事要躬行。很多理论,光听课看slides,似乎觉得自己懂了,其实还是一知半解,真正要掌握,就得自己动手,最好是全部自己实现。但是全部自己实现需要花的时间太多,而且从实际工作的角度来说,大部分开发者肯定都是用TensorFlow这样的工具。而这个课程的好处就是:把一些琐碎的与核心代码不相关的部分包括学习的框架都已经实现了,然后用IPython notebook把关键的代码的函数的输入和输出都描述的非常清楚,学习者只需要实现一个一个这样的函数就行了,而且每个函数都会有类似单元测试的检测代码正确性的数据,从而保证我们的每一步都是在朝着正确的方向前进。
因此这篇小文章打算讲一讲其中的Assignment3的Image Caption Generation部分。目的是想通过一个具体的任务来给大家介绍深度学习的一些知识,让大家对深度学习有一些概念和兴趣。选择Image Caption Generation的原因,一来这个任务挺有意思的;第二就是它涉及到很多深度学习流行的模型如CNN,RNN/LSTM,Attention。
首先来介绍一下什么叫做Image Caption Generation。
对于计算机视觉相关的任务,图片分类和定位大家可能比较熟悉。图片分类就是给定一张图片,让计算机告诉我们它是一只猫还是一只狗;而图片定位除了告诉我们这是一张狗的图片,还需要用用一个矩形框把狗的位置标识出来。当然还有要求更高的Image Segmentation,需要告诉我们哪一些像素属于狗,而另外一些属于背景。
图1就是这些任务的例子:
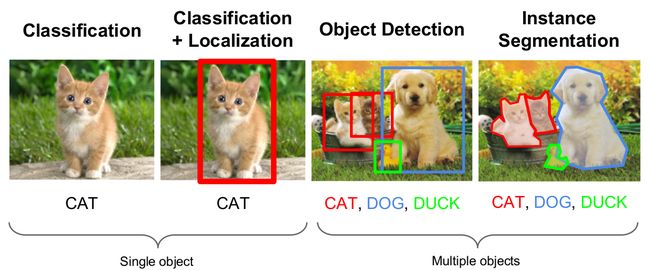
图1:常见机器视觉任务 图片来自 http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
而Image Caption Generation任务是给定一张图片,需要让计算机用一句话来描述这张图片。
如图2所示:

图2:Caption Generation任务示例 图片来自 http://mscoco.org/dataset/#captions-challenge2015
从实际的应用来说,这个任务也是很有用处的。比如一个手机拍完照片之后,我们可以用这个方法生成一句话来描述这个图片,方便分享和以后查找。
而从理论研究的角度来说,Caption Generation相对于之前的task来说需要更加深入“理解”图片中物体之间的关系,甚至包括一些抽象的概念。它把一幅信息量极大的图片压缩成短短一句话。
我是做自然语言处理(NLP)相关工作的,之前对计算机视觉有一些错误的看法。认为视觉信号是更底层和原始的信号,除了人类,动物也有很强的视觉能力,也能分辨不同物体。而语言是人类创造的符号系统,属于更高层的抽象,因而属于更高级的人工智能问题,似乎不少人会有类似的观点。
但是现在我有了一些不同的看法,人类的大脑并没有什么特殊之处。一个小孩在一岁之前一般不会说话,他认识世界的主要方式就是主要通过视觉系统来区分物体,也许和神经网络类似,通过复杂的神经元的连接来“理解”世界。这些不同层次的网络就是不同层次的特征,就像神经网络的“黑盒”,我们自己也很难用精确的语言描述我们大脑到底学习到了什么样的特征。而且很可能每个人学到的特征,尤其是底层的特征都是不相同的。
比如下图的一个汽车,最底层的特征可能是不同方向的线条,而中间层的特征可能是各种基本的形状,而更上层的特征就是车轮这样的更上层概念。

图片来自 http://cs231n.stanford.edu/slides/winter1516_lecture7.pdf
一个复杂的概念由一些简单的概念组合而成,而简单的概念可能由最基本的原子概念组合而成。语言就是对这些概念的描述,或者说就是一个标签,一种命名。但是语言有一个特点就是它是用来沟通和交流的,所以语言的使用者需要达成一定程度的共识。那怎么达成共识呢,比如我们在教小孩语言时是怎么与他达成共识的呢?比如一个桌子,我们通过手指这一个条狗狗,反复对小孩说“狗狗”这个词(其实是声音,为了简化,我们暂且当成文字),这样我们就和小孩达成了共识,“狗狗”就是指这样一个动物,然后又指着另外一条狗狗,也说“狗狗”,小孩就学到这一“类”物体都是狗狗。所以他需要调整他的神经元连接,使得那些符合某种特征的物体都被识别成狗狗。至于具体这个识别狗狗的神经网络的参数是什么样的,我们很难知道,也许刚开始他需要分类的物体很少,比如只有“爸爸”,“妈妈”和“狗狗”,那么它可能需要不是那么“本质”的特征来区分,比如他可能认为四条腿走的是“狗狗”,两条腿直立行走的就是“爸爸”和“妈妈”。当随着需要识别的类别的增多,比如有了“猫猫”,那他一上来可能认为也是“狗狗”,但父母告诉他分类错误,这不是“狗狗”而是“猫猫”。那么他可能需要别的特征来区分猫猫和狗狗,也许他学到的是:四条腿走并且嘴很长的是狗狗,而四条腿圆脸的是猫猫。
那为了能够区分猫猫和狗狗,小孩的中层的特征可能需要抽取类似“脸”的特征,或者说概念。我们也会告诉他这是狗狗的脸,这是猫猫的脸,这是爸爸的脸。这样他需要学习出脸的共性的特征。
从上面的过程我们可以发现,概念本身只是一种“特征”的指代,是我们的感觉系统(视觉)对一个物体的反应。而语言是一部分相似的生物对同一个/类物体达成共识的一种指代。但每个人的感觉系统和神经网络结构都是不一样的,所以也只能在非常粗糙的程度达成比较一致的共识,而在非常精细的概念层次是很难达成广泛共识的。因此我们会把周围的人打上各种标签,分成各种类别,由此各种概念也就产生——肤色,语言,宗教,性别,阶级。每个人也只能和同一个标签的人在某个方面达成共识,所以要找到一个完全“了解”自己的人是如此之难,而不同的物种的共识可能就更难了。所以就像《庄子·齐物论》里说的“毛嫱、丽姬,人之所美也;鱼见之深入,鸟见之高飞,麋鹿见之决骤。四者孰知天下之正色哉?自我观之,仁义之端,是非之涂,樊然殽乱,吾恶能知其辩!”毛嫱、丽姬是我们人类眼中的美,但是在鱼和雁看来只是可怕的敌人。可笑的是自恋的人类却还要曲解庄子的愿意,认为它们是因为惊异于她们的美丽才沉鱼落雁闭月羞花的。不说动物,即使是人类而言,美也是很难达成共识的,那些黑人国家的美女,我们中国人是很少会认为她们是美女的。
因此从这个意义上来说,语言也许并没有我们想像中的那么高大上。 就目前人工智能或者深度学习的水平来说,也许研究小孩在建立复杂概念之前的行为更有用处。
接下文:李理:从Image Caption Generation理解深度学习(part II)
更多详细内容,请持续关注MDCC大会官网, 9 月 4 日零点前,MDCC 大会门票处于 6.8 折优惠票价阶段,五人以上团购更有特惠,限量供应(票务详情链接,欲购从速!)
