RepLKNet论文详解:31×31的超大卷积核模型
一切都是为了顺利毕业而努力!这个读作Rep L P Net
论文名称:Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
原论文地址:https://arxiv.org/pdf/2203.06717.pdf
代码:GitHub - DingXiaoH/RepLKNet-pytorch: Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs (CVPR 2022)
目录
1. 论文主要干啥
2.大卷积核架构设计原因
2.1 优势
2.2 问题
2.3 大卷积核架构指代原则
3. RepLKNet整体架构
4. 总结
1. 论文主要干啥
(1)在卷积神经网络中,采用少量大卷积是比大量小卷积更好
(2)提出大卷积核神经网络架构RepLKNet,其卷积核尺寸能达到31*31,在分类,检测,分割上均显著强于传统的CNN架构,取得了和主流Vision Transformers相似或者更强的性能,运行的效率更高
(3)对于Vit 来说,Self-attention模块的大感受野是它取得优异性能的重要原因,在使用了大卷积核的设计之后,CNN架构也可以拥有相当的性能,并且在Shape bias等方面和Vit 的表现更为接近
2.大卷积核架构设计原因
2.1 优势
(1)相比直接加深,大卷积核可以更高效的提升有效感受野
根据有效感受野理论,有效感受野的尺寸正比于卷积核尺寸,跟卷积核的层数开根号成正比,就是说通过添加深度的方式提高感受野,不如直接把卷积核拉大对感受野的提升更为有效。
(2)大卷积核可以部分回避模型深度增加带来的优化难题
ResNet看起来可以做的很深,或者可以达到成百上千层,但是他的有效深度并不深,它的很多信号是shortcut层过去的,它并没有增加它的有效深度,如图,把ResNet从101层提高到152层,虽然深度提升了很多,但是他的有效感受野大小其实基本不变,但是如果把卷积核尺寸增大,从13增加到31,有效感受野扩大的趋势就非常显著。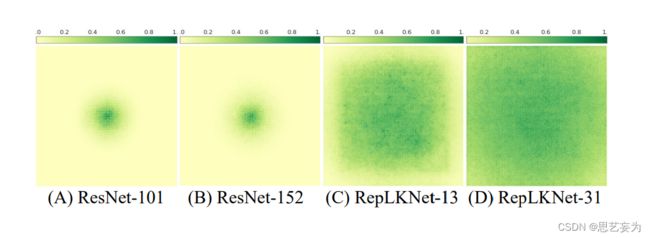
(3)大卷积核对FCN-based(全卷积)的视觉下游任务提升更明显
2.2 问题
(1)大卷积核不够高效:计算量成倍增加
(2)大卷积核难以兼顾局部特征,容易出现过度平滑
(3)相比自注意力模块,卷积的归纳偏置过强,限制了在大数据集上的表示能力
2.3 大卷积核架构指导原则
(1)使用Depthwise等结构稀疏化卷积,辅以恰当的底层优化
(2)Identity shortcut在大卷积核设计中非常重要
(3)用小卷积核做重参数化,避免过度平滑的问题
(4)关注下游任务的性能,不能只看 ImageNet 点数高低
对下游任务来说,感受野越大越好,大卷积核可以带来更大的感受野;对分类任务来说,形状比较重要,但是传统的CNN更多的是学习到纹理特征,增加卷积核可以使网络学习到更多的形状信息。
(5)在小feature map(特征图)上也可以用大卷积,常规分辨率就能训练大卷积核模型
基于以上准则,参考 Swin Transformer 的宏观架构,提出了一种架构 RepLKNet,区别就是使用很大的Depthwise卷积,取代了Swin Transformer自带的window attention,用重参数化技术来重参数化大卷积,在推理的时候这些小卷积核将会吸收进大卷积,因此不会带来额外的计算复杂度。
3. RepLKNet整体架构
整体形式参考的Swin Transformer结构。主要在于把 attention 换成超大卷积和与之配套的结构,再加一点 CNN 风格的改动。根据以上五条准则,RepLKNet 的设计元素包括 shortcut、Depthwise超大 kernel、小 kernel 重参数化等。

RepLKNet的结构如图所示,各模块细节如下:
(1)Stem:由于RepLKNet的主要应用是下游任务,所以需要在网络前期捕捉更多的细节。在开始的stride=2 3x3卷积下采样之后接一个3x3深度卷积来提取低维特征,之后接一个1x1卷积和3x3深度卷积用于下采样
(2)Stages 1-4:RepLKNet的核心层,由RepLK Block以及ConvFFN堆叠而成,RepLK Block 包含了归一化层、1×1卷积和深度可分离卷积,以及最重要的残差连接。
根据准则3,每个深度卷积并行一个5x5深度卷积用于结构重参数。除了感受域和空间特征提取能力,模型的特征表达能力还和特征的维度有关。为了增加非线性和通道间的信息交流,在深度卷积前用1x1卷积增加特征维度。
(3)ConvFFN:参考transformers和MLPs网络使用的Feed-Forward Network(FFN),论文提出CNN风格的ConvFFN,包含短路连接、两个1x1卷积核GELU,使用了1×1卷积替代全连接层。同样的ConvFFN也使用了层间的残差连接。在应用时,ConvFFN的中间特征一般为输入的4倍。参照ViT和Swin,将ConvFFN放置在每个RepLK Block后面。
(4)Transition Blocks:放在stage之间,先用1x1卷积扩大特征维度,再通过两个3x3深度卷积来进行2倍下采样。
4. 总结
(1)大卷积有更大的感受野:单层大卷积核要比多层小卷积更有效。
(2)大卷积能够学到更多的形状信息:大卷积核的RepLKNet更注重形状特征,当卷积核减少时,RepLKNet-3则变为更注重上下文特征。
(3)密集(普通)卷积和空洞卷积:空洞卷积在相邻的卷积核中插入孔洞,使得原卷积核拥有了更大的感受野,是一个常用的扩大卷积范围的方法,论文对空洞深度卷积和普通深度卷积进行了对比,尽管最大感受域可能一样,但空洞深度卷积的表达能力要弱很多,准确率下降非常明显,也就是说虽然空洞卷积的感受域较大,但其计算用的特征非常少。RepLKNet用深度可分离卷积重新思考了大卷积核的使用,同样是扩大感受野,RepLKNet则取得了更好的效果,纯空洞卷积组成的MobileNet V2效果比原模型更差。这个空洞卷积还挺有意思的,等整明白了写一篇,先留着。
以上,over,水一篇,我能行!