Yolo X目标检测系统【详解】
文章目录
-
- 一、网络结构
-
- 1、主干网络(backbone)
-
- 1.1 BottleNeck
- 1.2 CSPnet
- 1.3 Focus结构
- 1.4 Silu激活函数
- 1.5 SPP结构
- 1.6 整个主干网络(backbone)实现代码
- 2、FPN(特征金字塔)
- 3、利用Yolo Head获得预测结果
- 二、预测结果的解码
-
- 1、获得预测框与得分
- 2、得分筛选与非极大抑制(NMS)
YoloX的网络结构如下,除了YoloHead采用了回归和分类的解耦,其他网络结构和YoloV5相同,

一、网络结构
1、主干网络(backbone)
下面介绍主干网络用到的网络结构
1.1 BottleNeck
作用:
1、结合不同层次的信息,使网络做的更深;
2、残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率;
3、其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。

import torch
import torch.nn as nn
class BottleNeck(nn.Module):
def __init__(self, c1, c2, e, shortcut=True):
super(BottleNeck, self).__init__()
c_ = int(c1 * e)
self.conv1 = nn.Conv2d(c1, c_, 1, 1)
self.conv2 = nn.Conv2d(c_, c2, 3, 1, 1)
self.add = shortcut and c1 == c2
def forward(self, x):
x = self.conv2(self.conv1(x))
return x + self.conv2(self.conv1(x)) if self.add else self.conv2(self.conv1(x))
if __name__ == '__main__':
x = torch.randn(2, 3, 3, 3)
out = BottleNeck(3, 3, 0.5)(x)
print(out.shape)
输出:
torch.Size([2, 3, 3, 3])
1.2 CSPnet
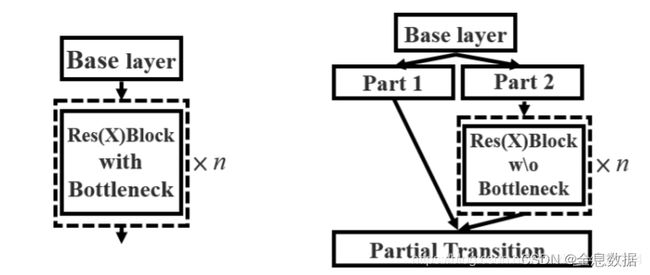
作用:
1、
过程:
1、输入的feature map先做1×1卷积,然后再进行Bottleneck,得到f1;
2、输入的feature map只做1×1卷积,得到f2;
3、对f1和f2进行堆叠,再进行1×1卷积得到f3;
class CspNet(nn.Module):
def __init__(self, c1, c2, e, n=1):
super(CspNet, self).__init__()
c_ = int(c1 * e)
self.conv1 = nn.Conv2d(c1, c_, 1, 1)
self.conv2 = nn.Conv2d(c1, c_, 1, 1)
self.conv3 = nn.Conv2d(2 * c_, c2, 1, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, 0.5) for _ in range(n)])
def forward(self, x):
return self.conv3(torch.cat((self.m(self.conv1(x)), self.conv2(x)), dim=1))
if __name__ == '__main__':
x = torch.randn(2, 5, 3, 3)
print(x.shape)
out = CspNet(5, 5, 0.5)(x)
print(out.shape)
输出:
torch.Size([2, 5, 3, 3])
torch.Size([2, 5, 3, 3])
1.3 Focus结构
定义:
使用了Focus网络结构,这个网络结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道,下图很好的展示了Focus结构,一看就能明白。

import torch
import torch.nn as nn
class Focus(nn.Module):
def __init__(self, c1, c2):
super(Focus, self).__init__()
self.conv1 = nn.Conv2d(c1 * 4, c2, 1, 1)
def forward(self, x):
return self.conv1(
torch.cat((x[..., ::2, ::2], x[..., ::2, 1::2], x[..., 1::2, ::2], x[..., 1::2, 1::2]), dim=1))
if __name__ == '__main__':
x = torch.randn(2, 3, 4, 4)
print(x.shape)
out = Focus(3, 3)(x)
print(out.shape)
输出:
torch.Size([2, 3, 4, 4])
torch.Size([2, 3, 2, 2])
1.4 Silu激活函数
silu激活函数结合了relu和sigmoid函数,具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。
f ( x ) = x ⋅ s i g m o i d ( x ) f(x)=x\cdot sigmoid(x) f(x)=x⋅sigmoid(x)
import matplotlib.pyplot as pl
import torch
import torch.nn as nn
import numpy as np
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
# x=torch.randn(2,3,3,3)
x = np.linspace(-10, 10, 100)
out = SiLU.forward(torch.from_numpy(x))
print(out.shape) # torch.Size([100])
fig = pl.figure()
pl.plot(x, out)
pl.show()
输出:

1.5 SPP结构
定义:
使用不同大小的池化核对feature map分别进行池化,然后进行堆叠之后再卷积;
作用:
通过不同大小的池化核进行池化,会提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self, c1, c2, k=[5, 7, 13]):
super(SPP, self).__init__()
c_ = int(c1 // 2) # hidden channel
self.conv1 = nn.Conv2d(c1, c_, 1, 1)
self.conv2 = nn.Conv2d(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=_, stride=1, padding=_ // 2) for _ in k])
def forward(self, x):
x = self.conv1(x)
return self.conv2(torch.cat([x] + [m(x) for m in self.m], dim=1))
if __name__ == '__main__':
x = torch.randn(2, 3, 26, 26)
out = SPP(3, 3)(x)
print(out.shape)
输出:
torch.Size([2, 3, 26, 26])
1.6 整个主干网络(backbone)实现代码
import torch
from torch import nn
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def get_activation(name="silu", inplace=True):
if name == "silu":
module = SiLU()
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class Focus(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
patch_top_left = x[..., ::2, ::2]
patch_bot_left = x[..., 1::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat((patch_top_left, patch_bot_left, patch_top_right, patch_bot_right,), dim=1,)
return self.conv(x)
class BaseConv(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"):
super().__init__()
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=ksize, stride=stride, padding=pad, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class DWConv(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(in_channels, in_channels, ksize=ksize, stride=stride, groups=in_channels, act=act,)
self.pconv = BaseConv(in_channels, out_channels, ksize=1, stride=1, groups=1, act=act)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class SPPBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2) for ks in kernel_sizes])
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, in_channels, out_channels, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
class CSPLayer(nn.Module):
def __init__(self, in_channels, out_channels, n=1, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
module_list = [Bottleneck(hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act) for _ in range(n)]
self.m = nn.Sequential(*module_list)
def forward(self, x):
x_1 = self.conv1(x)
x_2 = self.conv2(x)
x_1 = self.m(x_1)
x = torch.cat((x_1, x_2), dim=1)
return self.conv3(x)
class CSPDarknet(nn.Module):
def __init__(self, dep_mul, wid_mul, out_features=("dark3", "dark4", "dark5"), depthwise=False, act="silu",):
super().__init__()
assert out_features, "please provide output features of Darknet"
self.out_features = out_features
Conv = DWConv if depthwise else BaseConv
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
# stem
self.stem = Focus(3, base_channels, ksize=3, act=act)
# dark2
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2, act=act),
CSPLayer(base_channels * 2, base_channels * 2, n=base_depth, depthwise=depthwise, act=act),
)
# dark3
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2, act=act),
CSPLayer(base_channels * 4, base_channels * 4, n=base_depth * 3, depthwise=depthwise, act=act),
)
# dark4
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2, act=act),
CSPLayer(base_channels * 8, base_channels * 8, n=base_depth * 3, depthwise=depthwise, act=act),
)
# dark5
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2, act=act),
SPPBottleneck(base_channels * 16, base_channels * 16, activation=act),
CSPLayer(base_channels * 16, base_channels * 16, n=base_depth, shortcut=False, depthwise=depthwise, act=act),
)
def forward(self, x):
outputs = {}
x = self.stem(x)
outputs["stem"] = x
x = self.dark2(x)
outputs["dark2"] = x
x = self.dark3(x)
outputs["dark3"] = x
x = self.dark4(x)
outputs["dark4"] = x
x = self.dark5(x)
outputs["dark5"] = x
return {k: v for k, v in outputs.items() if k in self.out_features}
if __name__ == '__main__':
x = torch.randn(2, 3, 640, 640)
out = CSPDarknet(1, 1)(x)
print(out["dark3"].shape)
print(out["dark4"].shape)
print(out["dark5"].shape)
输出:
torch.Size([2, 256, 80, 80])
torch.Size([2, 512, 40, 40])
torch.Size([2, 1024, 20, 20])
2、FPN(特征金字塔)

作用:进行加强特征提取,不同shape的特征层进行特征融合,有利于提取出更好的特征。
过程:
在特征利用部分,YoloX提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分CSPdarknet的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
在获得三个有效特征层后,我们利用这三个有效特征层进行FPN层的构建,构建方式为:
feat3=(20,20,1024)的特征层进行1次1X1卷积调整通道后获得P5,P5进行上采样UmSampling2d后与feat2=(40,40,512)特征层进行结合,然后使用CSPLayer进行特征提取获得P5_upsample,此时获得的特征层为(40,40,512)。
P5_upsample=(40,40,512)的特征层进行1次1X1卷积调整通道后获得P4,P4进行上采UmSampling2d后与feat1=(80,80,256)特征层进行结合,然后使用CSPLayer进行特征提取P3_out,此时获得的特征层为(80,80,256)。
P3_out=(80,80,256)的特征层进行一次3x3卷积进行下采样,下采样后与P4堆叠,然后使用CSPLayer进行特征提取P4_out,此时获得的特征层为(40,40,512)。
P4_out=(40,40,512)的特征层进行一次3x3卷积进行下采样,下采样后与P5堆叠,然后使用CSPLayer进行特征提取P5_out,此时获得的特征层为(20,20,1024)。
class YOLOPAFPN(nn.Module):
def __init__(self, depth=1.0, width=1.0, in_features=("dark3", "dark4", "dark5"), in_channels=[256, 512, 1024], depthwise=False, act="silu"):
super().__init__()
self.backbone = CSPDarknet(depth, width, depthwise=depthwise, act=act)
self.in_features = in_features
self.in_channels = in_channels
Conv = DWConv if depthwise else BaseConv
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.lateral_conv0 = BaseConv(int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act)
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
self.reduce_conv1 = BaseConv(int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act)
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
self.bu_conv2 = Conv(int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act)
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
self.bu_conv1 = Conv(int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act)
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
def forward(self, input):
out_features = self.backbone.forward(input)
features = [out_features[f] for f in self.in_features]
[feat1, feat2, feat3] = features
P5 = self.lateral_conv0(feat3)
P5_upsample = self.upsample(P5)
P5_upsample = torch.cat([P5_upsample, feat2], 1)
P5_upsample = self.C3_p4(P5_upsample)
P4 = self.reduce_conv1(P5_upsample)
P4_upsample = self.upsample(P4)
P4_upsample = torch.cat([P4_upsample, feat1], 1)
P3_out = self.C3_p3(P4_upsample)
P3_downsample = self.bu_conv2(P3_out)
P3_downsample = torch.cat([P3_downsample, P4], 1)
P4_out = self.C3_n3(P3_downsample)
P4_downsample = self.bu_conv1(P4_out)
P4_downsample = torch.cat([P4_downsample, P5], 1)
P5_out = self.C3_n4(P4_downsample)
return (P3_out, P4_out, P5_out)
if __name__ == '__main__':
x = torch.randn(2, 3, 640, 640)
out =YOLOPAFPN()(x)
for item in out:
print(item.shape)
输出:
torch.Size([2, 256, 80, 80])
torch.Size([2, 512, 40, 40])
torch.Size([2, 1024, 20, 20])
3、利用Yolo Head获得预测结果
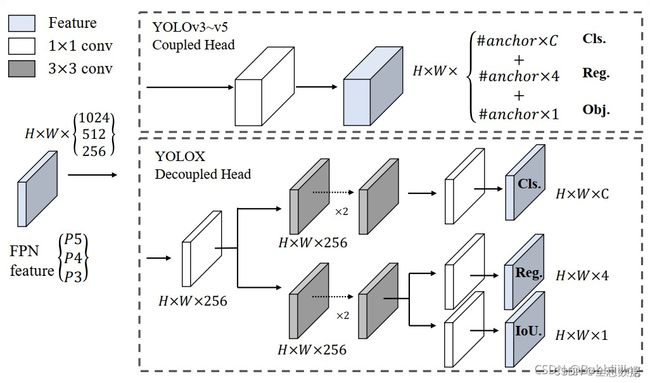
不同于其他Yolo版本预测的tensor,在YoloX中,回归参数、判断物体的置信度参数、类别的参数的tensor是分别卷积输出的,如下图,然后再把回归参数、判断物体的置信度参数、类别的参数进行concat,
下面参考于链接:
利用FPN特征金字塔,我们可以获得三个加强特征,这三个加强特征的shape分别为(20,20,1024)、(40,40,512)、(80,80,256),然后我们利用这三个shape的特征层传入Yolo Head获得预测结果。
YoloX中的YoloHead与之前版本的YoloHead不同。以前版本的Yolo所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现,YoloX认为这给网络的识别带来了不利影响。在YoloX中,Yolo Head被分为了两部分,分别实现,最后预测的时候才整合在一起。
对于每一个特征层,我们可以获得三个预测结果,分别是:
1、Reg(h,w,4)用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框。
2、Obj(h,w,1)用于判断每一个特征点是否包含物体。
3、Cls(h,w,num_classes)用于判断每一个特征点所包含的物体种类。
将三个预测结果进行堆叠,每个特征层获得的结果为:
Out(h,w,4+1+num_classses)前四个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;第五个参数用于判断每一个特征点是否包含物体;最后num_classes个参数用于判断每一个特征点所包含的物体种类。
class YOLOXHead(nn.Module):
def __init__(self, num_classes, width=1.0, in_channels=[256, 512, 1024], act="silu", depthwise=False, ):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
self.cls_preds = nn.ModuleList()
self.reg_preds = nn.ModuleList()
self.obj_preds = nn.ModuleList()
self.stems = nn.ModuleList()
for i in range(len(in_channels)):
self.stems.append(
BaseConv(in_channels=int(in_channels[i] * width), out_channels=int(256 * width), ksize=1, stride=1,
act=act))
self.cls_convs.append(nn.Sequential(*[
Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
]))
self.cls_preds.append(
nn.Conv2d(in_channels=int(256 * width), out_channels=num_classes, kernel_size=1, stride=1, padding=0)
)
self.reg_convs.append(nn.Sequential(*[
Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act)
]))
self.reg_preds.append(
nn.Conv2d(in_channels=int(256 * width), out_channels=4, kernel_size=1, stride=1, padding=0)
)
self.obj_preds.append(
nn.Conv2d(in_channels=int(256 * width), out_channels=1, kernel_size=1, stride=1, padding=0)
)
def forward(self, inputs):
# ---------------------------------------------------#
# inputs输入
# P3_out 80, 80, 256
# P4_out 40, 40, 512
# P5_out 20, 20, 1024
# ---------------------------------------------------#
outputs = []
for k, x in enumerate(inputs):
# ---------------------------------------------------#
# 利用1x1卷积进行通道整合
# ---------------------------------------------------#
x = self.stems[k](x)
# ---------------------------------------------------#
# 利用两个卷积标准化激活函数来进行特征提取
# ---------------------------------------------------#
cls_feat = self.cls_convs[k](x)
# ---------------------------------------------------#
# 判断特征点所属的种类
# 80, 80, num_classes
# 40, 40, num_classes
# 20, 20, num_classes
# ---------------------------------------------------#
cls_output = self.cls_preds[k](cls_feat)
# ---------------------------------------------------#
# 利用两个卷积标准化激活函数来进行特征提取
# ---------------------------------------------------#
reg_feat = self.reg_convs[k](x)
# ---------------------------------------------------#
# 特征点的回归系数
# reg_pred 80, 80, 4
# reg_pred 40, 40, 4
# reg_pred 20, 20, 4
# ---------------------------------------------------#
reg_output = self.reg_preds[k](reg_feat)
# ---------------------------------------------------#
# 判断特征点是否有对应的物体
# obj_pred 80, 80, 1
# obj_pred 40, 40, 1
# obj_pred 20, 20, 1
# ---------------------------------------------------#
obj_output = self.obj_preds[k](reg_feat)
output = torch.cat([reg_output, obj_output, cls_output], 1)
outputs.append(output)
return outputs
if __name__ == '__main__':
input=[torch.randn([2, 256, 80, 80]), torch.randn([2, 512, 40, 40]), torch.randn([2, 1024, 20, 20])]
out =YOLOXHead(80)(input)
for item in out:
print(item.shape)
输出:
torch.Size([2, 85, 80, 80])
torch.Size([2, 85, 40, 40])
torch.Size([2, 85, 20, 20])
二、预测结果的解码
YoloX对从Yolo Head出来的tensor的处理过程与YoloV2相似,首先对预测的 x p x^p xp, y p y^p yp, w p w^p wp, h p h^p hp进行归一化,
σ ( t x p ) = b x − C x , σ ( t y p ) = b y − C y \sigma(t^p_x)=b_x-C_x ,\sigma(t^p_y)=b_y-C_y σ(txp)=bx−Cx,σ(typ)=by−Cy t w p = l o g ( b w ) , t h p = l o g ( b h ) t^p_w=log(b_w),t^p_h=log(b_h) twp=log(bw),thp=log(bh)
σ ( t x p ) \sigma(t^p_x) σ(txp)的范围在0-1之间, C x C_x Cx的范围在0-19之间(以输出的torch.Size([2, 85, 20, 20])为例),所以 b x b_x bx的范围在0-20之间,接着对 b x b_x bx先除以20,然后再乘以起始输入图片的大小,即:
x i n i = b x 20 ⋅ 640 x_{ini}=\frac{b_x}{20}\cdot640 xini=20bx⋅640
以下内容摘录于参考博客,写得很好,
1、获得预测框与得分
在对预测结果进行解码之前,我们再来看看预测结果代表了什么,预测结果可以分为3个部分:
通过上一步,我们获得了每个特征层的三个预测结果。
本文以(20,20,1024)对应的三个预测结果为例:
1、Reg预测结果,此时卷积的通道数为4,最终结果为(20,20,4)。其中的4可以分为两个2,第一个2是预测框的中心点相较于该特征点的偏移情况,第二个2是预测框的宽高相较于对数指数的参数
2、Obj预测结果,此时卷积的通道数为1,最终结果为(20,20,1),代表每一个特征点预测框内部包含物体的概率。
3、Cls预测结果,此时卷积的通道数为num_classes,最终结果为(20,20,num_classes),代表每一个特征点对应某类物体的概率,最后一维度num_classes中的预测值代表属于每一个类的概率;
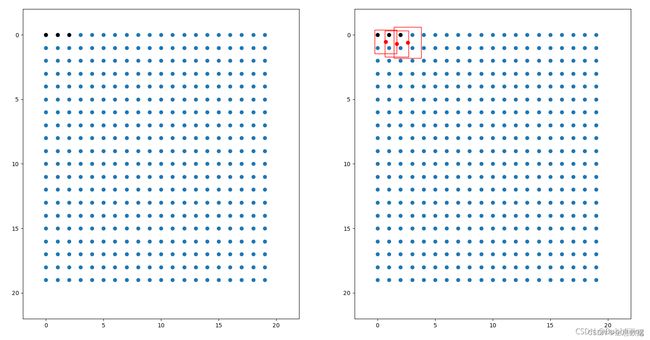
该特征层相当于将图像划分成20x20个特征点,如果某个特征点落在物体的对应框内,就用于预测该物体。
如图所示,蓝色的点为20x20的特征点,此时我们对左图红色的三个点进行解码操作演示:
1、进行中心预测点的计算,利用Regression预测结果前两个序号的内容对特征点坐标进行偏移,左图红色的三个特征点偏移后是右图绿色的三个点;
2、进行预测框宽高的计算,利用Regression预测结果后两个序号的内容求指数后获得预测框的宽高;
3、此时获得的预测框就可以绘制在图片上了。
def decode_outputs(outputs, input_shape):
grids = []
strides = []
hw = [x.shape[-2:] for x in outputs]
# ---------------------------------------------------#
# outputs输入前代表每个特征层的预测结果
# batch_size, 4 + 1 + num_classes, 80, 80 => batch_size, 4 + 1 + num_classes, 6400
# batch_size, 5 + num_classes, 40, 40 => batch_size, 4 + 1 + num_classes, 1600
# batch_size, 5 + num_classes, 20, 20 => batch_size, 4 + 1 + num_classes, 400
# batch_size, 4 + 1 + num_classes, 6400 + 1600 + 400 -> batch_size, 4 + 1 + num_classes, 8400
# 堆叠后为batch_size, 8400, 5 + num_classes
# ---------------------------------------------------#
outputs = torch.cat([x.flatten(start_dim=2) for x in outputs], dim=2).permute(0, 2, 1)
# ---------------------------------------------------#
# 获得每一个特征点属于每一个种类的概率
# ---------------------------------------------------#
outputs[:, :, 4:] = torch.sigmoid(outputs[:, :, 4:])
for h, w in hw:
# ---------------------------#
# 根据特征层的高宽生成网格点
# ---------------------------#
grid_y, grid_x = torch.meshgrid([torch.arange(h), torch.arange(w)])
# ---------------------------#
# 1, 6400, 2
# 1, 1600, 2
# 1, 400, 2
# ---------------------------#
grid = torch.stack((grid_x, grid_y), 2).view(1, -1, 2)
shape = grid.shape[:2]
grids.append(grid)
strides.append(torch.full((shape[0], shape[1], 1), input_shape[0] / h))
# ---------------------------#
# 将网格点堆叠到一起
# 1, 6400, 2
# 1, 1600, 2
# 1, 400, 2
#
# 1, 8400, 2 # grids的size
# ---------------------------#
grids = torch.cat(grids, dim=1).type(outputs.type())
strides = torch.cat(strides, dim=1).type(outputs.type()) # 1, 8400, 1
# ------------------------#
# 根据网格点进行解码
# ------------------------#
outputs[..., :2] = (outputs[..., :2] + grids) * strides
outputs[..., 2:4] = torch.exp(outputs[..., 2:4]) * strides
# -----------------#
# 归一化
# -----------------#
outputs[..., [0, 2]] = outputs[..., [0, 2]] / input_shape[1]
outputs[..., [1, 3]] = outputs[..., [1, 3]] / input_shape[0]
return outputs
2、得分筛选与非极大抑制(NMS)
得到最终的预测结果后还要进行得分排序与非极大抑制筛选。
得分筛选就是筛选出得分满足confidence置信度的预测框。
非极大抑制就是筛选出一定区域内属于同一种类得分最大的框。
得分筛选与非极大抑制的过程可以概括如下:
1、找出该图片中得分大于门限函数的框。在进行重合框筛选前就进行得分的筛选可以大幅度减少框的数量。
2、对种类进行循环,非极大抑制的作用是筛选出一定区域内属于同一种类得分最大的框,对种类进行循环可以帮助我们对每一个类分别进行非极大抑制。
3、根据得分对该种类进行从大到小排序。
4、每次取出得分最大的框,计算其与其它所有预测框的重合程度,重合程度过大的则剔除。
得分筛选与非极大抑制后的结果就可以用于绘制预测框了。
代码:
def non_max_suppression(prediction, num_classes, input_shape, image_shape, letterbox_image, conf_thres=0.5, nms_thres=0.4):
#----------------------------------------------------------#
# 将预测结果的格式转换成左上角右下角的格式。
# prediction [batch_size, num_anchors, 85]
#----------------------------------------------------------#
box_corner = prediction.new(prediction.shape)
box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2
box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2
box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2
box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2
prediction[:, :, :4] = box_corner[:, :, :4]
output = [None for _ in range(len(prediction))]
for i, image_pred in enumerate(prediction):
#----------------------------------------------------------#
# 对种类预测部分取max。
# class_conf [num_anchors, 1] 种类置信度
# class_pred [num_anchors, 1] 种类
#----------------------------------------------------------#
class_conf, class_pred = torch.max(image_pred[:, 5:5 + num_classes], 1, keepdim=True)
#----------------------------------------------------------#
# 利用置信度进行第一轮筛选
#----------------------------------------------------------#
conf_mask = (image_pred[:, 4] * class_conf[:, 0] >= conf_thres).squeeze()
if not image_pred.size(0):
continue
#-------------------------------------------------------------------------#
# detections [num_anchors, 7]
# 7的内容为:x1, y1, x2, y2, obj_conf, class_conf, class_pred
#-------------------------------------------------------------------------#
detections = torch.cat((image_pred[:, :5], class_conf, class_pred.float()), 1)
detections = detections[conf_mask]
nms_out_index = boxes.batched_nms(
detections[:, :4],
detections[:, 4] * detections[:, 5],
detections[:, 6],
nms_thres,
)
output[i] = detections[nms_out_index]
if output[i] is not None:
output[i] = output[i].cpu().numpy()
box_xy, box_wh = (output[i][:, 0:2] + output[i][:, 2:4])/2, output[i][:, 2:4] - output[i][:, 0:2]
output[i][:, :4] = yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image)
return output
参考:链接