Wavesplit: End-to-End Speech Separation by Speaker Clustering

0. Abstract
本文提出了一种端到端声源分离系统,Wavesplit。从混合语音中,模型推断每个声源的表示,然后根据每个声源的特征表示进一步估计声源,该模型经过训练,可以从原始波形中联合执行这两项任务。Wavesplit通过聚类推断一组声源的特征表示,其解决了声源分离的基本排列问题。在语音分离任务中,本文工作对长语音序列具有更加稳健的分离性能。本文模型在2人/3人纯净语音(WSJ0-2/3mix),以及带噪语音、混响语音数据集都获得STOA性能。
1. Introduction
设计的模型能够保持真实声源和预测声源之间的一致性分配,对局具有相似声源的任务至关重要(解决排列置换问题)。
本文工作旨在从混合信号中分离出具有相同性质的源(声源)。本文工作除了用于解决语音分离问题,还可应用于分离胎儿和母体心率。本文提出的Wavesplit用于解决说话人无关的语音分离问题,测试集中的声源未在训练时出现。具体来说,我们用于说话人识别和语音分离的联合训练程序不同于先前的研究。训练目标期望能够识别瞬时说话人的特征表示,以便(i) 这些表示可以分组到单个说话人集群中,并且 (ii) 集群质心为重建单个源提供长期说话人表示(long-term speaker representation)。对于每个声源的显式、长期表示的提取是一项新工作,其有利于语音和非语音的分离,这种表示限制了真实声源和预测声源之间不一致的问题。
本文贡献:
- (1)实现说话人无关训练。
- (2)aggregate information about sources over the whole input mixture which limits channel-swap.
- (3)本文使用聚类获得输出集合的声源表示(与顺序无关的预测)
- (4)在多个语音分离任务中获得STOA性能。for clean(WSJ0-2/3mix, Libri2/3mix clean) and noisy settings (WHAM and WHAMR, Libri2/3mix noisy)
- (5)分析了方法的经验优势和缺点
- (6)本文模型具有一定的通用性,也可应用到母体和胎儿的心率分离工作中。
2. Related work
2.1 Deep clustering approaches
这些方法设计了一种用于掩蔽的聚类模型:模型学习每个时频点的潜在特征表示,使得来自同一声源的时频点之间的距离低于来自不同声源的时频点之间的距离。然后通过聚类将这些特征表示聚类到组时频点。Deep Attractor Network 采用了类似的思路,并为每个源学习潜在吸引子特征表示,以便为每个时频点分配一个接近其源吸引子的表示【22,23】。论文【24】通过引入k-means的可微展开版本在训练时执行聚类。Wavesplit同样依赖于聚类来推断源的特征表示,但是这些特征表示不依赖频率点,且不执行掩码。该表示的作用为:
(1)预测训练说话者的身份
(2)为本文的分离卷积网络提供条件变量
[23] Y. Luo, Z. Chen, and N. Mesgarani, “Speaker-independent speech separation with deep attractor network,” IEEE/ACMTrans. Audio, Speech Lang. Process., vol. 26, no. 4, pp. 787–796, Apr. 2018.
[24] J. R. Hershey, J. L. Roux, S. Watanabe, S. Wisdom, Z. Chen, and Y. Isik, “Novel deep architectures in speech processing,” New Era Robust SpeechRecognition, ExploitingDeep Learn., 2017, pp. 135–164. [Online]. Available: https://doi.org/10.1007/978-3-319-64680-0_6
2.2 Permutation-Invariant Training
置换不变训练方法不需要聚类,而是直接预测多个掩码。通过搜索声源的不同排列,将预测与真实掩码进行比较,所有排列中,误差最小的一种用于模型训练。Wavesplit与PIT方法一样,在时域上对信号进行处理,但是本文方法在信号估计之前解决了标签置换问题:训练时,在调节分离网络之前对潜在声源的特征表示进行排序,从而与标签最佳匹配。
2.3 Discriminative speaker representations
论文【14】从纯净语音序列中提取目标说话人的特征表示,然后从混合语音中分离出该说话人。很多已有工作都是用于处理说话人相关的语音分离任务,wavesplit在训练中不需使用测试集中出现的说话人语音,即可实现语音分离。
2.4 Speaker separation in constrained settings
分离方法可能用于解决在线分离问题,这对于基于聚类的方法存在挑战性(效率限制因素)。此外,嘈杂环境中的语音分离同样是一个重要的应用领域。本文方法对于带噪以及混响环境数据集,实现了STOA性能。
2.5 Separation of fetal and maternal heart rates
3. Wavesplit

Wavesplit 包含两个卷积子网络:speaker stack 和 separation stack。speaker stack将混合语音映射到一组用于表示说话人的向量。后者处理混合语音以及speaker stack输出的说话人表示集合,进而产生分离语音。
后者是一种常用模型,类似于基于预训练的说话人向量【14】,或使用PIT训练的架构【11】。本文贡献的核心是speaker stack,该部分与后者进行联合训练。训练时,说话人标签用于学习每个说话人的向量表示,使得不同说话人之间的距离很大,而说话人内的距离很小。同时,这种特征表示还用于separation stack部分重建纯净信号。在测试阶段,speaker stack依赖于聚类来识别每个说话人的质心的表示。
3.1 Problem setting & notations
单声道语音的信号用向量 y i ∈ χ 1 , T y^i \in \chi^{1, T} yi∈χ1,T表示,其中 i ∈ [ 1 , N ] i \in [1, N] i∈[1,N],表示声源索引,T表示序列长度。混合语音信号用 x = ∑ i = 1 N y i x = \sum_{i=1}^{N}y^i x=∑i=1Nyi。
分离模型 f f f预测每个源的估计值,将其与参考值 { y i } i = 1 N \{y^i\}^N_{i=1} {yi}i=1N进行比较来评估质量:

其中q表示质量评价指标, S N S_N SN表示[1, N]上的排列空间。因为源的顺序是随机的,因此上式取所有排列的最大值。这里采用SDR(Signal-to-Distortion Ratio)作为评测指标。SDR定义式如下所示:
S D R ( y ^ , y ) = − 10 l o g 10 ( ∣ ∣ y − y ^ ∣ ∣ 2 ) + 10 l o g 10 ( ∣ ∣ y ∣ ∣ 2 ) SDR(\hat{y}, y)=-10log_{10}(||y-\hat{y}||^2)+10log_{10}(||y||^2) SDR(y^,y)=−10log10(∣∣y−y^∣∣2)+10log10(∣∣y∣∣2)
3.2 Model Architecture
Wavesplit是具有两个子网络(或堆栈)的残差卷积网络。第一个子网络将混合语音信号转化为每个说话人的特征表示,第二个子网络将混合输入信号转换为多个以说话者特征表示为条件的独立语音信号。
3.2.1 Speaker stack
该部分网络在每个时间步生成说话人的特征表示,然后对整个序列进行聚合。该子网络首先将输入信号 x = x t = 1 T x=x^T_{t=1} x=xt=1T映射到N个相同长度的维度为d的向量序列,例如:
![]()
其中N表示说话人数量,d是通过交叉验证选择的超参数。h为每个说话人在每个时间步生成一个特征表示,这里h不需要在序列中对说话人进行排序,例如,一个给定的说话人在时刻t可能用第一个向量 h t 1 h^1_t ht1表示,而在时刻 t ′ t' t′用第二个向量 h t ′ 2 h^2_{t'} ht′2表示。序列结束时,聚合步骤按说话者对所有向量进行分组,并为整个序列输出N个汇总向量。使用K-means聚类处理这些聚合向量,并返回N个聚类的中心:

**训练期间,不使用聚类。**说话人中心是通过说话人身份对说话人向量进行分组得出的,其依赖于Section III-C中描述的说话人训练目标。
3.2.2 Separation stack
该子网络将混合信号x和说话人中心c映射到一个N通道信号 y ^ \hat{y} y^:
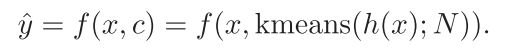
两个子网络使用残差卷积架构实现,每个残差块由一个扩张卷积dconv,一个非线性层nl和层归一化lnorm组成:
![]()
nl层使用参数化整流线性单元(PReLU, parametric rectified linear units)实现。第一部分子网络的最后一层使用Euclidean normalization处理说话人向量。
第二个子网络的残差块由依赖于(FiLM, Feature-wise Linear Modulation)的说话人中心进行调节。
![]()
其中 a = l i n ( c ) , b = l i n ′ ( c ) a=lin(c), b=lin'(c) a=lin(c),b=lin′(c)表示c的不同线性映射。
3.3 Model training objective
模型训练有两个目标:
(1)学习说话人向量,这些向量可以通过说话人身份聚类成不同的簇。
(2)优化从聚合的说话人向量中重建分离信号
Wavesplit假设训练数据使用有限的M个说话者身份进行注释,在测试时不需要对说话者进行注释。说话者身份信息在很多数据集中进行了标注,Wavesplit利用这些信息来构建每个声源的内部模型,并改善long-term separation。
speaker vector objective旨在让第一个子网络的输出实现同一说话人的距离尽量小,不同说话人的距离尽量大的目标。说话人损失函数定义如下,其有利于在每个时间步t正确识别说话人:
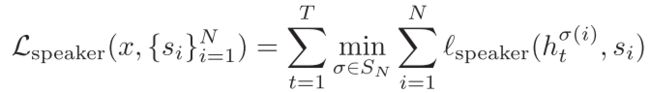
其中 l s p e a k e r l_{speaker} lspeaker在向量 R d R^d Rd和说话人身份[1, M]之间定义了一个损失函数。取最小值的操作针对不同的排列组合情况,每个时间步的最佳排列用于按照与训练标签一致的顺序对说话人向量进行重新排序。这种方式在训练时对源自同一说话人的说话人向量进行平均,与k-means聚类相比,这种优化方式更加简单。每个时间步的这种排列与PIT不同:模型不需要在输出源上选择单个排序,因为最终在说话人向量级别的源交换将通过k-means进行校正。此外,第二个子网络是从相同标签的不同排列中训练出来的。
本文为 l s p e a k e r l_{speaker} lspeaker探索了三种替代方案,每种方案在训练说话人上都维护了一个embedding 表 E ∈ R M × d E \in R^{M \times d} E∈RM×d。第一种, l s p e a k e r d i s t l_{speaker}^{dist} lspeakerdist是一种距离目标,该损失函数将让相同说话人的向量或对应嵌入向量的距离尽量小,同时令不同说话人的向量距离大于边界值1。

第二种, L s p e a k e r l o c a l L_{speaker}^{local} Lspeakerlocal是一种局部分类器目标,用于区分序列中存在的说话者,其依赖于说话人向量和嵌入向量之间距离的log softmax。

其中:
![]()
表示用学习的标量 α > 0 和 β \alpha > 0和 \beta α>0和β重新调整的平方欧几里得距离。
第三种,全局分类器目标 l s p e a k e r g l o b a l l_{speaker}^{global} lspeakerglobal与第二种类似,区别在于分配函数是在训练中所有说话人上计算的。

第一部分子网络使用 L s p e a k e r L_{speaker} Lspeaker损失函数进行训练更新。
第二部分子网络使用reconstruction objective进行优化更新,定义如下:

与PIT方法相比,该表达式不需要对置换空间进行搜索,因为质心c与标签的顺序一致。对于 l r e c o n s t r l_{reconstr} lreconstr,我们使用带有剪枝 τ \tau τ的负SDR来限制最佳训练预测的影响。
![]()
我们在第二个子网络的每一层计算 L r e c o n s t r L_{reconstr} Lreconstr,取所有层计算值的平均作为重构损失。
本文考虑使用不同形式的正则化来提高对新说话人的泛化能力。训练阶段,为每个说话人质心添加高斯噪声,用零替换full centroids(speaker dropout),此外,用来自同一batch的其它质心的线性组合来替换一些质心(speaker mixup)。无论序列中有多少说话人,speaker dropout操作最多删除一个质心。此外,我们支持使用熵正则化的well separated embeddings for training speakers:
![]()
3.4 Training Algorithm
模型的损失函数为 L s p e a k e r 和 L r e c o n s t r L_{speaker}和L_{reconstr} Lspeaker和Lreconstr的加权和, 利用Adam对模型进行优化训练。
3.5 Data augmentation with dynamic mixing
采用类似论文【63,64】中的数据增强方法对训练集进行增强,在生成训练集时,采用随机窗口对训练集数据进行采样,并通过随机增益对不同的采样进行求和的方法获得新的训练集样本。
[63] S. Uhlich et al., “Improving music source separation based on deep neural networks through data augmentation and network blending,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2017, pp. 261–265.
[64] A. Défossez, N. Usunier, L. Bottou, and F. Bach, “Demucs: Deep extractor for music sources with extra unlabeled data remixed,” 2019, arXiv:1909.01174.
4. Experiments & Results
本文大多数实验都是根据论文【10】中介绍的LDC WSJ-0数据集构建的说话人分离数据集。采样率8kHz,包含2个或者3个说话人。

此外,我们依据WHAM!和WHAMR!分别构建带噪环境数据集和带噪以及混响环境数据集。本文还在不同的损失函数,不同的网络架构下进行了实验,分析了对整体性能有较大负面影响的小部分序列。本文还在最近发布的LibriMix数据集上进行了实验,采样率与之前相同。
本文的评价指标为SDR 和 SI-SDR。
4.1 Hyperparameter Selection
两个子网络的特征维度均为512,扩张卷积的内核大小为3,步长为1,所有层都保留了输入信号的时间分辨率,并且在输出端不需要进行上采样。膨胀系数随着网络深度进行改变,speaker子网络网络深度为14层,因此膨胀系数从 2 0 到 2 13 2^0到2^{13} 20到213。separation子网络深度为40层,膨胀系数为 δ l = 2 l m o d 10 \delta_l=2^{l mod 10} δl=2lmod10。
训练过程中,学习率为1e-3,speaker 损失权重为2。对于正则化,距离正则化权重为0.3,高斯噪声的标准差为0.2,speaker dropout rate为0.4,speaker mixup rate为0.5。负SDR损失中的 τ \tau τ对于纯净语音设置为30,带噪数据设置为27。对于 L s p e a k e r L_{speaker} Lspeaker,选用全局分类器效果最好。
4.2 Clean setting


对于WSJ0-2mix,表3分析了误差分布情况
4.3 Noisy and Reverberated settings

4.4 Large scale experiments on Librimix
4.6 消融实验

基准模型:无动态混合数据增强,使用全局分类器损失(公式4)