Vision Transformer 论文 + 详解( ViT )
论文名叫《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》一张图片等价于 16x16 的单词,顾名思义,ViT就是把图片分割成 16x16 的patch,然后将这些 patch 看作 transformer 的输入。下面就一起来学习一下论文吧。
论文地址:https://arxiv.org/pdf/2010.11929.pdf
pytorch源码:rwightman写的,被官方收录
tf源码:https://github.com/google-research/vision_transformer
目录
Abstract
1 Introduction
2 Related Work
3 Method
3.1 VISION T RANSFORMER (V I T)
Embedding 层
Transformer Encoder
MLP Head
3.2 F INE - TUNING AND H IGHER R ESOLUTION
4 Experiments
5 Conclusion
Abstract
其实摘要就说了一件事,在视觉领域,我们就利用 transformer 取得的效果比你 CNN 要好。
虽然 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯变换器可以在图像分类任务上表现得非常好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,与最先进的卷积神经网络相比,Vision Transformer (ViT) 取得了出色的结果,同时需要更少的计算资源来训练。
⚠️注意:当你看到论文里说IN是中小型数据集的时候就注意了,对Google那帮人来说是,咱们就不要主观代入了,另外这里更少的训练资源是指2500天TPUv3的训练。
1 Introduction
引言主要有这几个点:
- Transformer 已经在 NLP 领域取得大规模的应用,具有很好的计算效率和可扩展性,并且随着模型增大,性能没有饱和(这也就是为什么想把 transformer 引入到视觉领域的一个原因)
- 作者尽可能不对 transformer 进行修改,这样才可以证明不是因为引入对视觉友好的一些方法,而是 transformer 本身就可以胜任视觉任务并取得很好的结果。
- 在中小型数据集上训练确实不如 ResNet 等网络效果更好,因为传统的 CNN 有两个先验知识(归纳偏执):translation equivariance 无论先做卷积还是先做平移,效果是一样的;locality 指的是图片相邻像素具有一定关系。如果放在更大的数据集里面进行训练,那就不需要这些归纳偏执了。所以在更大规模的数据集上进行训练,取得的效果比 CNN 的要好。
基于自注意力的架构,尤其是 Transformers ,已成为自然语言处理 (NLP) 的首选模型。主要的方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调。由于 Transformers 的计算效率和可扩展性,训练具有超过 100B 参数的前所未有的模型成为可能。随着模型和数据集的增长,仍然没有饱和性能的迹象。
然而,在计算机视觉中,卷积架构仍然占主导地位。受 NLP 成功的启发,很多工作尝试将类似 CNN 的架构与自注意相结合,其中一些完全取代了卷积。有些模型虽然在理论上是有效的,但由于使用了专门的注意力模式,尚未在现代硬件加速器上有效地扩展。因此,在大规模图像识别中,经典的 ResNet架构仍然是最先进的。
受 NLP 中 Transformer 可扩展性的启发,我们尝试将标准 Transformer 直接应用于图像,尽可能少地进行修改。为此,我们将图像拆分为块,并提供这些块的线性嵌入序列作为 Transformer 的输入。图像块的处理方式与 NLP 应用程序中的标记(单词)相同。我们以监督方式训练模型进行图像分。
当在没有强正则化的 ImageNet 等中型数据集上进行训练时,这些模型产生的准确度比同等大小的 ResNet 低几个百分点。这种看似令人沮丧的结果可能是意料之中的:Transformers 缺乏 CNN 固有的一些归纳偏差,例如 translation equivariance 平移等效性和 locality 局部性,因此在对数据量不足进行训练时不能很好地泛化。
但是,如果模型在更大的数据集(14M-300M 图像)上训练,情况就会发生变化。我们发现大规模训练胜过归纳偏差。我们的 Vision Transformer (ViT) 在足够的规模进行预训练并转移到具有较少数据点的任务时获得了出色的结果。当在 ImageNet-21k 数据集或 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近或超过了最先进的水平。特别是,最好的模型在 ImageNet 上达到 88.55%,在 ImageNet-ReaL 上达到 90.72%,在 CIFAR-100 上达到 94.55%,在 19 个任务的 VTAB 上达到 77.63%。
2 Related Work
如果直接把一张图片拉成一个向量,那么对于 rransformer 来说,序列长度太长,计算复杂度过高。所以 Cordonnier 等人的模型。,它从输入图像中提取大小为 2 × 2 的 patch。这里其实已经使用的是 transformer 了,但是奈何Google 更有钱啊,直接弄个 16 x 16 的patch,可以处理224的图像了,并且在大型数据集上取得非常好的效果。
Transformer 由 Vaswani 等人提出,用于机器翻译,并已成为许多 NLP 任务中最先进的方法。基于大型 Transformer 的模型通常在大型语料库上进行预训练,然后针对手头的任务进行微调:BERT 使用去噪自监督预训练任务,而 GPT 工作线使用语言建模作为其预训练任务。
将自注意力简单地应用于图像需要每个像素都关注其他每个像素。由于像素数量的二次成本,这不能扩展到实际的输入大小。因此,为了在图像处理的上下文中应用 Transformer,过去曾尝试过几种近似方法。Parmar 等人仅在每个查询像素的局部邻域中应用自注意,而不是全局。这种局部多头点积自注意力块可以完全替代卷积。在另一项工作中,Sparse Transformers (Child et al., 2019) 对全局自注意力采用可扩展的近似值,以便适用于图像。扩展注意力的另一种方法是将其应用于不同大小的块,在极端情况下仅沿单个轴。许多这些专门的注意力架构在计算机视觉任务上展示了有希望的结果,但需要在硬件加速器上并且十分复杂。
与我们最相关的是 Cordonnier 等人的模型。,它从输入图像中提取大小为 2 × 2 的 patch ,并在顶部应用完全自注意力。该模型与 ViT 非常相似,但我们的工作进一步证明了大规模的预训练使 vanilla Transformer 可以与(甚至优于)最先进的 CNN 竞争。此外,Cordonnier 等人使用 2 × 2 像素的小块大小,这使得该模型仅适用于小分辨率图像,而我们也处理中等分辨率图像。
将卷积神经网络 (CNN) 与自注意形式相结合也引起了很多兴趣,例如通过为图像分类增加特征图或通过使用自注意进一步处理 CNN 的输出,例如用于对象检测(Hu et al., 2018; Carion et al., 2020)、视频处理(Wang et al., 2018; Sun et al., 2019)、图像分类(Wu et al., 2020)、无监督对象发现(Locatello 等人,2020)或统一的文本视觉任务(Chen 等人,2020c;Lu 等人,2019;Li 等人,2019)。
另一个最近的相关模型是图像 GPT (iGPT) (Chen et al., 2020a),它在降低图像分辨率和色彩空间后将 Transformers 应用于图像像素。该模型作为生成模型以无监督方式进行训练,然后可以对生成的表示进行微调或线性探测以提高分类性能,在 ImageNet 上达到 72% 的最大准确度。
我们的工作增加了越来越多的论文,这些论文探索了比标准 ImageNet 数据集更大规模的图像识别。使用额外的数据源可以在标准基准上实现最先进的结果(Mahajan 等人,2018;Touvron 等人,2019;Xie 等人,2020)。此外,Sun 等人。 (2017) 研究 CNN 性能如何随数据集大小扩展,以及 Kolesnikov 等人。 (2020); Djolonga 等人。 (2020) 对 ImageNet-21k 和 JFT-300M 等大规模数据集的 CNN 迁移学习进行了实证探索。我们也关注后两个数据集,但训练 Transformer 而不是之前工作中使用的基于 ResNet 的模型。

3 Method
在模型设计中,我们尽可能地遵循原始的 Transformer (Vaswani et al., 2017)。这种有意的简单设置的优点是可扩展的 NLP Transformer 架构及其高效的实现几乎可以开箱即用。
3.1 VISION T RANSFORMER (V I T)
该模型的概述如图 1 所示。标准 Transformer 接收一维 token 嵌入序列作为输入。为了处理 2D 图像,我们将图像
重塑为一系列扁平化的 2D 块
,其中 (H, W) 是原始图像的分辨率,C 是通道数,(P, P) 是每个图像块的分辨率,
是生成的块数,它也作为 Transformer 的有效输入序列长度。 Transformer 在其所有层中使用恒定的潜在向量大小 D,因此我们将补丁展平并使用可训练的线性投影映射到 D 维(等式 1)。我们将此投影的输出称为patch embeddings。
与 BERT 的 [class] 标记类似,我们在嵌入补丁序列 (
) 中添加可学习的嵌入,其在 Transformer 编码器 (
) 输出处的状态用作图像表示
(Eq 4).在预训练和微调期间,分类头都附加到
Position embedding 被添加到 patch embedding 中以保留位置信息。我们使用标准的可学习 1D 位置嵌入,因为我们没有观察到使用更高级的 2D 感知位置嵌入(附录 D.4)可以显着提高性能。生成的嵌入向量序列用作编码器的输入。
Transformer 编码器由多头自注意力和 MLP 块的交替层组成。在每个块之前应用
Layernorm (LN),在每个块之后应用残差连接 。
Inductive bias. 我们注意到,与 CNN 相比,Vision Transformer 的图像特定归纳偏差要小得多。在 CNN 中,局部性、二维邻域结构和平移等效性被整个模型的每一层中都存在。在 ViT 中,只有 MLP 层存在局部性的和平移等变性的,而自注意力层是全局的。二维邻域结构的使用非常谨慎:在模型开始时,通过将图像切割成块,并在微调时调整不同分辨率图像的位置嵌入(如下所述)。除此之外,初始化时的位置嵌入不携带有关补丁的 2D 位置的信息,并且必须从头开始学习补丁之间的所有空间关系。
Hybrid Architecture. 作为原始图像块的替代方案,输入序列可以由 CNN 的特征图形成(LeCun 等人,1989)。在这个混合模型中,patch 嵌入投影 E(等式 1)应用于从 CNN 特征图中提取的 patch。作为一种特殊情况,patch 可以具有 1x1 的空间大小,这意味着输入序列是通过简单地将特征图的空间维度展平并投影到 Transformer 维度来获得的。如上所述添加分类输入嵌入和位置嵌入。

这一部分就一下把 ViT 说的很明白了,它的结构就是新的 Embedding 层 + transformer 中的 Encoder 层 + MLP 层,是不是很简单!
Embedding 层
原文把 embedding 层的过程讲的很清楚了,这里,我用 ViT-B/16 (ViT_base_patch16)举例说明。首先以 224 x 224 输入,把图像分割成 16 x 16 的 patch ,那么就存在 ![]() 个 patch。然后讲这 196 个patch 映射到
个 patch。然后讲这 196 个patch 映射到 ![]() 的向量里。每个 patch 的 shape 是 [16, 16, 3](长和宽为 16 ,通道数为 3)。代码中这一步实现是通过一个卷积实现的
的向量里。每个 patch 的 shape 是 [16, 16, 3](长和宽为 16 ,通道数为 3)。代码中这一步实现是通过一个卷积实现的
Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)卷积核大小为 16 ,步长为16,输入维度是 3,输出维度是 768 。妙啊!!
这样图片就由原来的 [224, 224, 3] 变成了 [14, 14, 768] ,经过 Flatten 就得到 [196, 768]。
添加一个专门用于分类的 token 。文中提到这里添加方式与 BERT 类似,添加一个可以通过学习得到的 [class] token,为了保持维度一致,[class] token的维度为 [1, 768] 。通过Concat操作,[196, 768] 与 [1, 768] 拼接得到 [197, 768] 。
随后就是对于这些 token 添加位置信息,也就是 position embedding。这里和 transformer 一致,都是可训练的参数,因为要加到所有 token 上,所以维度也是 [197, 768] 。
Transformer Encoder
这一部分就和 transformer 中的 encoder 一摸一样了,可以看之前写的详解transformer详解
简单来说就是 N x Blocks(Multi-Head Attention + MLP)
在 ViT-B/16 中,输入是 [197, 768] 输出也是 [197, 768] 。
然后就是接一个 MLP Head 进行最后的分类结果的输出。
MLP Head
其实这里更简单了,和 transformer 唯一不同的是,transformer 利用了所有的输出 token ,但是 ViT 只是进行分类,在这里只需要 [class] token 对应位置进行输出就可以。
输出方法也很简单就是一个全联接神经网络!就是这么简单!
3.2 F INE - TUNING AND H IGHER R ESOLUTION
通常,我们在大型数据集上预训练 ViT,并对(较小的)下游任务进行微调。为此,我们移除预训练的预测头并附加一个零初始化的 D × K 前馈层,其中 K 是下游类的数量。与预训练相比,以更高的分辨率进行微调通常是有益的(Touvron 等人,2019;Kolesnikov 等人,2020)。当提供更高分辨率的图像时,我们保持补丁大小相同,从而产生更大的有效序列长度。 Vision Transformer 可以处理任意序列长度(直至内存限制),但会导致预训练的位置信息不再有意义。因此,我们根据它们在原始图像中的位置对预训练的位置嵌入进行 2D 插值。请注意,这种分辨率调整和补丁提取是将有关图像 2D 结构的归纳偏差手动注入视觉转换器的唯一点。
4 Experiments
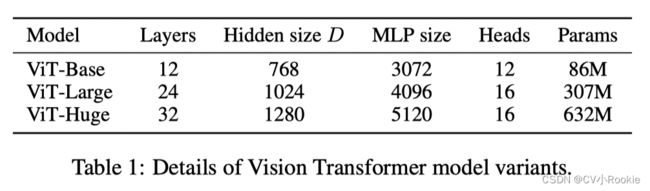
可以看到这个参数量对我们而言还是非常夸张的,所以在训练自己的 transformer 时,还是要使用他们的预训练好的权重文件。
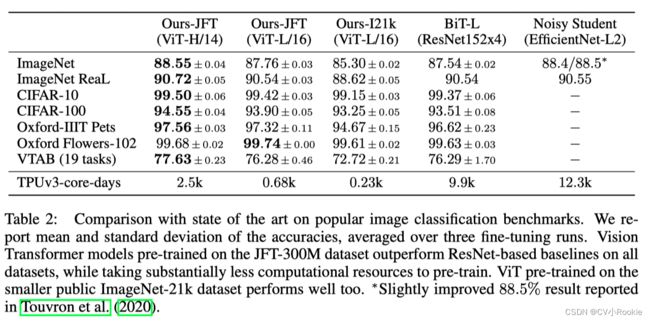
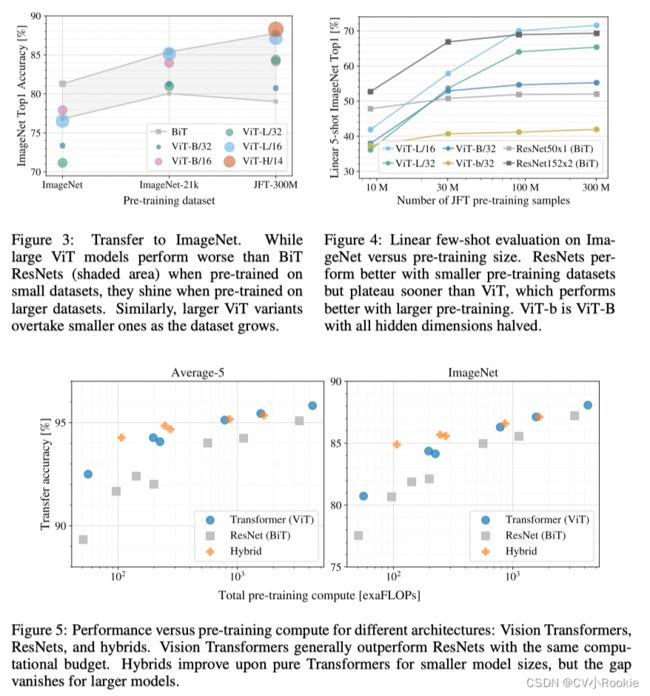
5 Conclusion
我们已经探索了 transformer 在图像识别中的直接应用。与在计算机视觉中使用自注意力的先前工作不同,除了初始 patch 提取步骤之外,我们不会将特定于图像的归纳偏差引入架构中。相反,我们将图像解释为一系列 patch,并通过使用 NLP 中的标准 Transformer 编码器对其进行处理。这种简单但可扩展的策略在与大型数据集的预训练相结合时效果出奇地好。因此,Vision Transformer 在许多图像分类数据集上匹配或超过了最先进的技术,同时预训练成本相对较低。
虽然这些初步结果令人鼓舞,但仍然存在许多挑战。一种是将 ViT 应用于其他计算机视觉任务,例如检测和分割。我们的结果,再加上 Carion 等人的结果,表明这种方法的承诺。另一个挑战是继续探索自我监督的预训练方法。我们最初的实验表明 自监督预训练的改进,但自监督和大规模监督预训练之间仍有很大差距。最后,进一步扩展 ViT 可能会提高性能。