论文笔记之Self-Attention Graph Pooling
论文笔记之Self-Attention Graph Pooling
文章目录
- 论文笔记之Self-Attention Graph Pooling
- 一、论文贡献
- 二、创新点
-
- 三、背景知识
- 四、SAGPool层
-
- 1. SAGPool机理
- 五、模型架构
- 六、 实验结果分析
- 七、未来研究
一、论文贡献
本文提出了一种基于self-attention的图池化方法SAGPool。使用图形卷积能够使池化方法同时考虑节点特征和图形拓扑。
二、创新点
-
该方法可以使用相对较少的参数以端到端方式学习层次表示。 -
利用self-attention机制来区分应该删除的节点和应该保留的节点。 -
基于图形卷积来计算注意分数的self-attention机制,考虑了节点特征和图形拓扑。
三、背景知识
池化层使CNN模型通过缩小表示的大小来减少参数的数量,从而避免过拟合。为了推广卷积神经网络,图神经网络的池化方法是必要的。图池化方法可以分为以下三类:基于拓扑的、全局的和分层池化。
-
基于拓扑池的早期工作使用图粗化算法,而不是神经网络。光谱聚类算法利用特征分解得到粗化图。然而,由于特征分解的时间复杂度,需要进行替代。
-
全局池化与前面的方法不同,全局池化方法考虑图形特征。全局池化方法使用总和法或神经网络法来池化每一层节点的所有表示。具有不同结构的图可以被处理,因为全局池化方法收集了所有的表示。SortPool根据图的结构特征对节点的嵌入进行排序,并将排序后的嵌入传递给下一层。
-
分层池化方法的主要动机是建立一个可以学习到每一层基于特征或拓扑的节点分配方式的模型。Ying等人提出了DiffPool,这是一种可微分的图池方法,可以以端到端方式学习分配矩阵。节点分配公式如下:

Cangea等人利用gPool取得了与DiffPool相当的性能。gPool使用一个可学习向量p来计算投影分数,然后使用这些分数来选择排名最高的节点。投影得分由p与所有节点的特征点积得到。分数表示可以保留的节点的信息量。下面的方程式和图示大致描述了gPool中的池化过程。


由于投影分数的计算没有考虑图的拓扑结构,为了进一步改进图池,我们提出SAGPool,它可以使用特征和拓扑产生具有合理的时间和空间复杂度的层次表示。
四、SAGPool层
SAGPool的关键在于它使用GNN来提供self-attention分数。Self-attention机制能够更多地关注更重要的特性。
SAGPool层结构如下图所示。
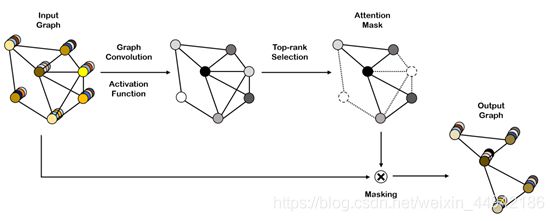
1. SAGPool机理
- Self-attention mask
我们利用图卷积得到自我注意分数。计算自我注意分数Z∈RN×1如下。
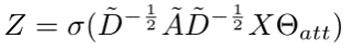
Θatt代表输入特征空间的卷积权重。
Θatt是SAGPool层唯一的参数。本文使用gPool中的节点保留方法保留了输入图的一部分节点。池化比率k∈(0,1)是一个超参数,它决定要保留的节点数。根据Z的值选择前kN个节点。Top-rank 函数返回的是排序后的前kN个值的索引。
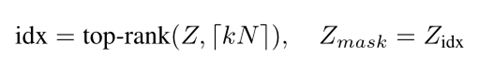
![]()
X[idx,:]是索引按行排列的特征矩阵 (每一行代表一个节点的特征向量),A[idx,idx]是行和列向索引邻接矩阵。Xout和Aout分别是新的特征矩阵和相应的邻接矩阵。
- 注意力分数的计算
AGPool中使用图卷积的主要原因是为了反映拓扑结构和节点特征。如果GNN以节点特征和邻接矩阵为输入,则可以将之前计算自我注意分数的公式代入GNN的各种公式。注意力分数Z∈RN×1的广义计算公式如下:

计算注意力分数的方法:
(a)不仅使用邻近节点,也使用多跳连接节点,添加两跳邻居的平方。相应的计算公式如下:SAGPoolaug

(b)使用两个GNN层的堆叠,允许两跳节点的间接聚合。在这种情况下,SAGPool的非线性和参数个数都相应增加。相应的计算如下:SAGPoolserial
![]()
(c)使用多重注意力分数的平均值。通过M个GNNs得到平均注意分数如下: SAGPoolparall

五、模型架构
将图卷积应用于所有的模型。该方程和计算注意分数的方程是一样的,除了Θ的维度。

Θ:代表F*F’维度特征空间的卷积权重。

左图为全局池架构,右图为分层池架构
readout读出层,该层聚合节点特征以生成固定大小的表示。
该层的最终输出特征形式:

全局池架构:
全局池架构由三个图形卷积层组成,每一层的输出都是连接的。节点特性聚集在读出层中,读出层在池化层之后。然后将图特征表示传递到线性层进行分类。
分层池架构:
该体系结构由三个块组成,每个块由一个图形卷积层和一个图形池层组成。每个块的输出汇总在读出层中。每个读出层输出的总和被输入到线性层进行分类。
六、 实验结果分析
全局池化在节点较少的数据集上的性能优于分层池化。(因为全局池化结构使得信息损失最小)
分层池化在节点数量比较多的数据集上性能比较好。(因为分层池化可以有效地从大型图中提取到有用的信息)。
因此,选用最适合给定数据集的池架构非常重要,本文所提出的SAGPool方法在每种架构中都表现得很好,所以更方便地应用在不同架构。
影响SAGPool性能的因素:
-
数据集和GNN类型 -
两跳邻域节点的信息
SAGPool方法的优势:分层池化、兼顾节点特征和图拓扑、合理的复杂度、端到端表示学习。SAGPool使用一致数量的参数,而与输入图的大小无关。
SAGPool方法的局限:我们保留一定百分比(池化率k)的节点来处理不同大小的输入图,在SAGPool中,我们不能参数化池化比率来找到每个图的最优值。为了解决这个限制,我们使用二分类来决定保留哪些节点,但这并没有完全解决这个问题。
七、未来研究
使用可学习的池化比率来获得每个图的最优簇大小。
研究每个池化层中多个attention mask的影响,在每个池化层中,最终的表示可以通过聚合不同的层次表示来得到。