论文笔记21:Deep spatio-spectral Bayesian posterior for hyperspectral image non-i.i.d. noise removal
Deep spatio-spectral Bayesian posterior for hyperspectral image non-i.i.d. noise removal-公式看不懂
- 引言
- 问题表述
- 方法
-
- Spatio-spectral Bayesian posterior network
- Network structure and learning
- 实验
- 代码
引言
作者主页:https://qzhang95.github.io/
GeoScience Café:旧瓶装新酒 科研idea进阶之路
参考:Denoising Hyperspectral Image With Non-i.i.d. Noise Structure
模型驱动:这类方法通常依赖于HSI的典型先验,然后设计优化模型来生成去噪结果。如空间-光谱全变分,空间-光谱非局部均值,空谱稀疏表示,低秩先验,张量分解等已经开发用于HSI去噪。
数据驱动:这类方法依赖于大量的样本数据(干净的标签数据和相应的噪声数据),通过端到端的深度学习框架来获得合适的去噪器。针对自然图像去噪,已经开展了DnCNN、FFDNet、CBDNet等多项工作。
在基于深度学习的HSI去噪任务中,谢和李提出了一种集成(integrating)变化的(mutative)非线性函数的级联(cascaded)神经网络来降低HSI中的噪声(HDnTD)。袁等开发了一种用于HSI去噪的多尺度多层次空间光谱卷积神经网络(HSID-CNN)。Chang等人采用多通道卷积滤波器接收混合噪声进行模型训练(HSI-DeNet)。通过将三维卷积分解为二维卷积和光谱向量,董等人提出了一种改进的HSI去噪3D U-net(DSSRL)。此外,为了更好地去除HSIs中的混合噪声,张等进一步将空间光谱梯度信息(SSGN)引入到深度CNN。此外,刘和李(3DADCNN)利用3D扩张卷积神经网络进行HSI去噪,从空间和光谱前景(prospects)中提取深层特征。
基于数据驱动的HSI去噪方法通过端到端的学习框架更快更方便,而不需要在基于模型驱动的方法中仔细调整超参数和复杂的优化。相反,基于模型驱动的HSI去噪方法可以更好地符合HSI的优势先验,如低秩特性,而不需要在基于数据驱动的方法中建立大的训练HSI样本。
非i.i.d.噪声建模和去除过程都是用深度空间-光谱学习模型来执行的。此外,考虑到HSI中稀疏噪声的空间方向性和光谱非均匀性(heterogeneity),利用各向异性全变分项对稀疏噪声尤其是条带噪声进行建模。
该方法可以在贝叶斯变分框架下,同时估计出HSI中各波段的非i.i.d.噪声和稀疏分布噪声的分布,并去除噪声。为了同时利用光谱相关性和考虑空间差异,提出了3D和2D卷积神经网络去噪模型。值得注意的是,包括稀疏噪声估计和去除操作的非i.i.d.噪声被协同地(collaboratively)参数化到端到端数据驱动框架中。通过融合贝叶斯变分后验和深度神经网络,该方法继承了传统模型驱动和数据驱动方法的优势。
问题表述
Y = X + N + S Y=X+N+S Y=X+N+S, Y ∈ R w × h × b Y\in\mathbb{R}^{w\times h\times b} Y∈Rw×h×b, N N N代表非i.i.d噪声,我们构建噪声模型来描述 Y Y Y的退化过程: Y i ∼ N ( Y i ∣ Z i , σ i 2 ) , i = 1 , 2 , ⋯ b ( 2 ) \mathbf{Y}_{i}\sim\mathcal{N}\left(\mathbf{Y}_{i} \mid Z_{i}, \sigma_{i}^{2}\right), i=1,2, \cdots b\quad(2) Yi∼N(Yi∣Zi,σi2),i=1,2,⋯b(2)
其中 N ( ⋅ ∣ μ , σ 2 ) \mathcal{N}(\cdot|\mu,\sigma^2) N(⋅∣μ,σ2)表示均值为 μ \mu μ,方差为 σ 2 \sigma^2 σ2的高斯分布, Z Z Z为邻近的干净HSI(the latent clean HSI underlying Y)。我们考虑非独立同分布噪声,噪声方差 σ 2 = { σ 1 2 , σ 2 2 , ⋯ , σ b 2 } \sigma^2=\{\sigma_1^2,\sigma_2^2,\cdots,\sigma_b^2\} σ2={σ12,σ22,⋯,σb2}是空间维上的灵活嵌入,并且引入了有理共轭先验如下: σ i 2 ∼ I G ( σ i 2 ∣ r 2 2 − 1 , r 2 ξ i 2 ) , i = 1 , 2 , ⋯ b ( 3 ) \sigma_{i}^{2}\sim \mathcal{IG}\left(\sigma_{i}^{2} \mid \frac{r^{2}}{2}-1, \frac{r^{2} \xi_{i}}{2}\right), i=1,2, \cdots b\quad(3) σi2∼IG(σi2∣2r2−1,2r2ξi),i=1,2,⋯b(3)
(注:PPT里(3)式 r r r为 p p p)其中 I G ( ⋅ ∣ α , β ) IG(\cdot|\alpha,\beta) IG(⋅∣α,β)表示关于参数 α , β \alpha,\beta α,β的逆Gamma分布, ξ \xi ξ代表残差映射在 r × r r\times r r×r窗口内通过高斯滤波器的滤波结果,噪声方差 σ 2 \sigma^2 σ2是HSI中每个波段的pixel-wise高斯分布(似乎有问题)。
原始干净的HSI X X X显然与邻近的干净的HSI Z Z Z存在一个主导先验。从这个角度来看, Z Z Z的共轭高斯先验被施加如下 Z i ∼ N ( Z i ∣ X i , ε 0 2 ) , i = 1 , 2 , ⋯ b ( 4 ) \mathbf{Z}_{i} \sim\mathcal{N}\left(\mathbf{Z}_{i} \mid \mathbf{X}_{i}, \varepsilon_{0}^{2}\right), i=1,2, \cdots b\quad(4) Zi∼N(Zi∣Xi,ε02),i=1,2,⋯b(4)
其中 ε 0 \varepsilon_{0} ε0代表具有小值的预定参数。HSI中的条纹噪声同时呈现空间水平或垂直分布。稀疏噪声的密度在光谱维度上也不同。自然地, S S S的共轭稀疏先验 K K K被约束如下 S i ∼ K ( S i ∣ Y i , Y ) , i = 1 , 2 , ⋯ b ( 5 ) \mathbf{S}_{i} \sim\mathcal{K}\left(\mathbf{S}_{i} \mid Y_{i}, \mathbf{Y}\right), i=1,2, \cdots b\quad(5) Si∼K(Si∣Yi,Y),i=1,2,⋯b(5)
联合(2)~(5),我们可以获得一个完整的贝叶斯推理框架,用于HSI非i.i.d噪声建模问题。然后我们的目标集中在通过 Y Y Y估计邻近的干净的HSI Z Z Z,噪声方差 σ 2 \sigma^2 σ2和稀疏分布的噪声 S S S的后验,用 p ( Z , σ 2 , S ∣ Y ) p\left(\mathbf{Z}, \sigma^{2}, \mathbf{S} \mid \mathbf{Y}\right) p(Z,σ2,S∣Y)表示。
方法
Spatio-spectral Bayesian posterior network
考虑到邻近的干净的HSI Z Z Z,噪声方差 σ 2 \sigma^2 σ2和稀疏分布的噪声 S S S之间的条件独立性,建立了HSI中每个光谱的概率分布:
q ( Z i , σ i 2 , S i ∣ Y ) = q ( Z i ∣ Y ) q ( σ i 2 ∣ Y ) q ( S i ∣ Y ) ( 6 ) q\left(\mathbf{Z}_{i}, \sigma_{i}^{2}, \mathbf{S}_{i} \mid \mathbf{Y}\right)=q\left(\mathbf{Z}_{i} \mid \mathbf{Y}\right) q\left(\sigma_{i}^{2} \mid \mathbf{Y}\right) q\left(\mathbf{S}_{i} \mid \mathbf{Y}\right)\quad(6) q(Zi,σi2,Si∣Y)=q(Zi∣Y)q(σi2∣Y)q(Si∣Y)(6)
根据(3)–(5)中的共轭先验,我们可以逻辑地推测3个估计后验概率如下:
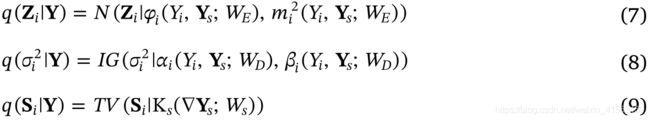
其中 φ i \varphi_i φi和 m i 2 m_i^2 mi2表示从 Y Y Y中计算后验Z的中间结果。 α i \alpha_i αi和 β i \beta_i βi表示从有 Y Y Y中计算后验 σ 2 \sigma^2 σ2中间结果。 K s \mathbf{K}_s Ks表示空间-光谱梯度,通过全变分(TV)优先约束稀疏分布的噪声 S S S。 Y i Y_i Yi和 Y s Y_s Ys分别表示 Y Y Y中的第 i i i波段及其相邻光谱立方体。 W E W_E WE、 W D W_D WD和 W S W_S WS分别表示非i.i.d噪声估计网络、非i.i.d.噪声分布网络和稀疏噪声空间光谱梯度网络中的可训练参数。“s”代表卷积运算中的步长,“c”代表特征映射的通道数。“3×3×3×32”表示具有32个通道的3×3×3的3D滤波器。“3×3×64”表示具有64个通道的3×3的2D滤波器。
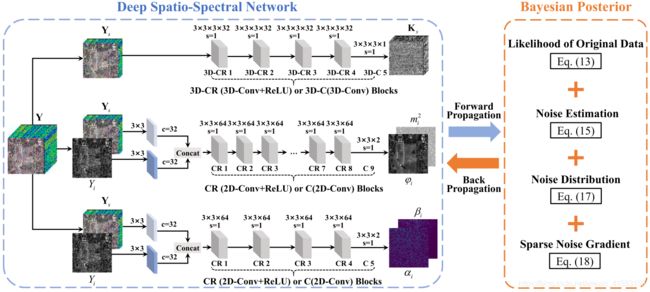

(两个图是一样的)通过上述训练样本的后验,对 W E W_E WE、 W D W_D WD和 W S W_S WS的网络参数进行整合。换句话说,非i.i.d.噪声和稀疏噪声估计和去除操作被协同地参数化到端到端数据驱动学习框架中。
Network structure and learning
公式推导参考:Yue et al., Variational Denoising Network: Toward Blind Noise Modeling and Removal. NeurIPS, 2019.
(上图中间)对于包含参数 W E W_E WE的非i.i.d.噪声估计网络,层深度被设置为9个2D卷积和激活层。(上图下方)对于包含参数 W D W_D WD的非i.i.d.噪声分布网络,层深度设置为5个2D卷积和激活层。(上图上方)稀疏噪声网络的层深度被设置为5个3D卷积和激活层。
构造了整个贝叶斯变分框架之后,可以导出HSI中的非i.i.d.噪声的最下界(low bound): L ( Z , σ 2 ; Y ) = E q ( Z , σ 2 ∣ Y ) − D K L ( q ( Z ∣ Y ) ∥ p ( Z ) ) − D K L ( q ( σ 2 ∣ Y ) ∥ p ( σ 2 ) ) ( 10 ) L\left(\mathbf{Z}, \sigma^{2} ; \mathbf{Y}\right)=E_{q\left(\mathbf{Z}, \sigma^{2} \mid \mathbf{Y}\right)}-D_{K L}(q(\mathbf{Z} \mid \mathbf{Y}) \| p(\mathbf{Z}))-D_{K L}\left(q\left(\sigma^{2} \mid \mathbf{Y}\right) \| p\left(\sigma^{2}\right)\right)\quad(10) L(Z,σ2;Y)=Eq(Z,σ2∣Y)−DKL(q(Z∣Y)∥p(Z))−DKL(q(σ2∣Y)∥p(σ2))(10)
上式中3个子项如下:
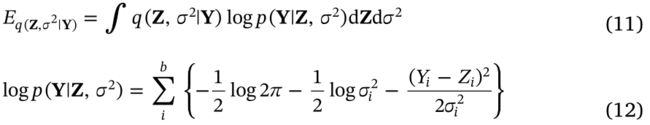
结合公式(6)(11)(12),原始干净数据的相似性(likelihood) E q ( Z , σ 2 ∣ Y ) E_{q\left(\mathbf{Z}, \sigma^{2} \mid \mathbf{Y}\right)} Eq(Z,σ2∣Y)(能量式)计算如下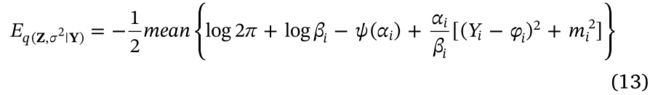
等式(10)中高斯分布的KL散度 D K L ( q ( Z ∣ Y ) ∥ p ( Z ) ) D_{K L}(q(\mathbf{Z} \mid \mathbf{Y}) \| p(\mathbf{Z})) DKL(q(Z∣Y)∥p(Z))如下: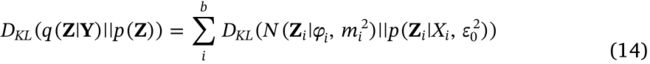
结合式子(2)(4)(7)(14),相似性(likelihood) D K L ( q ( Z ∣ Y ) ∥ p ( Z ) ) D_{K L}(q(\mathbf{Z} \mid \mathbf{Y}) \| p(\mathbf{Z})) DKL(q(Z∣Y)∥p(Z))计算如下:
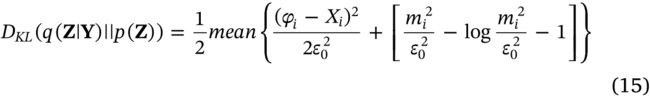
在等式(10)中,对于逆Gamma分布的KL散度 D K L ( q ( σ 2 ∣ Y ) ∥ p ( σ 2 ) ) D_{K L}\left(q\left(\sigma^{2} \mid \mathbf{Y}\right) \| p\left(\sigma^{2}\right)\right) DKL(q(σ2∣Y)∥p(σ2)),描述如下
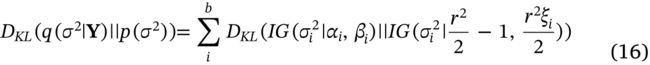
结合式子(3)(8)(16), D K L ( q ( σ 2 ∣ Y ) ∥ p ( σ 2 ) ) D_{K L}\left(q\left(\sigma^{2} \mid \mathbf{Y}\right) \| p\left(\sigma^{2}\right)\right) DKL(q(σ2∣Y)∥p(σ2))的最终形式可以推导为: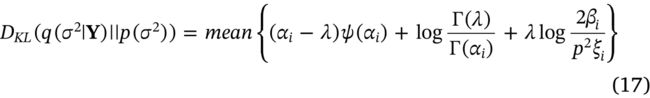
PPT里面(17)式为:
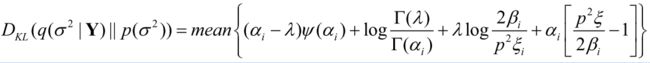
其中 λ = ( r 2 2 − 1 ) \lambda=(\frac{r^2}{2}-1) λ=(2r2−1), ψ ( ⋅ ) \psi(\cdot) ψ(⋅)为digamma函数, ψ ( x ) = Γ ′ ( x ) Γ ( x ) \psi(x)=\frac{\Gamma'(x)}{\Gamma(x)} ψ(x)=Γ(x)Γ′(x).
此外,在式子(9)中考虑了HSI中稀疏噪声的空间方向性和光谱非均匀性,利用各向异性TV项对稀疏噪声尤其是条纹噪声进行建模:
![]()
其中光谱差分的垂直(v)和水平(h)梯度由稀疏噪声网络中的L1范数施加。
就整体网络优化而言,等式(10)中非i.i.d.噪声的最下界和等式(18)中的稀疏噪声TV项混合到综合损失函数中:
![]()
其中 η \eta η为稀疏噪声TV项的惩罚参数。所提出的框架符合反向传播(BP)梯度下降算法来优化三个网络参数 W E W_E WE、 W D W_D WD和 W S W_S WS.
实验
待补充
代码
https://github.com/qzhang95/DSSBP
暂未公布