Keras教学(11):使用Keras搭建yolo1目标检测网络
【写在前面】:大家好,我是【猪葛】
一个很看好AI前景的算法工程师
在接下来的系列博客里面我会持续更新Keras的教学内容(文末有大纲)
内容主要分为两部分
第一部分是Keras的基础知识
第二部分是使用Keras搭建FasterCNN、YOLO目标检测神经网络
代码复用性高
如果你也感兴趣,欢迎关注我的动态一起学习
学习建议:
有些内容一开始学起来有点蒙,对照着“学习目标”去学习即可
一步一个脚印,走到山顶再往下看一切风景就全明了了
本篇博客学习目标:1、理解yolo1目标检测的实现方式;2、学会搭建yolo1神经网络
文章目录
- 一、yolo1简介
-
- 1-1、yolo1概述
- 1-2、yolo1主要特点
- 1-3、yolo1的核心思想
- 1-4、yolo1的实现方法
- 二、yolo1的网络结构
-
- 2-1、网络结构分析
- 2-2、网络结构搭建
一、yolo1简介
1-1、yolo1概述
这是继RCNN,fast-RCNN 和 faster-RCNN之后,Ross Girshick大神挂名的又一大作。它解决了目标检测的数度问题,当然啦,从2020年的时间节点出发你会发现对于目标检测问题还有很好的神经网络和办法,但是它们的很多核心思想都是延续yolo1的,所以我们理解好yolo1的实现过程、理解好yolo1的网络结构、yolo1的损失函数显得尤为重要。下面也会主要从这三方面入手来手撕yolo1。使用tensorflow2.0来编写yolo1,给观众老爷们来场不一样的视觉感受。yolo损失函数我会放在第二篇文章里面讲,因为它真的太重要了。
1-2、yolo1主要特点
优点:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
缺点:
- 小物体检测性不好。YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类
- 对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况时检测效果不好。泛化能力偏弱
- 损失函数设计不太好,在大小物体的处理上,由于损失函数的问题,产生的定位误差会直接影响到检测效果
1-3、yolo1的核心思想
YOLO的核心思想:就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。这是对目标检测算法最大的进步和启发。
1-4、yolo1的实现方法
总体流程:
方法一:将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在某个网格中,则这个网格就负责预测这个object。

配图:解释图式
对于这个图,这个狗狗就是一个object, 红色数字标1的矩形边框就是这个狗狗的真实边框,我们称之为真实的bounding box,真实的bounding box的中心刚好落在红色数字标2的矩形边框里面,这个边框就是我们说的网格,很明显,图中有49个这样的网格。所以根据上面的那句话我们可以得出一个结论:红色数字标2的网格负责预测狗狗这个物体
方法二:每个网格要预测2个bounding box,预测出来的bounding box我们称之为“预测的bounding box”,每个预测的bounding box不止包含(x, y, w, h)信息,还包含一个confidence值。
下面我们解释一下confidence值的意义。假设有个网格名字叫做网络A,它预测出来的两个bounding box分别叫做bb1和bb2。对应的confidence分别叫做cfd1和cfd2。
- 如果刚好有个object的中心落在网格A里面,则cfd1的值等于bb1与这个object真实的bounding box之间的IOU,即bb1与这个object真实的bounding box之间交集和并集的比值。
- 如果没有object的中心落在网格A里面,则cfd1等于0
方法三:如果某个object的中心落在某个网格上面,那么这个网格还要预测一个类别信息。否则则不用。
综上所述,在PASCAL VOC数据集中,物体有20个类别,输入的图片大小是(448, 448, 3),输出的tensor大小应该是(7, 7, 30),30是5+5+20得来的,(7, 7)表示总共把图片分成49个网格
二、yolo1的网络结构
2-1、网络结构分析
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。然后用1×1 reduction layers 紧跟 3×3 convolutional layers 的结构模块取代Goolenet的 inception modules 。对于Goolenet的 inception modules的了解可以参考我另外一篇博客,【Keras教学(5)】:使用函数式API搭建GooletNet卷积神经网络。
网络结构图如下:
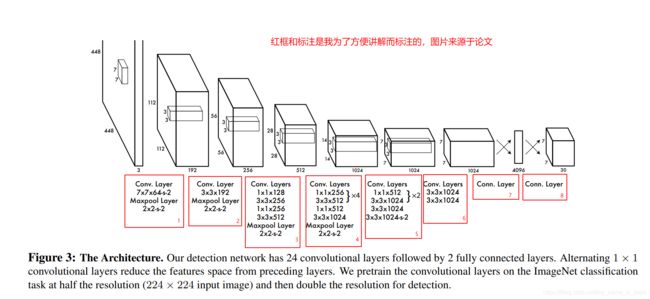
配图:yolo1的网络结构图
下面开始搭建yolo1神经网络,值得提前说明的两点是,卷积操作使用的激活函数论文作者选择的是leaky_relu,所有操作的padding选项都是'same'。
2-2、网络结构搭建
完整网络结构图如下,注意看注释,注意看注释,注意看注释
import tensorflow as tf
import tensorflow.keras.layers as KL
from tensorflow.keras.models import Model
input_images = KL.Input(shape=(448, 448, 3)) # 这里的尺寸针对的是PASCAL VOC数据集
# 1号红色标注框对应的代码
net = KL.Conv2D(64, (7, 7), strides=2, padding='same', activation=tf.nn.leaky_relu)(input_images)
net = KL.MaxPool2D((2, 2), strides=2, padding='same')(net)
# 2号红色标注框对应的代码
net = KL.Conv2D(192, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.MaxPool2D((2, 2), strides=2, padding='same')(net)
# 3号红色标注框对应的代码
net = KL.Conv2D(128, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(256, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(256, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.MaxPool2D((2, 2), strides=2, padding='same')(net)
# 4号红色标注框对应的代码
net = KL.Conv2D(256, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(256, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(256, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(256, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(1024, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.MaxPool2D((2, 2), strides=2, padding='same')(net)
# 5号红色标注框对应的代码
net = KL.Conv2D(512, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(1024, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(512, (1, 1), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(1024, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(1024, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(1024, (3, 3), strides=2, padding='same', activation=tf.nn.leaky_relu)(net)
# 6号红色标注框对应的代码
net = KL.Conv2D(1024, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
net = KL.Conv2D(1024, (3, 3), activation=tf.nn.leaky_relu, padding='same')(net)
# 7号红色标注框对应的代码
net = KL.Flatten()(net)
net = KL.Dense(4096, activation=tf.nn.leaky_relu)(net)
net = KL.Dropout(0.5)(net)
y = KL.Dense(1470, activation=tf.nn.leaky_relu)(net)
# 建立模型
model = Model([input_images], [y])
model.summary()
这种搭建是为了让同学们最直白简单地理解这个网络结构,其实还有更多好的方式,这些属于优化问题了,以后再详细聊。从这个网络结构可以看出前面说的那句话:用1×1 reduction layers 紧跟 3×3 convolutional layers 的结构模块取代Goolenet的 inception modules,自己感受一下是不是描述得很准确?很神奇吧,就是这么神奇。打印出来的结果如下:同学们对照结构图和打印结果,看看尺寸是不是对的就知道自己搭建过程有没有出错了。
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 448, 448, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 224, 224, 64) 9472
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 112, 112, 192) 110784
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 56, 56, 192) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 56, 56, 128) 24704
_________________________________________________________________
conv2d_3 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv2d_4 (Conv2D) (None, 56, 56, 256) 65792
_________________________________________________________________
conv2d_5 (Conv2D) (None, 56, 56, 512) 1180160
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 28, 28, 512) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 28, 28, 256) 131328
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 256) 131328
_________________________________________________________________
conv2d_9 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_10 (Conv2D) (None, 28, 28, 256) 131328
_________________________________________________________________
conv2d_11 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_12 (Conv2D) (None, 28, 28, 256) 131328
_________________________________________________________________
conv2d_13 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_14 (Conv2D) (None, 28, 28, 512) 262656
_________________________________________________________________
conv2d_15 (Conv2D) (None, 28, 28, 1024) 4719616
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 14, 14, 1024) 0
_________________________________________________________________
conv2d_16 (Conv2D) (None, 14, 14, 512) 524800
_________________________________________________________________
conv2d_17 (Conv2D) (None, 14, 14, 1024) 4719616
_________________________________________________________________
conv2d_18 (Conv2D) (None, 14, 14, 512) 524800
_________________________________________________________________
conv2d_19 (Conv2D) (None, 14, 14, 1024) 4719616
_________________________________________________________________
conv2d_20 (Conv2D) (None, 14, 14, 1024) 9438208
_________________________________________________________________
conv2d_21 (Conv2D) (None, 7, 7, 1024) 9438208
_________________________________________________________________
conv2d_22 (Conv2D) (None, 7, 7, 1024) 9438208
_________________________________________________________________
conv2d_23 (Conv2D) (None, 7, 7, 1024) 9438208
_________________________________________________________________
flatten (Flatten) (None, 50176) 0
_________________________________________________________________
dense (Dense) (None, 4096) 205524992
_________________________________________________________________
dropout (Dropout) (None, 4096) 0
_________________________________________________________________
dense_1 (Dense) (None, 1470) 6022590
=================================================================
Total params: 271,703,550
Trainable params: 271,703,550
Non-trainable params: 0
_________________________________________________________________
Process finished with exit code 0
其中最后的1470是7x7x30得来的。到时候这个数字要重新reshape成(7, 7, 30)。
本期的内容就到这里,我们下期见,附上教学目录
