ERNIE: 2.0带来了什么
目录
- 前言
- 一、ERNIE: Enhanced Representation through Knowledge Integration
-
-
-
- Knowledge Masking Strategies
- 对话语言模型
- 成绩
-
-
- 二、ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
-
-
-
- 多任务预训练
- Word-aware Pretraining Tasks
- Structure-aware Pretraining Tasks
- Semantic-aware Pretraining Tasks
- 成绩
-
-
前言
最近一段日子,我们很惊喜地看到越来越多的华夏面孔出现在自然语言处理领域的前沿。从最近叱诧风云的 XLNet 到上个星期自然语言处理顶会 ACL 2019 年的最佳长论文 (还有更多入会论文),主要负责人都是华人/国人。夹杂着这些好消息,带着 16 项中英文 SOTA 成绩,ERNIE 2.0 的发布更是把自然语言处理的舆论氛围推向了巅峰。就百度而言,无论在产品上如何遭人诟病,其依旧是 IT 从业者们的技术天堂,ERNIE 2.0 向我们展现了它的实力。本篇文章中,我们同样以论文作为标题开始我们的解读:
- ERNIE: Enhanced Representation through Knowledge Integration (19 April 2019)
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding (29 July 2019)
一、ERNIE: Enhanced Representation through Knowledge Integration
论文链接:https://arxiv.org/abs/1904.09223
代码链接:https://github.com/PaddlePaddle/ERNIE/tree/develop/ERNIE
在讲 2.0 版本之前,我们先回顾一下在 ERNIE 1.0 (以下统称 ERNIE) 中,百度做了什么,熟悉 1.0 的朋友可以先跳过这一节。ERNIE 的雏形来自于 2018 年 10 月发布的 BERT。关于 BERT 的简介可参考笔者另一篇博文中的相关内容:链接。ERNIE 沿袭了 BERT 中绝大多数的设计思路,包括 预训练 (Pretraining) 加 微调 (Fine-tuning) 的流程,去噪自编码 (DAE, abbr. denoising autoencoding) 的模型本质,以及 Masked Language Model 和 Next Sentence Prediction 的训练环节。主要的不同,在于 ERNIE 采用了更为复杂的 Masking 策略:Knowledge Masking Strategies,并针对对话型数据引入一套新的训练机制:对话语言模型 (Dialogue Language Model)。
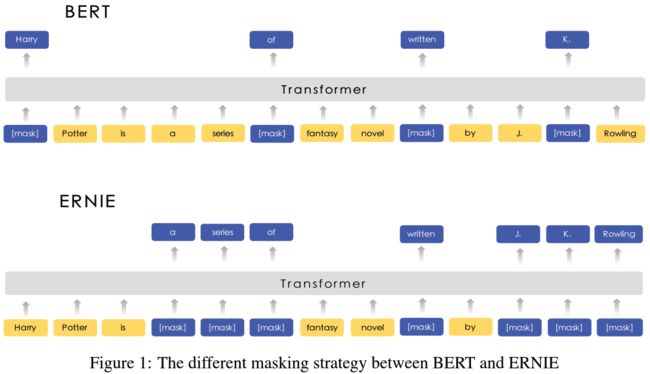
从图中我们可以看到,ERNIE 不再仅仅只是如同 BERT 中那样,简单地对 token 进行随机选取,而后附上 Mask,而是同时对 token 所在的短语中其他词进行 Masking。这样的设计初衷,在于将更高级的语义信息融入到最终的 embedding 中。事后证明这样的设计,尽管在英文的下游任务中没能刷新 SOTA 成绩,但在对付中文 NLP 任务上相当凑效。
Knowledge Masking Strategies
为了将这样的设计思想融入到模型里,ERNIE 选择逐步推进,将预训练分为三个阶段,分别采用三种 Masking 机制:

- Basic-level Masking:如同 BERT,随机选取 15% 的语料单元。
- Phrase-level Masking:改为随机挑选短语进行 Masking;短语的识别在于预先使用语言工具进行标注,英文语料使用词法分析以及语义组块,中文语料应用中文分词技术。
- Entity-level Masking:改为随机挑选命名实体进行 Masking;预先使用命名实体识别技术对命名实体进行标注,例如人名、地名、组织名。
对话语言模型
上文中的 Knowledge Masking Strategies 应用于一般的句子型语料,而 ERNIE 在训练数据中增加了问答形式下的对话型文本。针对这一类特殊的文本输入,ERNIE 特别地采用另一种 Masking 模型,将 Masked Language Model 取而代之:对话语言模型 (DLM, abbr. Dialogue Language Model)。
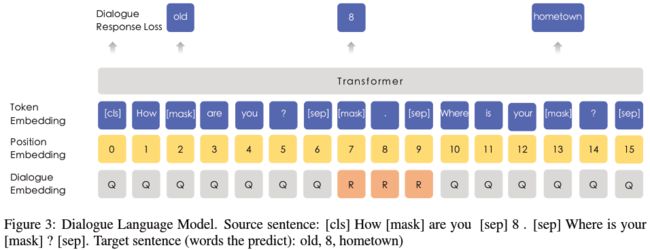
DLM 中,不再构建如同 “[CLS] + Sentence_A + [SEP] + Sentence_B + [SEP]” 的句子对,而是如同 “[CLS] + Query + [SEP] + Response_A + [SEP] + Response_B + [SEP]” 的对话三元组,是否上下文连续的二分类训练目标转为预测该对话是否真实 (real/fake)。三元组随机地采用 QRQ、QRR、QQR 其中一种构建形式,上面的例子便是其中的 QRR。为了给处理后的数据添加噪声,部分的 Query 和 Response 使用不相关的语句进行随机替换,以强制模型学习对话中的语境关联。
在训练一般语料时,ERNIE 采用 Knowledge Masking Strategies 改造后的 Masked LM;而在训练对话型语料时,ERNIE 采用 DLM;两者交替使用。
成绩
为了方便进行对比,试验中的 ERNIE 采用同 BERT-base 同样的超参数,包含 12 个 Transformer 层、768 个隐藏单元以及 12 个自注意力头。训练语料来自于中文维基百科、百度百科、百度新闻和百度贴吧 (对话型数据),总共包含约 1.7 亿个中文语句。在对繁体字进行简体转换后,词汇集的大小最终确定在 17,964。最终,ERNIE 在以下五个中文数据集上战胜 BERT,得到了 SOTA 结果:
- 自然语言推理:XNLI
- 语义相似度:LCQMC
- 命名实体识别:MSRA-NER
- 情绪分析:ChnSentiCorp
- 问答:NLPCC-DBQA
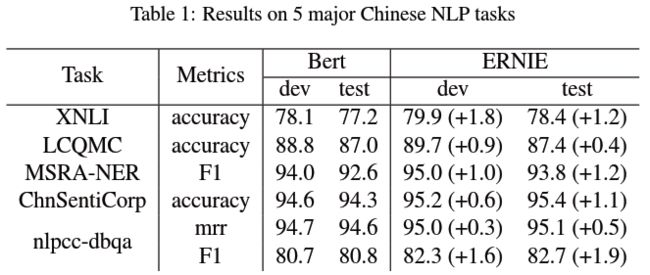
作为 BERT 的简单改良版,我们很遗憾没能看到模型表现有大范围的提升,论文中甚至出现不止一处英文书写不规范的问题,显得论文的发表有些急于求成。但这无疑是一个很好的开端,为 ERNIE 2.0 刷新各类中英文成绩做了铺垫。
二、ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
论文链接:https://arxiv.org/abs/1907.12412
代码链接:https://github.com/PaddlePaddle/ERNIE
ERNIE 2.0 将 1.0 版本中的功能特性全部予以保留,并在此基础上做更为丰富的扩展和延伸。论文指出,近几年来基于未标注语料进行无监督编码的预训练模型,包括 Word2Vec、ELMo、GPT、BERT、XLNet、ERNIE 1.0, 存在一个共同缺陷:仅仅只是利用了 token 与 token 之间的 共现 (Co-occurance) 信息。当两个 token 拥有相似的上下文语境时,最终的编码必然具有极高的相似度。这使得模型无法在词向量中嵌入语料的 词汇 (lexical)、语法 (syntatic) 以及 语义 (semantic) 信息。为此,ERNIE 2.0 首次引入 连续预训练 (Continual Pre-training) 机制 —— 以串行的方式进行多任务学习,学习以上三类特征。设计的初衷在于模拟人类的学习行为:利用已经积累的知识,持续地进行新的学习。
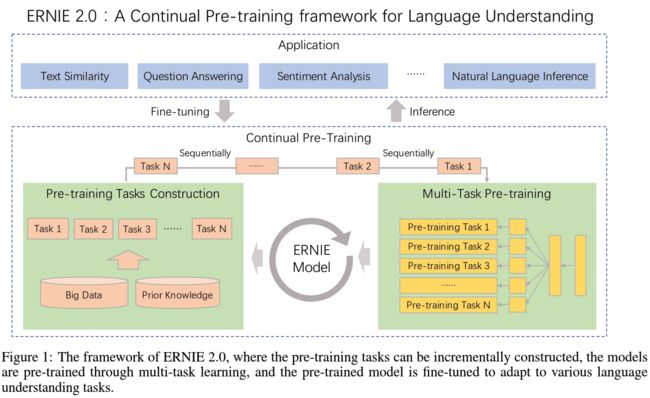
多任务预训练
多任务学习并不是什么特别新鲜的事物,BERT 中 Masked LM + Next Sentence Prediction 便是一种范例。多任务学习更直接地表现在损失函数的变化上,如下图。
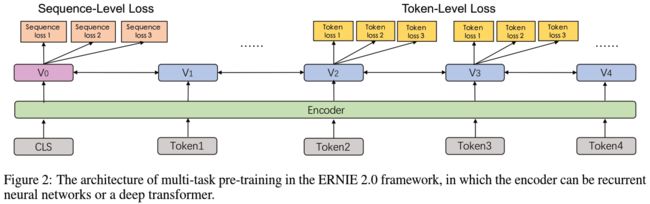
这些任务并非强制性地加入到训练流程中,而是可以针对下游任务,有选择性地挑选一些加入模型。需要注意的是,每次添加任务都需要重新进行一次完整的训练。在开始训练前,每一个任务都会得到一套独立的编码,称为 Task Embedding,附加在原始的语料输入上。在应用于下游任务的微调时,这一套编码会用于模型的初始化。完整的 ERNIE 2.0 架构如下图所示:
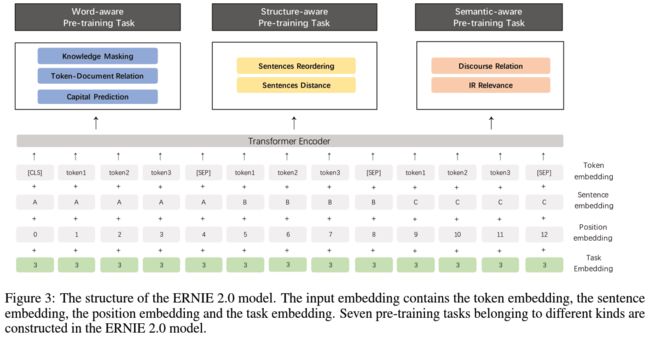
需要指出的是,在多数情况下 ERNIE 2.0 输入的是由两个句子组成的句子对 (如同 BERT 中那样),但在应用于对话型数据时使用 ERNIE 1.0 中的 对话语言模型 (DLM, abbr. Dialogue Language Model),构建对话三元组,具体的形式请见上一节。
多任务预训练的模式使得模型能够在下游任务中具备更优秀的表现;但相对地,模型的可迁移性将会下降。由于部分任务专门针对特定下游任务设计,当模型的应用场景发生变化时,可能将不得不重新进行预训练以保证模型效果。
Word-aware Pretraining Tasks
多任务中的第一类,用于捕捉词汇 (lexical) 级别的信息。
- Knowledge Masking Task:沿袭 ERNIE 1.0 中的 Knowledge Masking Strategies,预测被 Mask 的对象。
- Capitalization Prediction Task:预测对象是否大小写 (cased/uncased);ERNIE 2.0 认为大写开头的词汇具备特定的含义,例如人名、地名、机构名等,这将对命名实体识别一类的下游任务有所帮助。
- Token-Document Relation Prediction Task:预测对象是否在文档中其他文段有出现;正案例通常包含文档的关键词以及语言通用词,因此添加这一任务有助于模型将更多的注意力放在这一类词汇上。
Structure-aware Pretraining Tasks
这一类用于捕捉语料中语法 (syntactic) 级别的信息,有助于模型应用在自然语言推理、问答等领域。
- Sentence Recording Task:针对文档中的每一个段落,以句子为单位划分为 1 1 1 ~ m m m 段,而后对整个文档所有文段进行打乱排列,对每一个文段预测原始位置,成为 k k k 分类问题 ( k = ∑ n = 1 m n ! k=\sum_{n=1}^mn! k=∑n=1mn!)。
- Sentence Distance Task:取代 Next Sentence Prediction,预测输入句子对的相对距离;三分类问题, 0 0 0 代表两个句子在同一篇文档且距离相近, 1 1 1 代表两个句子在同一片文档但距离较远, 2 2 2 代表两个句子在不同文档。
Semantic-aware Pretraining Tasks
最后一类用于提取语义 (semantic) 类的信息。
- Discourse Relation Task:预测两个句子之间的语法及修辞关联。
- IR Relevance Task:专门为百度搜索引擎日志设计的任务,预测 Query-Title 对的相关性;三分类问题, 0 0 0、 1 1 1、 2 2 2 分别代表强相关、弱相关以及不相关;这将有助于标题自动生成以及文本摘要类任务。
成绩
模型的流程架构上,ERNIE 2.0 相对于 BERT 及 ERNIE 1.0 无疑都更为复杂,但参数结构基本保持一致 (仅添加了可训练的 Task Embedding)。试验中,ERNIE2.0-base 的参数大小向 BERT-base 靠齐,包含 12 个注意力层、768 个隐藏单元以及 12 个自注意力头;而 ERNIE2.0-large 则相应地对齐 BERT-large,包含 24 个注意力层、1024 个隐藏单元以及 16 个自注意力头。最终,ERNIE 2.0 以小于 BERT、XLNet 数倍的训练语料,在 16 项任务上全面超越两者,获得了 SOTA 成绩:
- 自然语言推理 (英文):GLUE (CoLA, SST-2, MNLI, RTE, WNLI, QQP, MRPC, STS-B, QNLI, AX)
- 机器阅读理解 (中文):CMRC 2018, DRCD, DuReader
- 自然语言推理 (中文):XNLI
- 语义相似度 (中文):LCQMC, BQ Corpus
- 命名实体识别 (中文):MSRA-NER (SIGHAN 2006)
- 情绪分析 (中文):ChnSentiCorp
- 问题 (中文):NLPCC-DBQA
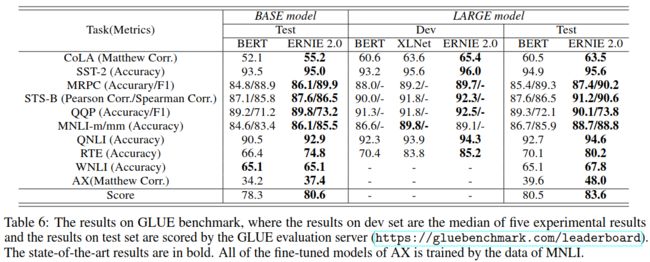
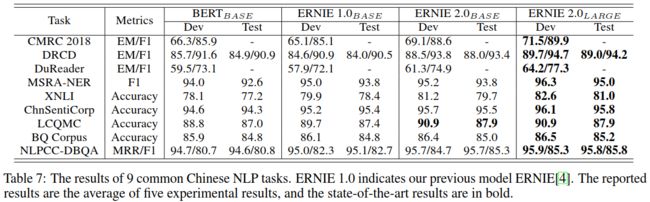
ERNIE 2.0 创新地将过去单一的预训练流程拆解为串行的多个预训练任务,无疑是其最大的贡献。如何通过多任务的形式将更多的语法信息有效地融入到模型的自编码中,相信会成为未来新的研究方向。