目标检测—RetinaNet与Focal loss分析与实现
点击查看原文:《Focal Loss for Dense Object Detection》
目标检测分为one-stage和two-stage的方法,two-stage的代表网络之一Faster R-CNN准确率较高,但是检测速度慢。相对之下one-stage的网络计算速度快但是准确率降低较多。针对此现象,一些研究者分析了one-stage网络检测准确率的主要原因,为密集检测器在训练时所遭遇的前景-背景类数量的极度不平衡。所以他们重构标准交叉熵损失函数为Focal Loss,通过降低易分类样本和背景类样本的loss,来解决这种类不平衡问题。相应地,RetinaNet作为验证Focal Loss效果的检测器,是以ResNet和FPN作为特征提取器,后面连接两个结构相似的subnet,分别是classification subnet and regression subnet.
介绍
在之前的目标检测器中,two-stage的网络依靠RPN普遍取得更好的结果,因为此结构有效地缓解了类不平衡问题。第一个stage生成一个稀疏的候选目标框位置,迅速地将候选目标区域减小到了一个很小的数量,过滤了几大部分的背景样本,第二阶段使用CNN对每个候选框进行前景或背景的分类。与之相对,One stage检测器可以被应用于常规的,密集的多尺度,多纵横比的目标位置样本。其中,YOLO和SSD在准确率低10~40%的情况下比two-stage要更快,而有效利用特征金字塔和anchor框的RetinaNet,则通过引用一种解决训练时类不平衡问题的损失函数达到了state-of-the-art准确率,超过了现有的two-stage检测器。这个损失函数着眼于在难例的稀疏集上进行训练,然后避免在训练时大量的easy negatives将整个检测器淹没。它能够动态的缩放交叉熵loss,当正确类的置信率增加,它对应的尺度因子会逐渐衰减到0。
最早的经典计算机视觉目标检测方法是滑动窗口模式。随着深度学习的繁荣,two-stage检测器很快的支配了目标检测领域。R-CNN将第二阶段的分类器升级为卷积网络极大提高了准确率,RPN将第二阶段分类器和候选区域生成器整合到了单一卷积网络中,形成了Faster R-CNN框架。One-stage检测器速度更快但是准确率比two-stage方法要低,即使是在更大的计算预算上。但是RetinaNet检测器可以在取得甚至超越two-stage准确率的情况下还能跑的更快,其得益于新的损失函数和RPN引入的anchors的理念以及FPN使用的特征金字塔。几乎所有的目标分类方法都面临着训练时类极大不平衡的问题,这样的不平衡造成了两个问题:(1)训练很低效,因为很多位置都是easy negatives对学习并没有帮助;(2)总体来看,easy negatives会淹没整个训练使得模型退化。Focal loss可以自然地解决这个问题,能在所有样本存在的情况下进行有效学习。
Focal loss
Focal Loss是设计来解决one-stage目标检测里训练时有着极端的前后景样本不平衡的场景的。二分类的交叉熵(CE)loss的式子如下:
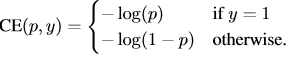
定义Pt为
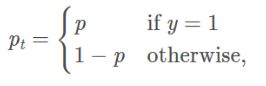
所以重写
![]()
一个普遍的方法来解决这个类不平衡问题就是引入一个权重因子α∈[0,1]对于类1,1−α对于类-1。实际中α可能被设置为类频率的倒数或者被当做是一个超参数使用交叉验证了设置。 α-balanced CE loss写为:
![]()
密集检测器在训练时遭遇的大量的类不平衡会淹没掉交叉熵loss,好分类的负样本占据了loss里的绝大部分,而且还主导了梯度。在α可以平衡正负样本的基础上,添加了一个带有着眼于难负例的调制因子。所以最终的Focal loss为
![]()
由上式可得(1)当一个样本被错误分类,pt是很小的,那么对应的调制因子就接近于1,进而这个loss是不受影响的。如果pt→1,那么调制因子趋近于0,这个好分类样本的loss就被降低权重。(2)focusing参数γ平滑地调整了好分类样本被降低权重的比率。
RetinaNet
RetinaNet是由一个主网络和两个指定任务的子网络组成的统一的网络结构。主网络负责计算整个输入图像的卷积特征。第一个子网络对主网络的输出进一步计算完成目标分类;第二个子网络负责边框回归。

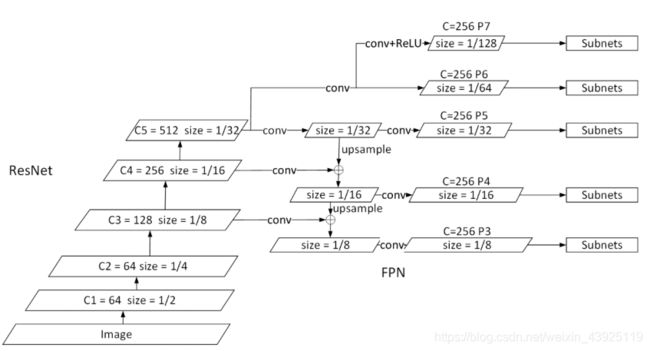
3.1FPN
RetinaNet采用FPN(Feature Pyramid Network )作为骨干部分。FPN通过自上而下的通道和横向的连接来扩展了一个标准的卷积网络,以从单一分辨率的输入图像中有效的提取出丰富的,多尺度的特征金字塔。金字塔的每一层都可以在不同尺度上对目标进行检测。RetinaNet在ResNet结构上构建了FPN,所有的金字塔层的通道数都为256。
3.2Anchors
RetinaNet中使用了RPN变体相似的平移不变性的anchor框。这些anchors的面积在P3到P7上从322到5122。每个金字塔级上都使用三种纵横比的anchors{1:2,1:1,2:1},和3种尺度大小{20,21/3,22/3},所以每一级上有9种anchors,共覆盖了相对于原图大小上的32-813个像素。每个anchor都会被赋予一个长为K的one-hot向量的分类目标和一个4维的边框回归目标。当使用IoU阈值为0.5时,大于0.5的anchor则被赋值为相应的GT;如果IoU在[0,0.4]被赋予为背景,介于中间的在训练时将会被忽略。边框回归目标是通过计算anchor和其被赋予的目标框的补偿得到的。
3.3Classification and Box Regression Subnets
分类子网络会对每个位置的每个anchor(9个)的每个类别(K个)进行概率预测。这个子网络是在每个FPN级上联接一个FCN,参数在所有金字塔级上是共享的。从给定的金字塔级上得到一个有C个通道的输入特征图,经过4个stride=3×3,filters=C的卷积层,每个都跟着一个ReLU激活函数,然后再跟一个带有9K个滤波器的3×3的卷积层。最后联接sigmoid激活函数对于每个位置输出9K个二分类预测值。分类子网络不与框回归子网络共享参数。预测框回归与目标分类子网络并行,设计和分类子网络相同除了最后每个位置4A个输出元。对于每个位置的A=9个anchors,这4个输出元预测了anchor与对应GT的相对补偿。
实现
4.1实验设置
运行代码是https://github.com/yhenon/pytorch-retinanet。使用的深度学习框架是pytorch, pytorch, torchvision, numpy的版本分别为1.1.0,0.3.1,1.17.5。实验配置的GPU为单卡1050MAX-Q(之前的低配,所以随机采样5000张图片运行)。代码初始化参数设置为epoch=1,batch_size=2。损失函数默认为Focal Loss,参数alpha = 0.25,gamma = 2.0。对于图片的预处理操作,训练时采用归一化,扩增和改变尺寸,验证时不用扩增。默认使用的模型为ResNet50,在代码中表现为depth=50。训练时使用Adam优化器,初始学习率设置为1e-5,当网络的评价指标高于3次不提升的时候,通过降低网络的学习率来提高网络性能。
除了RetinaNet子网络的最后一层,其他所有新增的层都采用σ=0.01的高斯分布和b=0进行初始化。对于分类子网络的最后一层卷积层,设置初始偏置项为b=−log((1−π)/π,这里π被指定在训练开始时,所有的anchor都需要被标注为带有~π置信率的前景,在所有实验中π=.01。
4.2运行步骤
根据上述源代码运行首先安装了pandas,pycocotools,opencv-python,requests等包,然后运行train.py训练模型,其中会从网上自动下载ResNet的预训练模型。当训练模型完成后,则评估训练集的mAP。训练完成的模型自动保存在相应的路径,在进行验证的时候,运行coco_validation.py载入模型并评估验证集。在可视化的时候加载自己的模型,并从对应的文件夹中读取测试图片,运行visualize.py对图片进行目标检测并标出结果。


![]()
4.3结果分析
由于计算设备限制,分别用官方的基于ResNet50的RetinaNet预训练模型,和随机采样5000张图片的训练集上训练得到的基于ResNet18和ResNet50的RetinaNet的模型,对验证集的5000张图片进行测试,所以与官方表现相差较大。
其中IoU是阈值指,area是指 segmentation mask中像素的数量, COCO数据集中小目标物体数量比大目标物体更多,small是指面积小于等于1024(32x32=1024), medium是指面积大于1024并且小于9216( 96x96=9216),large是指面积大于9216. maxDets是指评测指标允许每张图片最多计算top-scoring 检测结果的个数。此外,对于自己训练的基于ResNet18和ResNet50的模型,ResNet50比ResNet18的结果稍微好一些,其中AR比AP提升的更加明显。骨干网络提取到的特征对于检测的效果有较大影响,ResNet50比ResNet18提取到的特征更加高级抽象。观察不同IOU的AP和AR表现,说明小物体相对大物体较难检测。

4.4可视化

4.5Loss详解
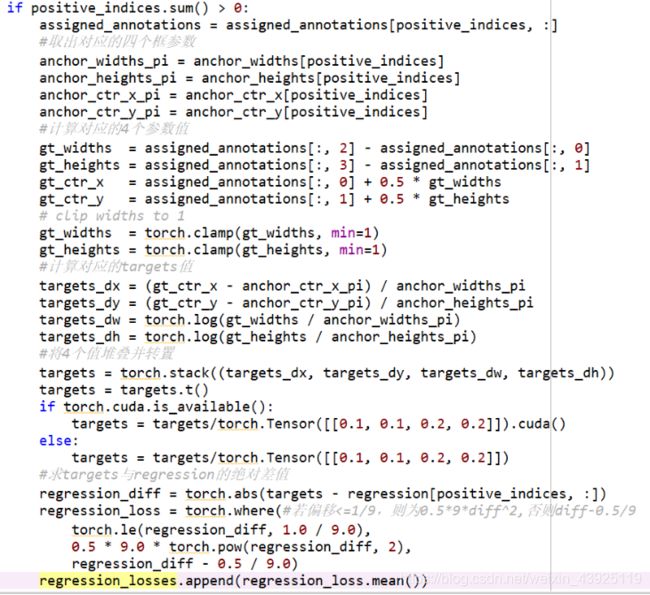
RetinaNet模型的training loss一共有两项,分别是目标分类loss和检测框的回归loss。网络的原始输出分别是每个anchor的类别score和其对于ground truth检测框的回归值,分类子网输出BWH980,回归子网输出BWH94。对于分类loss,部分实现代码如图16,targets为9*80的数组,保留网络分类的结果。代码中,在已经计算过所有anchor和gt框之间的IoU值后,再选出每个anchor与标注框的最大IoU和其索引,将大于0.5的targets置为1,小于0.4的置为0,位于中间值的是-1对loss无贡献。在实现普通BCE的基础上,乘上alpha权重因子和focal loss的权重,最后得到分类loss的均值。Focal loss的参数设置,alpha=0.25,gamma = 2.0。回归loss的部分实现代码如图17所示,如果检测有前景类的话,取出anchor的四个框的参数值,并计算gt_widths,gt_heights,gt_ctr_x,gt_ctr_y,然后用上述值计算targets,包括targets_dx,targets_dy,targets_dw,targets_dh。计算targets与网络预测的regression的绝对差值,最后比较此偏差量与1/9的大小,分别取对应的regression_loss。网络训练时,将class_loss和regression_loss直接相加作为total loss。

[1] Lin T Y , Goyal P , Girshick R , et al. Focal Loss for Dense Object Detection[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017:2999-3007.
[2]代码来源:https://github.com/yhenon/pytorch-retinanet