基于主成分分析(PCA)的人脸识别具体实现
1.PCA概述
PCA(Principal Component Analysis),即主成分分析方法,它的提出用作对原有数据进行简化。主要是通过数据降维的方式:降维主要是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的,同时可以为我们节省大量的时间和成本。PCA是一种unsupervised的映射方法,这里主要区分于LDA,它是一种supervised映射方法。
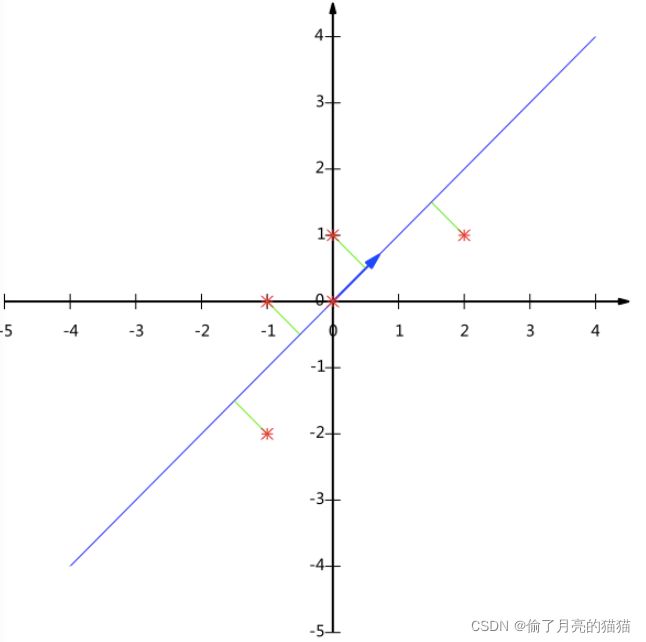
如下2-dim图特征映射到正交坐标轴:

PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
方差:是用来计算每一个变量(观察值)与总体均数之间的差异性。
协方差:协方差用来衡量两个变量的总体误差,如果两个变量的变化趋势一致,协方差就是正值,说明两个变量正相关。如果两个变量的变化趋势相反,协方差就是负值,说明两个变量负相关。
协方差矩阵:它度量的是维度与维度之间的关系,而非样本与样本之间。协方差矩阵的主对角线上的元素是各个维度上的方差,其他元素是两两维度间的协方差。
思考:为什么要用方差协方差?
我们要选择最能代表样本数据的k个维度,简单来说,在空间中把大量数据点映射到k条不相关的直线上,如何保证重叠的点最少?最能表征数据特征?
1.方差主要反映数据之间的离散程度,方差越大,离散程度越大,选择与样本均值差异最大的方向作为新的坐标轴即新的维度,最能反映原始数据的特征。
2.如上图考虑的是二维转一维的情况,现在考虑三维转二维。我们不仅要看每一个维度上的方差,而且还要看两个维度之间的相关性。也就是说,希望这两个维度之间不相关。利用协方差矩阵来反映多个维度之间的关系。
2.PCA计算实例
如下图,用PCA的方法将这组二维数据降到一维,输入矩阵的每行已经是零均值,所以我们可以直接计算:

最后一行用P的第一行 乘以 数据矩阵 来 还原数据,就得到了降维后的数据表示。
降维后的投影如下图:
3.PCA算法流程

4.人脸识别实现应用
在ORL人脸库上做了实验。ORL人脸库包括40个目录,每个目录下有10张图像,每个目录表示一个不同的人,共400幅人脸图像构成。每幅图像的大小均为112*92。对每一个目录下的图像,这些图像是在不同的时间、不同的光照、不同的面部表情(睁眼/闭眼,微笑/不微笑)和面部细节(戴眼镜/不戴眼镜)环境下采集的。所有的图像是在较暗的均匀背景下拍摄的,拍摄的是正脸(有些带有略微的侧偏)。
(1)按算法流程计算
1:求训练数据平均值
2:各训练数据减去平均值
3:计算数据的协方差矩阵
4:计算协方差矩阵的特征值、特征向量
5:计算训练数据在特征空间的投影
6:计算测试数据投影与原数据投影间的欧氏距离,距离最小的作为预测值
预测结果如下图所示:

预测成功的例子:

预测失败的例子:

代码附录:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import os
def trainFaceMat():
# 将每个人的10张图片取前7张图片读取为训练数据,共280张
path = "./att_faces/s"
trainFaceMat = []
for i in range(1, 41):
for j in range(1, 8):
imgPath = path + str(i) + "/" + str(j) + ".pgm"
# img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转为灰度图
img = cv2.imread(imgPath,0) # 通过opencv读取灰度图片,flag = 0,8位深度,1通道
# img = np.resize(img,(img.shape[0]*img.shape[1],1))
img = np.array(img).reshape(-1,1) #转成n行1列,压缩为1维 112*92 变为10304*1
trainFaceMat.append(img)
trainFaceMat = np.array(trainFaceMat)
trainFaceMat = np.squeeze(trainFaceMat) #去掉维度1
# trainFaceMat = np.concatenate(trainFaceMat,axis = 1).T # axis=1按照第二个维度叠加,第一个维度保持不变,再取转置 返回280*10304
return trainFaceMat
# print(trainFaceMat.shape) # 280*10304
def testFaceMat():
# 将每个人的10张图片取后3张图片读取为训练数据,共120张
path = "./att_faces/s"
testFaceMat = []
for i in range(1, 41):
for j in range(8, 11):
imgPath = path + str(i) + "/" + str(j) + ".pgm"
img = cv2.imread(imgPath,0) # 通过opencv读取灰度图片
# img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转为灰度图
# img = np.resize(img,(img.shape[0]*img.shape[1],1))
img = np.array(img).reshape(-1,1) #转成n行1列,压缩为1维 112*92 变为10304*1
# img = np.resize(img,(1,img.shape[0]*img.shape[1]))
testFaceMat.append(img)
testFaceMat = np.array(testFaceMat)
testFaceMat = np.squeeze(testFaceMat)
# testFaceMat = np.concatenate(testFaceMat,axis = 1).T # axis=1按照第二个维度叠加,第一个维度保持不变,再取转置 返回280*10304
return testFaceMat # 120*10304
def meanFaceMat():#计算训练样本的平均值矩阵 1*10304
meanFaceMat = np.mean(trainFaceMat(), axis=0) # 每一列的和除行数,得到平均值
meanFaceMat = np.expand_dims(meanFaceMat,axis = 0)
return meanFaceMat
# print("meanFaceMat.shape[0] ",meanFaceMat.shape[0]) # 1
# print("meanFaceMat.shape[1] ",meanFaceMat.shape[1]) # 10304
def normTrainFaceMat():# 去除平均值,得到规格化后的训练样本矩阵
# trainFaceMat 大小为 280 * 10304, meanFaceMat 大小为 1 * 10304
normTrainFaceMat = trainFaceMat() - meanFaceMat()
return normTrainFaceMat
#print(normTrainFaceMat.shape) # 280*10304
def eigenface():
# 计算协方差矩阵,特征值和特征向量
# normTrainFaceMat = normTrainFaceMat()
covariance = np.cov(normTrainFaceMat())
# 求得协方差矩阵的特征值和特征向量
eigenvalue, featurevector = np.linalg.eig(covariance)
# 获取特征值按降序排序对应原矩阵的下标
sorted_Index = np.argsort(eigenvalue)
# 保留前K个最大的特征值对应的特征向量 k=100
topk_evecs = featurevector[:,sorted_Index[:-100-1:-1]]
# 获得训练样本的特征脸空间
eigenface = np.dot(np.transpose(normTrainFaceMat()), topk_evecs)
# 计算训练样本在特征脸空间的投影
# 训练样本在特征脸空间的投影eigen_train_sample
eigen_train_sample = np.dot(normTrainFaceMat(), eigenface)
return eigenface,eigen_train_sample
# 返回训练样本的特征脸空间,及训练样本特征脸空间的投影
def prediction(eigen_test_sample,eigen_train_sample):
minDistance = 999999999
# 计算出每个人的最小距离,如果对检测图进行检测,距离大于最小距离,则表示这张图是这个人
for j in range(1,eigen_train_sample.shape[0]):
tmp_distance = np.linalg.norm(eigen_test_sample - eigen_train_sample[j])
#fact = ( i - i % 3 ) / 3
if minDistance > tmp_distance:
predict = (j - j % 7) / 7 #(i - i % 10) / 10
minDistance = tmp_distance
return predict
def readimagearray():
# 将所有图片读取到readimage中
path = "./att_faces/s"
ImgList = []
for i in range(1, 41):
for j in range(1, 11):
imgPath = path + str(i) + "/" + str(j) + ".pgm"
img = cv2.imread(imgPath) # 通过opencv读取图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转为灰度图
# img = np.resize(img,(img.shape[0]*img.shape[1],1))
# img = np.array(img).reshape(-1,1)
ImgList.append(img)
ImgList = np.array(ImgList)
return ImgList
if __name__ == "__main__":
# 人脸识别测试
test = testFaceMat()
mean = meanFaceMat()
# 去除平均值,得到规格化后的识别样本矩阵
normTestFaceMat = test - mean
# 计算测试样本在特征脸空间的投影
abc = eigenface()
eigenface = abc[0]
eigen_train_sample = abc[1]
eigen_test_sample = np.dot(normTestFaceMat, eigenface)
# print('aaaaaaa',eigen_test_sample.shape[0])
# 计算欧式距离,找到匹配人脸
right_num = 0
for i in range(1,eigen_test_sample.shape[0]):
predict = prediction(eigen_test_sample[i],eigen_train_sample)
predict = int(predict)
fact = (i - i % 3) / 3
if predict == fact:
right_num += 1
print(f'第{i+1}张图片预测成功')
output_path = r'./means_Output3'
if not os.path.exists(output_path):
os.mkdir(output_path)
inputlist = np.array(readimagearray())
imgfact = np.array(inputlist[int(fact*10)+i%3])
predictimg = np.array(inputlist[int(fact*10)])
plt.axis('off')
plt.imshow(imgfact,cmap="gray")
plt.savefig('./means_Output3/'+ '第' + str(int(fact)+1) + '个人的第' + str(i%3+1) + '张测试图', bbox_inches='tight', pad_inches=0)
plt.imshow(predictimg,cmap="gray")
plt.savefig('./means_Output3/'+ '第' + str(int(fact)+1) + '个人的第' + str(i%3+1) + '张测试图的预测图', bbox_inches='tight', pad_inches=0)
# plt.show()
# cv2.waitKey()
else:
print(f'第{i+1}张图片预测失败')
output_path = r'./means_Output4'
if not os.path.exists(output_path):
os.mkdir(output_path)
inputlist = np.array(readimagearray())
imgfact = np.array(inputlist[int(fact*10)+i%3])
predictimg = np.array(inputlist[int(predict*10)])
plt.axis('off')
plt.imshow(imgfact,cmap="gray")
plt.savefig('./means_Output4/'+ '第' + str(int(fact)+1) + '个人的第' + str(i%3+1) + '张测试图', bbox_inches='tight', pad_inches=0)
plt.imshow(predictimg,cmap="gray")
plt.savefig('./means_Output4/'+ '第' + str(int(fact)+1) + '个人的第' + str(i%3+1) + '张测试图的预测图', bbox_inches='tight', pad_inches=0)
print("accuracy:%.2f%%" % (right_num / float(eigen_test_sample.shape[0]) * 100))
(2)用Sklearn里的PCA模块去实现人脸识别
当从112*92=10304个像素点中去k=100个特征值时还原人的面部特征如下:

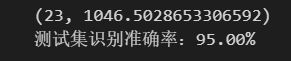
测试集识别的准确度:
代码附录:
from json import load
from operator import index
import cv2
import numpy as np
# 导入sklearn的pca模块
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
def imgarray():
# 将所有图片读取为arrayList
path = "./att_faces/s"
ImgList = []
for i in range(1, 41):
for j in range(1, 11):
imgPath = path + str(i) + "/" + str(j) + ".pgm"
img = cv2.imread(imgPath) # 通过opencv读取图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转为灰度图
# img = np.resize(img,(img.shape[0]*img.shape[1],1))
# img = np.array(img).reshape(-1,1)
ImgList.append(img)
ImgList = np.array(ImgList)
return ImgList
def loadlabel():
images = []
labels = []
faces = imgarray()
for index,face in enumerate(faces):
# enumerate函数可以同时获得索引和值
image = faces[index]
# image = cv2.imread(face,0) # cv.imread(filename[, flags]) flag = 0表示8位深度,1通道
images.append(image)
labels.append(int(index/10+1))
images = np.array(images)
labels = np.array(labels)
return labels,images #转化为元组输出
def perimg():
# 图像数据矩阵转换为一维
image_data = []
for image in imgarray():
data = image.flatten()
# a是个矩阵或者数组,a.flatten()就是把a降到一维,默认是按横的方向降
image_data.append(data)
# print(image_data[0].shape)
image_data = np.array(image_data)
return image_data
if __name__ == "__main__":
img = perimg()
label = loadlabel()
X = img
#print(X)
y = label[0]
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(X, y, test_size=0.2) # train训练,test测试
# 训练PCA模型
pca=PCA(n_components=100) # 保留100个纬度
pca.fit(x_train) # 训练过程
# 返回训练集和测试集降维后的数据集
x_train_pca = pca.transform(x_train) # 转换过程
x_test_pca = pca.transform(x_test)
print(x_train_pca.shape) # 320个训练集,保留了100个特征
print(x_test_pca.shape) # 80个测试集,保留了100个特征
V = pca.components_
V.shape
# print(V.shape)
# 100个特征脸
# 创建画布和子图对象
fig, axes = plt.subplots(10,10
,figsize=(15,15)
,subplot_kw = {"xticks":[],"yticks":[]} #不要显示坐标轴
)
#填充图像
for i, ax in enumerate(axes.flat):
ax.imshow(V[i,:].reshape(112,92),cmap="gray") #reshape规定图片的大小,选择色彩的模式
plt.show()
# 模型创建与训练
model = cv2.face.EigenFaceRecognizer_create()
model.train(x_train,y_train)
# 预测
res = model.predict(x_test[2])
print(res)
# 测试数据集的准确率
ress = []
true = 0
false = 0
for i in range(len(y_test)):
res = model.predict(x_test[i])
if y_test[i] == res[0]:
true = true + 1
else:
false = false + 1
print('测试集识别准确率:%.2f%%'% ((true/len(y_test))*100))