Learning and Meta-Learning of Stochastic Advection-Diffusion-Reaction Systems from Sparse Measuremen
论文信息
题目:Learning and Meta-Learning of Stochastic Advection-Diffusion-Reaction Systems from Sparse Measurements(对流扩散响应)
作者:Xiaoli Chen(a,b), Jinqiao Duan©, George Em Karniadakis(b,d)
期刊、会议:computational physics
单位:
a Center for Mathematical Sciences & School of Mathematics and Statistics, Huazhong University of Science and Technology, Wuhan 430074, China
b Division of Applied Mathematics, Brown University, Providence, RI 02912, USA
c Department of Applied Mathematics, Illinois Institute of Technology, Chicago, IL 60616, USA
d Pacific Northwest National Laboratory, Richland, WA 99354, USA
基础
Polynomial chaos (PC), also called Wiener chaos expansion, is a non-sampling-based method to determine the evolution of uncertainty in a dynamical system when there is probabilistic uncertainty in the system parameters.
- Arbitrary polynomial chaos:Recently chaos expansion received a generalization towards the arbitrary polynomial chaos expansion (aPC),[1] which is a so-called data-driven generalization of the PC. Like all polynomial chaos expansion techniques, aPC approximates the dependence of simulation model output on model parameters by expansion in an orthogonal polynomial basis. The aPC generalizes chaos expansion techniques towards arbitrary distributions with arbitrary probability measures, which can be either discrete, continuous, or discretized continuous and can be specified either analytically (as probability density/cumulative distribution functions), numerically as histogram or as raw data sets.
论文动机
- 通过建立适当的目标函数和使用必要的正则化技术来获得一些未知的参数或与空间/时间有关的材料性质
- 然而,在许多实际问题中,例如在地下输运[3,4]中,我们必须处理一个混合问题,因为我们通常要对材料性质进行一些测量,对状态变量进行一些测量
- 这里,考虑描述浓度场的非线性平流-扩散-反应(ADR)的这种“混合”问题,并根据机器学习的最新发展提出了新的算法。
问题定义
Problem set
- determine the entire stochastic diffusivity and stochastic concentration fields as well three (deterministic) parameters from a few multi-fidelity mea- surements of the concentration field at random points in space-time.
本文方法
Here, we first employ the standard PINN and a stochastic ver- sion, sPINN, to solve forward and inverse problems governed by a nonlinear advection-diffusion-reaction (ADR) equation,
- Assuming we have some sparse measurements of the concentration field at random or pre-selected locations.
- Subsequently, we attempt to optimize the hyper-parameters of sPINN by using the Bayesian optimization method (meta-learning), and compare the results with the empirically selected hyper-parameters of sPINN
The PINN is trained using a composite multi- fidelity network, first introduced in [2], that learns the correlations between the multi-fidelity data and predicts the unknown values
sPINN:Physics-informed neural networks for stochastic PDEs
sPINN是基于任意多项混沌[17,18]表示随机性,并将其与PINN相结合
We consider the following stochastic PDE (SPDE)
u t + N [ u ( x , t ; ω ) ; k ( x ; ω ) ] = 0 , x ∈ D , t ∈ ( 0 , T ] , ω ∈ Ω u_{t}+\mathscr{N}[u(x, t ; \omega) ; k(x ; \omega)]=0, x \in \mathcal{D}, t \in(0, T], \omega \in \Omega ut+N[u(x,t;ω);k(x;ω)]=0,x∈D,t∈(0,T],ω∈Ω
with the initial and boundary conditions:
u ( x , 0 ; ω ) = u 0 ( x ) , x ∈ D B X [ u ( x , t ; ω ) ] = 0 , x ∈ ∂ D , t ∈ ( 0 , T ] \begin{array}{ll} u(x, 0 ; \omega)=u_{0}(x), & x \in \mathcal{D} \\ \mathbb{B}_{X}[u(x, t ; \omega)]=0, & x \in \partial \mathcal{D}, t \in(0, T] \end{array} u(x,0;ω)=u0(x),BX[u(x,t;ω)]=0,x∈Dx∈∂D,t∈(0,T]
Here Ω \Omega Ω is the random space


the diffusion term k ( x ; ω ) k(x ; \omega) k(x;ω) can be approximated by:
k N N ( x ; ω j ) = k 0 ( x ) + ∑ M k i ( x ) λ i ξ i , j k_{N N}\left(x ; \omega_{j}\right)=k_{0}(x)+\sum^{M} k_{i}(x) \sqrt{\lambda_{i}} \xi_{i, j} kNN(x;ωj)=k0(x)+∑Mki(x)λiξi,j
Correspondingly, the solution u at the j-th snapshot can be approximated
by
u N N ( x , t ; ω j ) ≈ ∑ α = 0 P u α ( x , t ) ψ α ( ξ j ) u_{N N}\left(x, t ; \omega_{j}\right) \approx \sum_{\alpha=0}^{P} u_{\alpha}(x, t) \psi_{\alpha}\left(\xi_{j}\right) uNN(x,t;ωj)≈α=0∑Puα(x,t)ψα(ξj)
{ ψ α } α = 1 P \left\{\psi_{\alpha}\right\}_{\alpha=1}^{P} {ψα}α=1P为多元正交多项式基的集合,最高多项式阶为r.
The loss function is defined as:
M S E = M S E u + M S E k + M S E f M S E=M S E_{u}+M S E_{k}+M S E_{f} MSE=MSEu+MSEk+MSEf
where
M S E u = 1 N ∗ N u ∑ j = 1 N ∑ i = 1 N u [ u N N ( x u ( i ) , t u ( i ) ; ω j ) − u ( x u ( i ) , t u ( i ) ; ω j ) ] 2 M S E k = 1 N ∗ N k ∑ j = 1 N ∑ i = 1 N k [ k N N ( x k ( i ) ; ω j ) − k ( x k ( i ) ; ω j ) ] 2 M S E f = 1 N ∗ N f ∑ i = 1 N ∑ i = 1 N f [ f N N ( x f ( i ) , t f ( i ) ; ω j ) ] 2 \begin{aligned} M S E_{u} &=\frac{1}{N * N_{u}} \sum_{j=1}^{N} \sum_{i=1}^{N_{u}}\left[u_{N N}\left(x_{u}^{(i)}, t_{u}^{(i)} ; \omega_{j}\right)-u\left(x_{u}^{(i)}, t_{u}^{(i)} ; \omega_{j}\right)\right]^{2} \\ M S E_{k} &=\frac{1}{N * N_{k}} \sum_{j=1}^{N} \sum_{i=1}^{N_{k}}\left[k_{N N}\left(x_{k}^{(i)} ; \omega_{j}\right)-k\left(x_{k}^{(i)} ; \omega_{j}\right)\right]^{2} \\ M S E_{f} &=\frac{1}{N * N_{f}} \sum_{i=1}^{N} \sum_{i=1}^{N_{f}}\left[f_{N N}\left(x_{f}^{(i)}, t_{f}^{(i)} ; \omega_{j}\right)\right]^{2} \end{aligned} MSEuMSEkMSEf=N∗Nu1j=1∑Ni=1∑Nu[uNN(xu(i),tu(i);ωj)−u(xu(i),tu(i);ωj)]2=N∗Nk1j=1∑Ni=1∑Nk[kNN(xk(i);ωj)−k(xk(i);ωj)]2=N∗Nf1i=1∑Ni=1∑Nf[fNN(xf(i),tf(i);ωj)]2
方法对比
实验结果
Results for the deterministic PDE
We consider the following nonlinear ADR equation:
{ u t = ν 1 u x x − ν 2 u x + g ( u ) , ( x , t ) ∈ ( 0 , π ) × ( 0 , 1 ] u ( x , 0 ) = u 0 ( x ) , x ∈ ( 0 , π ) u ( 0 , t ) = 1 , u x ( π , t ) = 0 , t ∈ ( 0 , 1 ] \left\{\begin{array}{ll} u_{t}=\nu_{1} u_{x x}-\nu_{2} u_{x}+g(u), & (x, t) \in(0, \pi) \times(0,1] \\ u(x, 0)=u_{0}(x), & x \in(0, \pi) \\ u(0, t)=1, u_{x}(\pi, t)=0, & t \in(0,1] \end{array}\right. ⎩⎨⎧ut=ν1uxx−ν2ux+g(u),u(x,0)=u0(x),u(0,t)=1,ux(π,t)=0,(x,t)∈(0,π)×(0,1]x∈(0,π)t∈(0,1]
We define the residual f = u t − ν 1 u x x + ν 2 u x − g ( u ) f=u_{t}-\nu_{1} u_{x x}+\nu_{2} u_{x}-g(u) f=ut−ν1uxx+ν2ux−g(u),The L 2 L_{2} L2 error of a function h h h is defined as E h = ∥ h N N − h true ∥ L 2 E_{h}=\left\|h_{N N}-h_{\text {true}}\right\|_{L 2} Eh=∥hNN−htrue∥L2, and the relative L 2 L_{2} L2 error is defined as E h = ∥ h N N − h true ∥ L 2 ∥ h true ∥ L 2 E_{h}=\frac{\left\|h_{N N}-h_{\text {true}}\right\|_{L 2}}{\left\|h_{\text {true}}\right\|_{L 2}} Eh=∥htrue∥L2∥hNN−htrue∥L2
Single-fidelity data
u 0 ( x ) = exp ( − 10 x ) u_{0}(x)=\exp (-10 x) u0(x)=exp(−10x), g ( u ) = λ 1 u λ 2 g(u)=\lambda_{1} u^{\lambda_{2}} g(u)=λ1uλ2
We aim to infer the parameters ν1; ν2; λ1; λ2 given some sparse measurements of u in addition to initial and boundary conditions.The correct values for the unknown parameters are: ν 1 = 1 , ν 2 = 1 , λ 1 = − 1 , λ 2 = 2 \nu_{1}=1, \nu_{2}=1, \lambda_{1}=-1, \lambda_{2}=2 ν1=1,ν2=1,λ1=−1,λ2=2
We employ the following loss function in the PINN:
M S E = M S E u + w ∇ u ∗ M S E ∇ u + M S E f M S E=M S E_{u}+w_{\nabla_{u}} * M S E_{\nabla u}+M S E_{f} MSE=MSEu+w∇u∗MSE∇u+MSEf
where
M S E u = 1 N u ∑ i = 1 N u ∣ u N N ( t u i , x u i ) − u i ∣ 2 M S E ∇ u = 1 N u ∑ i = 1 N u ∣ ∇ u N N ( t u i , x u i ) − ∇ u i ∣ 2 M S E f = 1 N f ∑ i = 1 N f ∣ f N N ( t f i , x f i ) ∣ 2 \begin{aligned} M S E_{u} &=\frac{1}{N_{u}} \sum_{i=1}^{N_{u}}\left|u_{N N}\left(t_{u}^{i}, x_{u}^{i}\right)-u^{i}\right|^{2} \\ M S E_{\nabla u} &=\frac{1}{N_{u}} \sum_{i=1}^{N_{u}}\left|\nabla u_{N N}\left(t_{u}^{i}, x_{u}^{i}\right)-\nabla u^{i}\right|^{2} \\ M S E_{f} &=\frac{1}{N_{f}} \sum_{i=1}^{N_{f}}\left|f_{N N}\left(t_{f}^{i}, x_{f}^{i}\right)\right|^{2} \end{aligned} MSEuMSE∇uMSEf=Nu1i=1∑Nu∣∣uNN(tui,xui)−ui∣∣2=Nu1i=1∑Nu∣∣∇uNN(tui,xui)−∇ui∣∣2=Nf1i=1∑Nf∣∣fNN(tfi,xfi)∣∣2
N u = 64 , N f = 1089 N_{u}=64, N_{f}=1089 Nu=64,Nf=1089,and is the reference solution. u i u^{i} ui The error of the parameters is defined as E ν 1 = ν 1 train − ν 1 ν 1 , E ν 2 = ν 2 train − ν 2 ν 2 , E λ 1 = λ 1 train − λ 1 λ 1 E_{\nu_{1}}=\frac{\nu_{1 \operatorname{train}}-\nu_{1}}{\nu_{1}}, E_{\nu_{2}}=\frac{\nu_{2 \operatorname{train}}-\nu_{2}}{\nu_{2}}, E_{\lambda_{1}}=\frac{\lambda_{1 \operatorname{train}}-\lambda_{1}}{\lambda_{1}} Eν1=ν1ν1train−ν1,Eν2=ν2ν2train−ν2,Eλ1=λ1λ1train−λ1 and E λ 2 = λ 2 train − λ 2 λ 2 E_{\lambda_{2}}=\frac{\lambda_{2 \operatorname{train}}-\lambda_{2}}{\lambda_{2}} Eλ2=λ2λ2train−λ2
选了四种采样方式
- t = 0:1 and t = 0:9
- t = 0:1, t = 0:9, and x = π
- training data randomly
- training data on a regular lattice in the x − t domain
研究了 w ∇ u = 0 w_{\nabla u}=0 w∇u=0和 w ∇ u = 1 w_{\nabla u}=1 w∇u=1情况
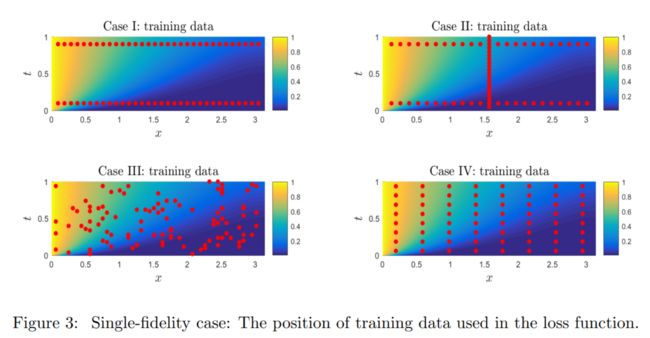
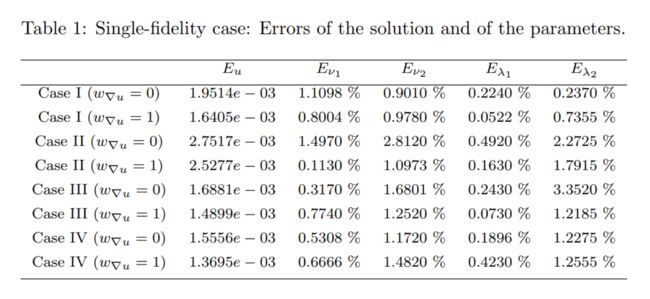
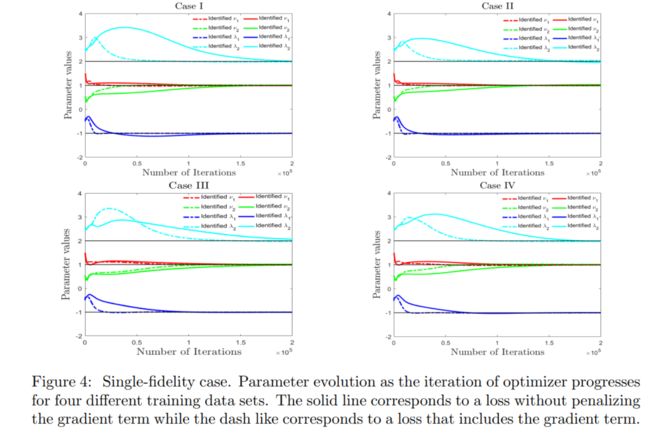
- The convergence is faster if we include the gradient penalty term w ∇ u = 1 w_{\nabla_{u}}=1 w∇u=1
Multi-fidelity data
In many real-world applications, the training data is small and possibly inadequate to obtain even a rough estimation of the parameters.demonstrate how we can resolve this issue by resorting to supplementary data of lower fidelity that may come from cheaper instruments of lower resolution or from some computational models. We will refer to such data as \lowfidelity" and we will assume that we have a large number of such data points unlike the high-fidelity data.Here, we will employ a composite network inspired by the recent work on multi-fidelity NNs in [2].
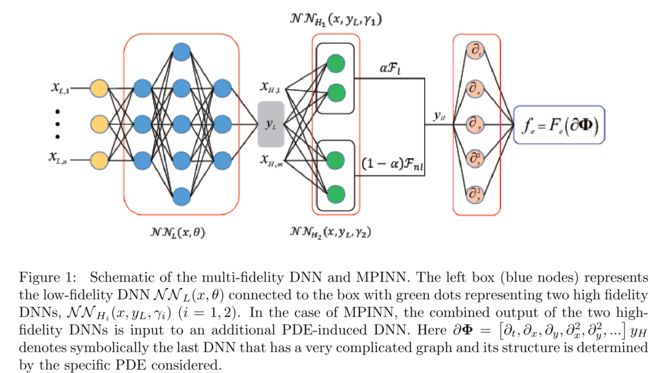
The estimator of the high-fidelity model (HF) using the correlation structure to correct the low-fidelity model (LF), can be expressed as
u H F ( x , t ) = h ( u L F ( x , t ) , x , t ) u_{H F}(x, t)=h\left(u_{L F}(x, t), x, t\right) uHF(x,t)=h(uLF(x,t),x,t)
where h is a correlation map to be learned, which is based on the correlation between the HF and LF data. We have two NN for low- and highfidelity, respectively, as follows:
u L F = N N L F ( x L F , t L F , w L F , b L F ) u H F = N N H F ( x H F , t H F , u L F , w H F , b H F ) \begin{aligned} u_{L F} &=\mathcal{N} \mathcal{N}_{L F}\left(x_{L F}, t_{L F}, w_{L F}, b_{L F}\right) \\ u_{H F} &=\mathcal{N} \mathcal{N}_{H F}\left(x_{H F}, t_{H F}, u_{L F}, w_{H F}, b_{H F}\right) \end{aligned} uLFuHF=NNLF(xLF,tLF,wLF,bLF)=NNHF(xHF,tHF,uLF,wHF,bHF)
Through minimizing the mean-squared-error loss function
M S E = M S E u L F + M S E u H F + M S E f H F M S E=M S E_{u_{L F}}+M S E_{u_{H F}}+M S E_{f H F} MSE=MSEuLF+MSEuHF+MSEfHF
where
M S E u L F = 1 N L F ∑ i = 1 N L F ∣ u L F ( t u L H i , x u L F i ) − u L H i ∣ 2 M S E u H F = 1 N H F ∑ i = 1 N H F ∣ u H F ( t u H F i , x u H F i ) − u H F i ∣ 2 M S E f H F = 1 N f ∑ i = 1 N f ∣ f H F ( t f H F i , x f H F i ) ∣ 2 \begin{aligned} M S E_{u_{L F}} &=\frac{1}{N_{L F}} \sum_{i=1}^{N_{L F}}\left|u_{L F}\left(t_{u_{L H}}^{i}, x_{u_{L F}}^{i}\right)-u_{L H}^{i}\right|^{2} \\ M S E_{u_{H F}} &=\frac{1}{N_{H F}} \sum_{i=1}^{N_{H F}}\left|u_{H F}\left(t_{u_{H F}}^{i}, x_{u_{H F}}^{i}\right)-u_{H F}^{i}\right|^{2} \\ M S E_{f_{H F}} &=\frac{1}{N_{f}} \sum_{i=1}^{N_{f}}\left|f_{H F}\left(t_{f_{H F}}^{i}, x_{f_{H F}}^{i}\right)\right|^{2} \end{aligned} MSEuLFMSEuHFMSEfHF=NLF1i=1∑NLF∣∣uLF(tuLHi,xuLFi)−uLHi∣∣2=NHF1i=1∑NHF∣∣uHF(tuHFi,xuHFi)−uHFi∣∣2=Nf1i=1∑Nf∣∣fHF(tfHFi,xfHFi)∣∣2
Set the true parameters
ν 1 = 1 , ν 2 = 1 , λ 1 = − 1 and λ 2 = 2 \nu_{1}=1, \nu_{2}=1, \lambda_{1}=-1 \text { and } \lambda_{2}=2 ν1=1,ν2=1,λ1=−1 and λ2=2
- The low-fidelity training data is obtained by the second-order finite difference solution ith erroneous parameter values ν 1 = 1.25 , ν 2 = 1.25 , λ 1 = − 0.75 , and λ 2 = 2.5 \nu_{1}=1.25, \nu_{2}=1.25, \lambda_{1}=-0.75, \text { and } \lambda_{2}=2.5 ν1=1.25,ν2=1.25,λ1=−0.75, and λ2=2.5, we choose 64 point of low-fidelity, N L F = 64 N_{L F}=64 NLF=64
- hHgh-fidelity data is obtained by the numerical solution when ν 1 = 1 , ν 2 = 1 , λ 1 = − 1 and λ 2 = 2 \nu_{1}=1, \nu_{2}=1, \lambda_{1}=-1 \text { and } \lambda_{2}=2 ν1=1,ν2=1,λ1=−1 and λ2=2, (a), N H F = 12 N_{H F}=12 NHF=12,(b), N H F = 6 N_{H F}=6 NHF=6

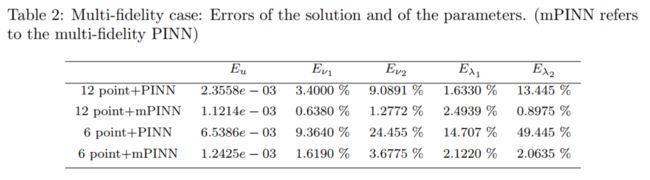
As we can see, the parameter inference using the multi-fidelity PINN is much better than the single-fidelity predictions. Moreover, if we have a small number of HF data, e.g. N H F = 6 N_{H F}=6 NHF=6, the results of the multi-fidelity PINN are still quite accurate
Results for the stochastic case
We consider the following stochastic nonlinear ADR equation:
{ u t = ( k ( x ; ω ) u x ) x − ν 2 u x + g ( u ) + f ( x , t ) , ( x , t , ω ) ∈ ( x 0 , x 1 ) × ( 0 , T ] × Ω u ( x , 0 ) = 1 − x 2 , x ∈ ( x 0 , x 1 ) u ( x 0 , t ) = 0 , u ( x 1 , t ) = 0 , t ∈ ( 0 , T ] \left\{\begin{array}{ll}u_{t}=\left(k(x ; \omega) u_{x}\right)_{x}-\nu_{2} u_{x}+g(u)+f(x, t), & (x, t, \omega) \in\left(x_{0}, x_{1}\right) \times(0, T] \times \Omega \\ u(x, 0)=1-x^{2}, & x \in\left(x_{0}, x_{1}\right) \\ u\left(x_{0}, t\right)=0, u\left(x_{1}, t\right)=0, & t \in(0, T]\end{array}\right. ⎩⎨⎧ut=(k(x;ω)ux)x−ν2ux+g(u)+f(x,t),u(x,0)=1−x2,u(x0,t)=0,u(x1,t)=0,(x,t,ω)∈(x0,x1)×(0,T]×Ωx∈(x0,x1)t∈(0,T]
g ( u ) = λ 1 u λ 2 and f ( x , t ) = 2 g(u)=\lambda_{1} u^{\lambda_{2}} \text { and } f(x, t)=2 g(u)=λ1uλ2 and f(x,t)=2
Forward problem
Mean-squared-error loss function:
M S E = M S E I + M S E B + M S E f M S E=M S E_{I}+M S E_{B}+M S E_{f} MSE=MSEI+MSEB+MSEf
where
M S E I = 1 N ∗ N u ∑ s = 1 N ∑ i = 1 N I [ u N N ( x u ( i ) , 0 ; ω s ) − u ( x u ( i ) , 0 ; ω s ) ] 2 M S E B = 1 N ∗ N B ∑ s = 1 N ∑ i = 1 N B [ u N N ( x 0 , t u ( i ) ; ω s ) − u ( x 0 , t u ( i ) ; ω s ) ] 2 + 1 N ∗ N B ∑ s = 1 N ∑ i = 1 N B [ u N N ( x 1 , t u ( i ) ; ω s ) − u ( x 1 , t u ( i ) ; ω s ) ] 2 M S E f = 1 N ∗ N f ∑ s = 1 N ∑ i = 1 N f [ f N N ( x f ( i ) , t f ( i ) ; ω s ) − f ( x f ( i ) , t f ( i ) ; ω s ) ] 2 \begin{aligned} M S E_{I}=& \frac{1}{N * N_{u}} \sum_{s=1}^{N} \sum_{i=1}^{N_{I}}\left[u_{N N}\left(x_{u}^{(i)}, 0 ; \omega_{s}\right)-u\left(x_{u}^{(i)}, 0 ; \omega_{s}\right)\right]^{2} \\ M S E_{B}=& \frac{1}{N * N_{B}} \sum_{s=1}^{N} \sum_{i=1}^{N_{B}}\left[u_{N N}\left(x_{0}, t_{u}^{(i)} ; \omega_{s}\right)-u\left(x_{0}, t_{u}^{(i)} ; \omega_{s}\right)\right]^{2} \\ &+\frac{1}{N * N_{B}} \sum_{s=1}^{N} \sum_{i=1}^{N_{B}}\left[u_{N N}\left(x_{1}, t_{u}^{(i)} ; \omega_{s}\right)-u\left(x_{1}, t_{u}^{(i)} ; \omega_{s}\right)\right]^{2} \\ M S E_{f}=& \frac{1}{N * N_{f}} \sum_{s=1}^{N} \sum_{i=1}^{N_{f}}\left[f_{N N}\left(x_{f}^{(i)}, t_{f}^{(i)} ; \omega_{s}\right)-f\left(x_{f}^{(i)}, t_{f}^{(i)} ; \omega_{s}\right)\right]^{2} \end{aligned} MSEI=MSEB=MSEf=N∗Nu1s=1∑Ni=1∑NI[uNN(xu(i),0;ωs)−u(xu(i),0;ωs)]2N∗NB1s=1∑Ni=1∑NB[uNN(x0,tu(i);ωs)−u(x0,tu(i);ωs)]2+N∗NB1s=1∑Ni=1∑NB[uNN(x1,tu(i);ωs)−u(x1,tu(i);ωs)]2N∗Nf1s=1∑Ni=1∑Nf[fNN(xf(i),tf(i);ωs)−f(xf(i),tf(i);ωs)]2
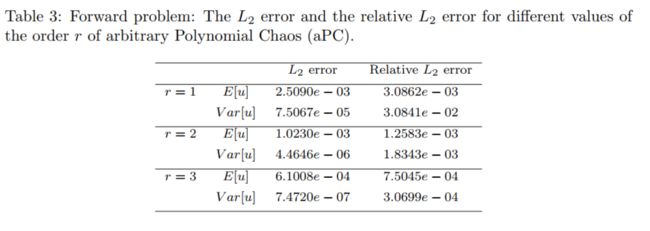

Inverse problem
we will infer the stochastic process k ( x , ω ) k(x, \omega) k(x,ω) as well as the parameters
ν 2 , λ 1 , λ 2 \nu_{2}, \lambda_{1}, \lambda_{2} ν2,λ1,λ2 and the solution u ( x , t , ω ) u(x, t, \omega) u(x,t,ω)
We minimize the following mean-squared-error loss function:
M S E = 10 ∗ ( M S E u + M S E k ) + M S E f M S E=10 *\left(M S E_{u}+M S E_{k}\right)+M S E_{f} MSE=10∗(MSEu+MSEk)+MSEf
Meta-learning
We employ Bayesian Optimization (BO) to learn the optimum structure of the NNs. We use dK hidden layers and d K d_{K} dK neurons per layer for w K w_{K} wK mean neural network, and d U d_{U} dUhidden layers and w U w_{U} wU neurons per layer for
ki(x); (i = 1; :::M) and uα(x; t); (α = 0; 1; ::) neural network
The target is
Target = 10 ∗ ( M S E u + M S E k ) + E ν 2 + E λ 1 + E λ 2 \text {Target}=10 *\left(M S E_{u}+M S E_{k}\right)+E_{\nu_{2}}+E_{\lambda_{1}}+E_{\lambda_{2}} Target=10∗(MSEu+MSEk)+Eν2+Eλ1+Eλ2
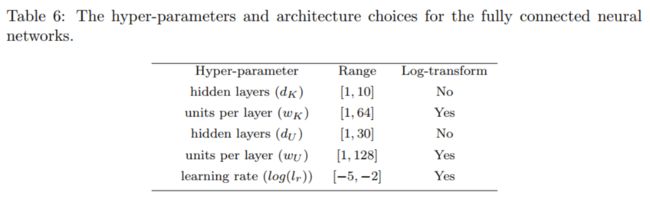

These results suggest that we need a larger neural network for both k and u
总结:
- We addressed here a special inverse problem governed by a stochastic nonlinear advection-diffusion-reaction (ADR) equation
- We designed composite neural networks (NNs), including NNs induced by the stochastic ADR equation, and relied on spectral expansions to represent stochasticity in order to deal with the sparsity in data.
- We also presented a Bayesian Optimization method for learning the hyper-parameters of this composite NN as it is time consuming to find the proper NNs by trial and error.
下步工作 - An important component missing in our study is
quantifying the uncertaintyof the NN approximation as was first done in related work in [12] addressing the total uncertainty. This is a serious but complex issue requiring the use of multiple methods to interpret this uncertainty in an objective way, and we will pursue this line of research in future work - one could also consider using
several other methods, includinggenetic algorithms [19], the greedy method [20], hyperband [21, 22]as well as blended versions of the aforementioned methods or even another NN, like an RNN in conjunction with reinforcement learning [23], to search for the best architecture.
[1] M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural
networks: A deep learning framework for solving forward and inverse
problems involving nonlinear partial differential equations, Journal of
Computational Physics 378 (2019) 686{707
[2] X. Meng, G. E. Karniadakis, A composite neural network that learns
from multi-fidelity data: Application to function approximation and
inverse pde problems, arXiv preprint arXiv:1903.00104 (2019).
[3] A. M. Tartakovsky, C. O. Marrero, D. Tartakovsky, D. Barajas-Solano,
Learning parameters and constitutive relationships with physics informed deep neural networks, arXiv preprint arXiv:1808.03398 (2018).
[4] D. A. Barajas-Solano, A. M. Tartakovsky, Approximate bayesian model
inversion for pdes with heterogeneous and state-dependent coefficients,
Journal of Computational Physics (2019).
[5] M. Raissi, P. Perdikaris, G. E. Karniadakis, Numerical gaussian processes for time-dependent and nonlinear partial differential equations,
SIAM Journal on Scientific Computing 40 (2018) A172{A198.
[6] G. Pang, L. Yang, G. E. Karniadakis, Neural-net-induced gaussian process regression for function approximation and pde solution, Journal of
Computational Physics 384 (2019) 270{288.
[7] J. Han, A. Jentzen, E. Weinan, Solving high-dimensional partial differential equations using deep learning, Proceedings of the National
Academy of Sciences 115 (2018) 8505{8510.
[8] T. Q. Chen, Y. Rubanova, J. Bettencourt, D. K. Duvenaud, Neural
ordinary differential equations, in: Advances in neural information processing systems, pp. 6571{6583.
[9] P. Chaudhari, A. Oberman, S. Osher, S. Soatto, G. Carlier, Deep relaxation: partial differential equations for optimizing deep neural networks,
Research in the Mathematical Sciences 5 (2018) 30.
[10] J. Sirignano, K. Spiliopoulos, Dgm: A deep learning algorithm for solving partial differential equations, Journal of Computational Physics 375
(2018) 1339{1364.
[11] T. Qin, K. Wu, D. Xiu, Data driven governing equations approximation
using deep neural networks, Journal of Computational Physics (2019).
[12] D. Zhang, L. Lu, L. Guo, G. E. Karniadakis, Quantifying total uncertainty in physics-informed neural networks for solving forward and inverse stochastic problems, Journal of Computational Physics 397 (2019)108850.
[13] J. S. Bergstra, R. Bardenet, Y. Bengio, B. K´egl, Algorithms for hyperparameter optimization, in: Advances in neural information processing
systems, pp. 2546{2554.
[14] J. Snoek, H. Larochelle, R. P. Adams, Practical bayesian optimization
of machine learning algorithms, in: Advances in neural information
processing systems, pp. 2951{2959.
[15] J. Snoek, O. Rippel, K. Swersky, R. Kiros, N. Satish, N. Sundaram,
M. Patwary, M. Prabhat, R. Adams, Scalable bayesian optimization
using deep neural networks, in: International conference on machine
learning, pp. 2171{2180.
[16] G. Pang, L. Lu, G. E. Karniadakis, fpinns: Fractional physics-informed
neural networks, SIAM Journal on Scientific Computing 41 (2019)
A2603{A2626.
[17] X. Wan, G. E. Karniadakis, Multi-element generalized polynomial chaos
for arbitrary probability measures, SIAM Journal on Scientific Computing 28 (2006) 901{928.
[18] J. A. Paulson, E. A. Buehler, A. Mesbah, Arbitrary polynomial chaos
for uncertainty propagation of correlated random variables in dynamic
systems, IFAC-PapersOnLine 50 (2017) 3548{3553.
[19] M. Mitchell, An introduction to genetic algorithms, MIT press, 1998.
[20] Y. Li, S. Osher, Coordinate descent optimization for l1 minimization
with application to compressed sensing; a greedy algorithm, Inverse
Problems and Imaging 3 (2009) 487{503.
[21] L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, A. Talwalkar, Hyperband: A novel bandit-based approach to hyperparameter optimization,
Journal of Machine Learning Research 18 (2018)
[22] S. Falkner, A. Klein, F. Hutter, Bohb: Robust and efficient hyperparameter optimization at scale, arXiv preprint arXiv:1807.01774 (2018).
[23] Y. Jaafra, J. L. Laurent, A. Deruyver, M. S. Naceur, A review of metareinforcement learning for deep neural networks architecture search,
arXiv preprint arXiv:1812.07995 (2018).
[24] Y. He, J. Lin, Z. Liu, H. Wang, L.-J. Li, S. Han, Amc: Automl for
model compression and acceleration on mobile devices, in: Proceedings
of the European Conference on Computer Vision (ECCV), pp. 784{800