(学习笔记02) CNN对CIFAR-10图像数据集分类(tensorflow)
CNN对CIFAR-10图像数据集分类(tensorflow)
本节将继续学习机器学习的分类开发应用,我们将使用卷积神经网络对CIFAR-10数据集进行图像分类。
CIFAR-10数据集介绍
CIFAR-10 数据集共有60000张彩色图像,这些图像大小为32×32,分为10个类,每类6000张图。
| 总数量 | 图片尺寸 | 训练集数量 | 测试集数量 |
|---|---|---|---|
| 60000 | 32×32 | 50000 | 10000 |
整个数据集被分为5个training batches 和 1个test batch,且每个batch有10000张图片。
- test batch:随机从每类选择1000张图片组成(总共10个类)。
- training batches:从剩下的图片中随机选择,但每类的图片不是平均分给batch的(即一些training batches中某类图片可能比较多),总数为每类5000张图片。
这些类别是完全互斥的,在automobile和trucks中,automobiles包括轿车、越野车等。trucks只包括大型卡车。两者都不包括皮卡。

关于CIFAR-10数据集更多详细的介绍可通过官网查询:CIFAR-10数据集
CIFAR-10数据集跟上一节用到的MNIST数据集的比较:
| 数量 | RGB | 图像大小 | |
|---|---|---|---|
| CIFAR-10数据集 | 5万个训练样本和1万个测试样本 | 三通道彩色图像 | 32×32 |
| MNIST数据集 | 6万个训练样本和1万个测试样本 | 灰度图像 | 28×28 |
其次,CIFAR-10数据集它的色彩和噪点比较多,同一个分类,比如说,在卡车这个分类里,卡车的角度、颜色和大小都不一样,所以CIFAR-10图像识别难度比MNIST数据集要高得多。
环境搭建与上一节相同,我们将继续在Jupyter Notebook中对模型进行训练。
模型训练
1. 下载并读取数据集
import urllib.request
import os
import tarfile
# 下载
url = 'https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'
filepath = 'xxx/data/cifar-10-python.tar.gz'
if not os.path.isfile(filepath):
result = urllib.request.urlretrieve(url,filepath)
print('downloaded:',result)
else:
print('Data file already exists.')
# 解压
if not os.path.exists("xxx/data/cifar-10-batches-py"):
tfile = tarfile.open("xxx/data/cifar-10-python.tar.gz",'r:gz')
result = tfile.extractall('xxx/Desktop/data/')
print('Extracted to ./xxx/data/cifar-10-batches-py/')
else:
print('Directory already exists.')
其中’xxx’为下载数据的保存路径。第一次执行上图程序的时候,程序会检查你是否已经下载过CIFAR-10数据集,如果它没有找到这个文件的话,就会自动下载文件并进行解压;如果已经下载,它会显示提示信息“Data file already exists.”、“Directory already exists.”。
2. 导入数据集
我们先定义了函数 load_CIFAR_batch( ) 来读取一个批次的样本。
import os
import numpy as np
import pickle as p
# pickle提供了一个简单的持久化功能,可以将对象以文件的形式存放在磁盘上
def load_CIFAR_batch(filename):
with open(filename,'rb') as f:
data_dict = p.load(f, encoding = 'bytes')
images = data_dict[b'data']
labels = data_dict[b'labels']
images = images.reshape(10000,3,32,32)
images = images.transpose(0,2,3,1)
labels = np.array(labels)
return images,labels
- 先是通过 reshape() 函数将原始数据的结构调整为:B(Batches:批数量)、C(Channle:通道数)、W(Width:图像宽度)、H(Height:图像高度)。
images = images.reshape(10000,3,32,32)
其中批数量为10000,共有RGB三个颜色通道,图像的大小为 32×32。
- tensorflow 处理图像数据的结构为BWHC,故通过 transpose() 矩阵转置将通道数C移动到最后一个维度,即从BCWH(0,1,2,3)转置为BWHC(0,2,3,1).
images = images.transpose(0,2,3,1)
再定义函数 load_CIFAR_data( ) 来读取数据集。
def load_CIFAR_data(data_dir):
images_train = []
labels_train = []
for i in range(5):
f = os.path.join(data_dir,'data_batch_%d'%(i+1))
print('loading',f)
image_batch,label_batch=load_CIFAR_batch(f)
images_train.append(image_batch)
labels_train.append(label_batch)
Xtrain = np.concatenate(images_train)
Ytrain = np.concatenate(labels_train)
del image_batch,label_batch # 删除变量
Xtest,Ytest = load_CIFAR_batch(os.path.join(data_dir,'test_batch'))
print('finished loadding CIFAR-10 data')
return Xtrain,Ytrain,Xtest,Ytest
- 先定义两个空列表用于存放图片数据及标签数据。
images_train = []
labels_train = []
- 用一个for循环来读取5个批数据。其中,os.path.join() 为路径拼接函数,其效果如下图所示。
for i in range(5): f = os.path.join(data_dir,'data_batch_%d'%(i+1)) print('loading',f)

- 再通过调用 load_CIFAR_batch() 获得批量的图像及其对应的标签。
image_batch,label_batch=load_CIFAR_batch(f)
- 将已获得的图像及标签加入列表。
images_train.append(image_batch)
labels_train.append(label_batch)
- numpy提供了 numpy.concatenate((a1,a2,…), axis=0) 函数。能够一次完成多个数组的拼接。其中a1,a2,…是数组类型的参数。
Xtrain = np.concatenate(images_train)
Ytrain = np.concatenate(labels_train)
默认情况下,axis=0可以不写,对于一维数组拼接,axis的值不影响最后的结果。
- 用相同方法导入测试集数据,最后返回训练集的图像和标签,测试集的图像和标签。
Xtest,Ytest = load_CIFAR_batch(os.path.join(data_dir,‘test_batch’))
return Xtrain,Ytrain,Xtest,Ytest
3. 数据预处理
我们先对图像数据进行预处理。
Xtrain[0][0][0]
Xtrain_normalize = Xtrain.astype('float32')/255.0
Xtest_normalize = Xtest.astype('float32')/255.0
Xtrain_normalize[0][0][0]
图像的数字标准化可以提高模型的准确率。在没有进行标准化或归一化之前,图像的像素值是0-255,如果我们想对它进行归一的话,最简单的做法就是除以255。我们先查看归一化处理前的数据:
Xtrain[0][0][0]
运行结果为 array([59, 62, 63], dtype=uint8),由于图像是三通道的,所以59、62、63这三个数分别代表了图像的第一个像素点在RGB三个通道上的像素值。接下来对图像进行归一化处理:
Xtrain_normalize = Xtrain.astype(‘float32’)/255.0
Xtest_normalize = Xtest.astype(‘float32’)/255.0
Xtrain_normalize[0][0][0]
运行结果为 array([ 0.23137255, 0.24313726, 0.24705882], dtype=float32),经过处理后的数值全都在0-1之间,说明我们的数据已经预处理完毕了。
接下来对标签数据进行预处理。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse = False)
yy = [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]]
encoder.fit(yy)
Ytrain_reshape = Ytrain.reshape(-1,1)
Ytrain_onehot = encoder.transform(Ytrain_reshape)
Ytest_reshape = Ytest.reshape(-1,1)
Ytest_onehot = encoder.transform(Ytest_reshape)
对于CIFAR-10数据集,它的label是0-9。我们将其转换为独热编码来表示它的分类。
- 处理前标签数据信息:
Ytrain[:10]
打印结果为 array([6, 9, 9, 4, 1, 1, 2, 7, 8, 3])。独热编码即 One-Hot 编码,又称一位有效编码,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
yy = [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]]
encoder.fit(yy)
将0-9数据转换为独热编码,即在十个数据中只激活一位。 对训练集及测试集标签进行独热编码:
Ytrain_reshape = Ytrain.reshape(-1,1)
Ytrain_onehot = encoder.transform(Ytrain_reshape)
Ytest_reshape = Ytest.reshape(-1,1)
Ytest_onehot = encoder.transform(Ytest_reshape)
运行后数据如下所示:

由上图可知前五个数据原来的真实值为[6,9,9,4,1],经过独热编码转换之后变成了0或1的组合,只有对应下标为[6,9,9,4,1]的位置所对应的值为1,其他都为0。
接下来进行模型的建立
4. 定义网格结构
我们将要建立的卷积神经网络结构如下图所示:

在这个网络结构里,图像的特征提取是通过卷积层1、降采样层1、卷积层2以及降采样层2处理之后得到的。全连接神经网络是由全连接层、输出层所组成的网络结构。
我们先定义共享函数:
import tensorflow as tf
tf.reset_default_graph()
def weight(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.1),name = 'W')
def bias(shape):
return tf.Variable(tf.constant(0.1,shape = shape),name = 'b')
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding = 'SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize = [1,2,2,1],strides = [1,2,2,1],padding='SAME')
这个共享函数包括权值、偏置、二维卷积和池化函数。
tf.Variable(tf.truncated_normal(shape, stddev=0.1),name = 'W'):tf.truncated_normal(shape, mean, stddev)函数表示截断的产生正态分布的随机数,即随机数与均值的差值若大于两倍的标准差,则重新生成。其中shape表示生成张量的维度,mean表示均值,stddev表示标准差。tf.Variable(tf.constant(0.1,shape = shape),name = 'b'):tensorflow中创造常量的原型为tf.constant(value, dtype=None,shape=None,name=‘Const’,verify_shape=False),第一个值value是必须的,可以是一个数值,也可以是一个列表;后面四个参数可写可不写,第二个参数表示数据类型,一般可以是tf.float32, tf.float64等;第三个参数表示张量的形状,即维数以及每一维的大小。如果指定了第三个参数,当第一个参数value是数字时,张量的所有元素都会用该数字填充;第四个参数name可以是任何内容,是字符串就行;第五个参数verify_shape默认为False,如果修改为True的话表示检查value的形状与shape是否相符,如果不符会报错。tf.nn.conv2d(x,W,strides=[1,1,1,1],padding = 'SAME'):定义卷积操作。strides=[1, 1, 1, 1] 四个元素规定前后必须为1,中间两个数表示水平滑动和垂直滑动步长值,此处设置步长为1;padding='SAME’表示在扫描的时候,如果遇到卷积核比剩下的元素要大时,这个时候需要补0进行最后一次的行扫描或者列扫描,即用0来填充数据。tf.nn.max_pool(x,ksize = [1,2,2,1],strides = [1,2,2,1],padding='SAME'):定义池化操作。第一个参数value表示池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是BHWC[batch, height, width, channels]这样的形状;第二个参数ksize表示池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1;第三个参数strides和卷积操作类似,表示窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1];第四个参数padding也和卷积操作类似,可以取’VALID’ 或者’SAME’。该函数返回一个张量,类型不变,shape仍然是BHWC这种形式。
接下来定义网格函数:
with tf.name_scope('input_layer'):
x= tf.placeholder('float',shape=[None,32,32,3],name = "x")
with tf.name_scope('conv_1'):
W1 = weight([3,3,3,32])
b1 = bias([32])
conv_1 = conv2d(x,W1) + b1
conv_1 = tf.nn.relu(conv_1)
with tf.name_scope('pool_1'):
pool_1 = max_pool_2x2(conv_1)
with tf.name_scope('conv_2'):
W2 = weight([3,3,32,64])
b2 = bias([64])
conv_2 = conv2d(pool_1,W2) + b2
conv_2 = tf.nn.relu(conv_2)
with tf.name_scope('pool_2'):
pool_2 = max_pool_2x2(conv_2)
with tf.name_scope('fc'):
W3 = weight([4096,128])
b3 = bias([128])
flat = tf.reshape(pool_2,[-1,4096])
h = tf.nn.relu(tf.matmul(flat,W3) + b3)
h_dropout = tf.nn.dropout(h,keep_prob=0.8)
with tf.name_scope('output_layer'):
W4 = weight([128,10])
b4 = bias([10])
pred = tf.nn.softmax(tf.matmul(h_dropout,W4)+b4)
- 首先定义输入层:
with tf.name_scope(‘input_layer’):
x= tf.placeholder(‘float’,shape=[None,32,32,3],name = “x”)
输入层是32×32的图像,RGB三通道,所以这里的shape是None、32、32、3。None是指我们不限定一个批次里样本的数量。
关于占位符 的补充: tf.placeholder(dtype,shape=None,name=None),其中dtype为数据类型,常用的是tf.float32,tf.float64等数值类型;shape为数据形状,默认是None,就是一维值,也可以是多维(比如[2,3], [None, 3]表示列是3,行不定);name为名称。
- 定义第1个卷积层:
with tf.name_scope(‘conv_1’):
W1 = weight([3,3,3,32])
b1 = bias([32])
conv_1 = conv2d(x,W1) + b1
conv_1 = tf.nn.relu(conv_1)
第一个卷积层的输入通道为3、输出通道为32。这里的weight([3,3,3,32]),第一个3是卷积核的宽,第二个3是卷积核的高,第三个3是输入通道数量,32是输出通道数量。然后我们通过卷积核,对图像进行卷积之后,加上一个偏置,得到第一个卷积层的输出conv_1。我们对它进行一个非线性激活,这里采用的非线性激活函数是tf.nn.relu()。
- 定义第1个池化层:
with tf.name_scope(‘pool_1’):
pool_1 = max_pool_2x2(conv_1)
第一个池化层我们采用了最大池化。
第2个卷积层和第2个池化层与前两层的定义类似。
- 定义全连接层:
with tf.name_scope(‘fc’):
W3 = weight([4096,128])
b3 = bias([128])
flat = tf.reshape(pool_2,[-1,4096])
h = tf.nn.relu(tf.matmul(flat,W3) + b3)
h_dropout = tf.nn.dropout(h,keep_prob=0.8)
在两个卷积层和池化层之后,就是全连接层。我们先把64个8×8的图像转换为一维向量,这64个8×8的图像就是第二个池化层的输出,转换后一维向量的长度是64×8×8=4096。128指的是这个全连接层神经元的个数,也可以调整这个数字。“h = tf.nn.relu(tf.matmul(flat, W3) + b3)”这条语句将每一个神经元都和前面的4096个像素点进行全连接。然后加入了h_dropout来防止过拟合。
- 定义输出层:
with tf.name_scope(‘output_layer’):
W4 = weight([128,10])
b4 = bias([10])
pred = tf.nn.softmax(tf.matmul(h_dropout,W4)+b4)
最后是输出层,输出层共有10个神经元,对应到0-9这10个类别,用softmax函数输出。
5. 构建模型
with tf.name_scope("optimizer"):
# 定义占位符
y = tf.placeholder("float",shape=[None,10],name="label")
# 定义损失函数
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))
# 选择优化器
optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(loss_function)
with tf.name_scope("evaluation"):
correct_prediction = tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float")) # 类型转换
跟上一节相同的定义,选择合适的损失函数与优化器,再定义准确率。
6. 训练模型
接下来进行模型的训练。
import os
from time import time
train_epochs = 25
batch_size = 50
total_batch = int(len(Xtrain)/batch_size)
epoch_list=[];accuracy_list=[];loss_list=[];
epoch = tf.Variable(0,name='epoch',trainable=False)
startTime=time()
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
在启动会话之前,需要指定它迭代的次数、批量的样本大小等。定义了3个空列表分别存放迭代次数、准确率和损失率数据。
然后进行迭代训练:
def get_train_batch(number, batch_size):
return Xtrain_normalize[number*batch_size:(number + 1)*batch_size],Ytrain_onehot[number*batch_size:(number+1)*batch_size]
for ep in range(start,train_epochs):
for i in range(total_batch):
batch_x,batch_y = get_train_batch(i,batch_size)
sess.run(optimizer,feed_dict={x:batch_x,y:batch_y})
if i%100 == 0:
print("Step{}".format(i),"finished")
loss,acc = sess.run([loss_function,accuracy],feed_dict={x:batch_x,y:batch_y})
epoch_list.append(ep+1)
loss_list.append(loss)
accuracy_list.append(acc)
print("Train epoch:",'%02d'%(sess.run(epoch)+1),"Loss=","{:.6f}".format(loss),"Accuracy=",acc)
duration = time()-startTime
print("Train finished takes:",duration)
- 首先获得训练批数据:
def get_train_batch(number, batch_size):
return Xtrain_normalize[number*batch_size:(number + 1)batch_size],Ytrain_onehot[numberbatch_size:(number+1)*batch_size]
我们定义一个 get_train_batch() 函数来批量获取训练数据,它返回的是经过归一化的图像数据以及标签数据。
- 接下来是for循环。然后我们通过 sess.run() 来获取模型的损失值和准确率。
for ep in range(start,train_epochs):
for i in range(total_batch):
batch_x,batch_y = get_train_batch(i,batch_size)
sess.run(optimizer,feed_dict={x:batch_x,y:batch_y})
if i%100 == 0:
print(“Step{}”.format(i),“finished”)
先通过 get_train_batch() 函数来批量获得训练数据,再送入优化器去训练,最后打印训练完成。
- 再将训练得到的损失值和准确率加入之前定义的空列表中,最后打印出结果。
loss,acc = sess.run([loss_function,accuracy],feed_dict={x:batch_x,y:batch_y}) epoch_list.append(ep+1) loss_list.append(loss) accuracy_list.append(acc)
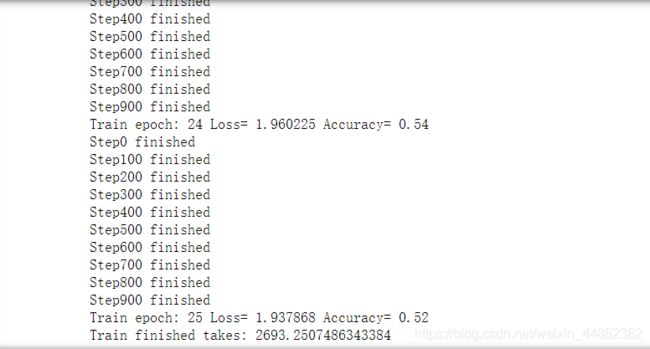
准确率可达到 52%。
到此已完成了模型的建立与训练,最后附上完整代码:
import urllib.request
import os
import tarfile
# 下载
url = 'https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'
filepath = 'xxx/data/cifar-10-python.tar.gz'
if not os.path.isfile(filepath):
result = urllib.request.urlretrieve(url,filepath)
print('downloaded:',result)
else:
print('Data file already exists.')
# 解压
if not os.path.exists("xxx/data/cifar-10-batches-py"):
tfile = tarfile.open("xxx/data/cifar-10-python.tar.gz",'r:gz')
result = tfile.extractall('xxx/data/')
print('Extracted to ./xxx/data/cifar-10-batches-py/')
else:
print('Directory already exists.')
import os
import numpy as np
import pickle as p
def load_CIFAR_batch(filename):
with open(filename,'rb') as f:
data_dict = p.load(f, encoding = 'bytes')
images = data_dict[b'data']
labels = data_dict[b'labels']
# 把原始数据结构调整为:BCWH
images = images.reshape(10000,3,32,32)
# tensorflow处理图像数据的结构:BWHC
# 把通道数据C移动到最后一个维度
images = images.transpose(0,2,3,1)
labels = np.array(labels)
return images,labels
def load_CIFAR_data(data_dir):
images_train = []
labels_train = []
for i in range(5):
f = os.path.join(data_dir,'data_batch_%d'%(i+1))
print('loading',f)
# 调用load_CIFAR_batch()获得批量的图像及其对应的标签
image_batch,label_batch=load_CIFAR_batch(f)
images_train.append(image_batch)
labels_train.append(label_batch)
Xtrain = np.concatenate(images_train)
Ytrain = np.concatenate(labels_train)
del image_batch,label_batch
Xtest,Ytest = load_CIFAR_batch(os.path.join(data_dir,'test_batch'))
print('finished loadding CIFAR-10 data')
# 返回训练集的图像和标签,测试集的图像和标签
return Xtrain,Ytrain,Xtest,Ytest
data_dir = 'C:/Users/GeantZ/Desktop/data/cifar-10-batches-py/'
Xtrain,Ytrain,Xtest,Ytest = load_CIFAR_data(data_dir)
# 查看图像数据信息 显示第一个图的第一个像素点
Xtrain[0][0][0]
#将图像进行数字标准化(归一化)
Xtrain_normalize = Xtrain.astype('float32')/255.0
Xtest_normalize = Xtest.astype('float32')/255.0
# 查看预处理后图像数据信息
Xtrain_normalize[0][0][0]
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse = False)
yy = [[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]]
encoder.fit(yy)
Ytrain_reshape = Ytrain.reshape(-1,1)
Ytrain_onehot = encoder.transform(Ytrain_reshape)
Ytest_reshape = Ytest.reshape(-1,1)
Ytest_onehot = encoder.transform(Ytest_reshape)
import tensorflow as tf
tf.reset_default_graph()
def weight(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.1),name = 'W')
def bias(shape):
return tf.Variable(tf.constant(0.1,shape = shape),name = 'b')
# 定义卷积操作
# 步长为1,padding为‘SAME’
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding = 'SAME')
# 定义池化操作
# 步长为2,即原尺寸的长和宽各除以2
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize = [1,2,2,1],strides = [1,2,2,1],padding='SAME')
# 输入层
# 32x32图像,通道为3(RGB)
with tf.name_scope('input_layer'):
x= tf.placeholder('float',shape=[None,32,32,3],name = "x")
# 第1个卷积层
# 输入通道:3,输出通道:32,卷积后图像尺寸不变,依然是32x32
with tf.name_scope('conv_1'):
W1 = weight([3,3,3,32]) #[k_width,k_height,input_chn,output_chn]
b1 = bias([32]) #与output_chn一致
conv_1 = conv2d(x,W1) + b1
conv_1 = tf.nn.relu(conv_1)
# 第1个池化层
# 将32x32图像缩小为16x16,池化不改变通道数量,因此依然是32个
with tf.name_scope('pool_1'):
pool_1 = max_pool_2x2(conv_1)
# 第2个卷积层
# 输入通道:32, 输出通道:64,卷积后图像尺寸不变,依然是16x16
with tf.name_scope('conv_2'):
W2 = weight([3,3,32,64])
b2 = bias([64])
conv_2 = conv2d(pool_1,W2) + b2
conv_2 = tf.nn.relu(conv_2)
# 第2个池化层
# 将16x16图像缩小为8x8,池化不改变通道数量,因此依然是64个
with tf.name_scope('pool_2'):
pool_2 = max_pool_2x2(conv_2)
# 全连接层
# 将第2个池化层的64个8x8的图像转换为一维的向量,长度是64*8*8=4096
# 128个神经元
with tf.name_scope('fc'):
W3 = weight([4096,128]) # 有128个神经元
b3 = bias([128])
flat = tf.reshape(pool_2,[-1,4096])
h = tf.nn.relu(tf.matmul(flat,W3) + b3)
h_dropout = tf.nn.dropout(h,keep_prob=0.8)
# 输出层
# 输出层共有10个神经元,对应到0-9这10个类别
with tf.name_scope('output_layer'):
W4 = weight([128,10])
b4 = bias([10])
pred = tf.nn.softmax(tf.matmul(h_dropout,W4)+b4)
with tf.name_scope("optimizer"):
# 定义占位符
y = tf.placeholder("float",shape=[None,10],name="label")
# 定义损失函数
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))
# 选择优化器
optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(loss_function)
import os
from time import time
train_epochs = 25
batch_size = 50
total_batch = int(len(Xtrain)/batch_size)
epoch_list=[];accuracy_list=[];loss_list=[];
epoch = tf.Variable(0,name='epoch',trainable=False)
startTime=time()
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
def get_train_batch(number, batch_size):
return Xtrain_normalize[number*batch_size:(number + 1)*batch_size],Ytrain_onehot[number*batch_size:(number+1)*batch_size]
for ep in range(start,train_epochs):
for i in range(total_batch):
batch_x,batch_y = get_train_batch(i,batch_size)
sess.run(optimizer,feed_dict={x:batch_x,y:batch_y})
if i%100 == 0:
print("Step{}".format(i),"finished")
loss,acc = sess.run([loss_function,accuracy],feed_dict={x:batch_x,y:batch_y})
epoch_list.append(ep+1)
loss_list.append(loss)
accuracy_list.append(acc)
print("Train epoch:",'%02d'%(sess.run(epoch)+1),"Loss=","{:.6f}".format(loss),"Accuracy=",acc)
#检查保存点
saver.save(sess,ckpt_dir+"CIFAR10_cnn_model.ckpt",global_step=ep+1)
sess.run(epoch.assign(ep+1))
duration = time()-startTime
print("Train finished takes:",duration)