吴恩达机器学习笔记总结
吴恩达机器学习笔记总结
作为机器学习经典入门课程,吴恩达的Machine Learning课程必定有它重要的一席之位。在19年我也在coursera(链接在此)上修习这门课程并领取了证书,前两个星期又去翻看了之前的笔记和黄海广博士翻译整理的笔记,重新根据自己的理解和关注的知识整理了一版简洁版笔记,方便以后快速回顾。

文章目录
- 吴恩达机器学习笔记总结
-
- 第一周
-
- 引言
- 单变量线性回归(Linear Regression with One Variable)
- 第2周
-
- 多变量线性回归
- 第3周
-
- 逻辑回归 Logistic Regression
- 正则化 Regularization
- 第4-5周
- 神经网络:表示 Neural Networks
- 神经网络的学习
- 第6周
-
- 应用机器学习的建议
- 机器学习系统设计
- 第7周
-
- 支持向量机
- 第8周
-
- 聚类Clustering
- 降维Dimensionally Reduction
- 第9周
-
- 异常检测-Anormaly Detection
- 推荐系统
- 第10周
-
- 大规模机器学习
- 应用实例:图片文字识别
第一周
引言
机器学习是什么:
卡内基梅隆大学Tom这么定义机器学习:一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,
当且仅当,有了经验E后,经过P评判,程序处理T时的性能有所提升。
机器学习 可分为监督学习和无监督学习:
监督学习:给学习算法一个包含“正确答案”的数据集,并根据给定标签学习数据中的模式
无监督学习:无监督学习中的数据集没有任何标签,希望从中找到某种结构
单变量线性回归(Linear Regression with One Variable)
-
模型表示
本次机器学习课程中相关符号定义:
m代表训练集中实例的数量
x代表特征/输入变量
y代表目标变量/输出变量
( x , y ) (x, y) (x,y)代表训练集中的实例
( x i , y i ) (x_i, y_i) (xi,yi)代表第 i i i个观察实例
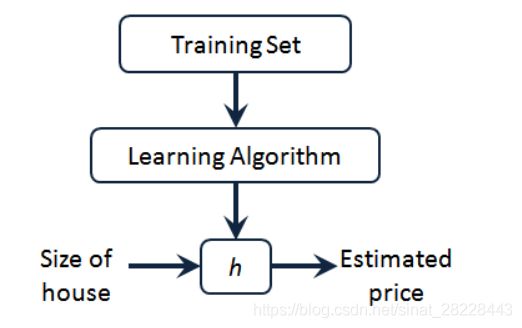
从训练集数据和标签数据,根据学习算法得到一个从 X X X到 Y Y Y的函数映射 h h h. -
代价函数/cost function
回归模型的代价函数如下,目标选择使得代价函数最小的模型参数:
J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta_0, \theta_1) = \frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2 J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))2
单变量线性回归模型表示: 模型假设/Hypothesis : h θ = θ 0 + θ 1 x h_{\theta}=\theta_0+\theta_1x hθ=θ0+θ1x
参数/Parameters: θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1
损失函数/Cost Function: J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta_0, \theta_1) = \frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2 J(θ0,θ1)=m1∑i=1m(hθ(x(i))−y(i))2
优化目标/Goal: m i n i m i z e θ 0 , θ 1 J ( θ 0 , θ 1 ) minimize_{\theta_0, \theta_1} J(\theta_0, \theta_1) minimizeθ0,θ1J(θ0,θ1)
参数选择过程:
随着迭代训练,损失函数变小,模型估计值悦来越逼近真实值:
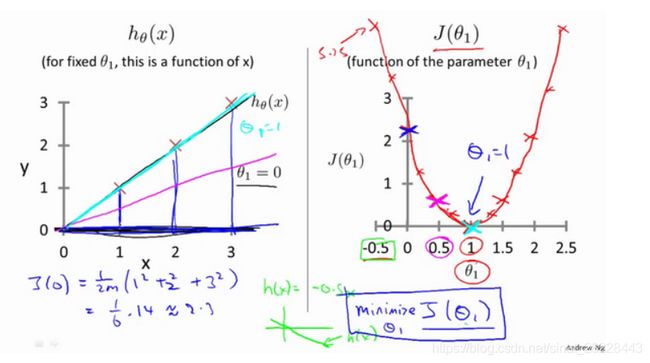
-
梯度下降/Gradient Descent
梯度下降是一个用来求函数最小值的算法,背后思想是,开始随机选择一个参数的组合 ( a 0 , a 1 , . . . , a n ) (a_0, a_1, ...,a_n) (a0,a1,...,an),计算代价函数,然后寻找下一个让代价函数值下降最多的参数组合,不断迭代,直到代价函数收敛或达到最大迭代数。
批量梯度下降算法的公式为:
repeat until convergence{
θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) f o r j = 0 a n d j = 1 \theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j}J(\theta_0, \theta_1)\ \ \ for\ j=0\ and j=1 θj:=θj−α∂θj∂J(θ0,θ1) for j=0 andj=1}, α \alpha α为学习率。梯度下家算法迭代过程:随着迭代次数增加,接近局部最低点时,偏导数越来越接近零,梯度下降移动幅度也越来越小。
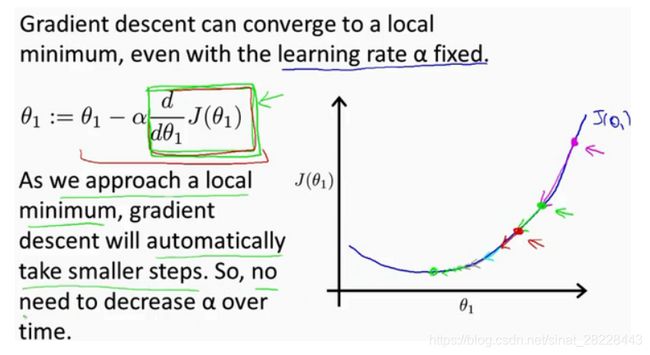
线性回归梯度下降:
结合梯度下降和线性回归模型:
repeat until convergence{
θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) ( f o r j = 1 a n d j = 0 ) \theta_j := \theta_j-\alpha\frac{\partial}{\partial \theta_j}J(\theta_0, \theta_1)\ \ (for \ j=1 \ and j=0) θj:=θj−α∂θj∂J(θ0,θ1) (for j=1 andj=0)}线性回归模型:
h θ = θ 0 + θ 1 x J ( θ ) = 1 2 m ∑ i = 1 m ( h θ x ( i ) ) − y ( i ) ) 2 ∂ ∂ θ j = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 j = 0 时 , ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) j = 1 时 : ∂ ∂ θ 1 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) ) h_{\theta}=\theta_0+\theta_1x \\ J(\theta)=\frac{1}{2m}\sum_{i=1}^m(h_\theta x^{(i)})-y^{(i)})^2\\ \frac{\partial}{\partial \theta_j}=\frac{\partial}{\partial \theta_j}\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2 \\ j=0时, \frac{\partial}{\partial \theta_0}J(\theta_0, \theta_1)=\frac{1}{2m}\sum_{i=1}^m (h_\theta(x_{(i)})-y_{(i)}) \\ j=1时: \frac{\partial}{\partial \theta_1}J(\theta_0,\theta_1)=\frac{1}{m}\sum_{i=1}^m ((h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}) hθ=θ0+θ1xJ(θ)=2m1i=1∑m(hθx(i))−y(i))2∂θj∂=∂θj∂2m1i=1∑m(hθ(x(i))−y(i))2j=0时,∂θ0∂J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))j=1时:∂θ1∂J(θ0,θ1)=m1i=1∑m((hθ(x(i))−y(i))x(i))
则有线性回归梯度下降:repeat{
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) ) \theta_0 := \theta_0 - \alpha\frac{1}{m}\sum_{i=1}{m}(h_{\theta}(x^{(i)})-y^{(i)}) \\ \theta_1 := \theta_1 - \alpha\frac{1}{m}\sum_{i=1}{m}((h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}) θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))θ1:=θ1−αm1i=1∑m((hθ(x(i))−y(i))x(i)) }
第2周
多变量线性回归
-
对于多变量特征:
多变量模型假设为 h ( x ) = a 0 + a 1 x 1 + a 2 x 2 + . . . + a n + x n h(x)=a_0+a_1x_1+a_2x_2+...+a_n+x_n h(x)=a0+a1x1+a2x2+...+an+xn
模型参数为 n + 1 n+1 n+1维的向量,特征矩阵 X X X的维度是 m × ( n + 1 ) m \times (n+1) m×(n+1) -
代价函数:
J ( θ 0 , θ 1 , . . . , θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta_0, \theta_1,...,\theta_n)=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y_{(i)})^2 J(θ0,θ1,...,θn)=2m1∑i=1m(hθ(x(i))−y(i))2
-
梯度下降公式:
repeat{
θ j : = θ j − α ∂ ∂ θ j ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \theta_j := \theta_j-\alpha\frac{\partial}{\partial \theta_j}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2 θj:=θj−α∂θj∂i=1∑m(hθ(x(i))−y(i))2}
梯度下降前可通过特征缩放,即将所有特征的尺度缩放到-1到1之间,加快收敛。
-
学习率选择:
可视化迭代次数与代价函数的图来判断算法在何时趋于收敛;
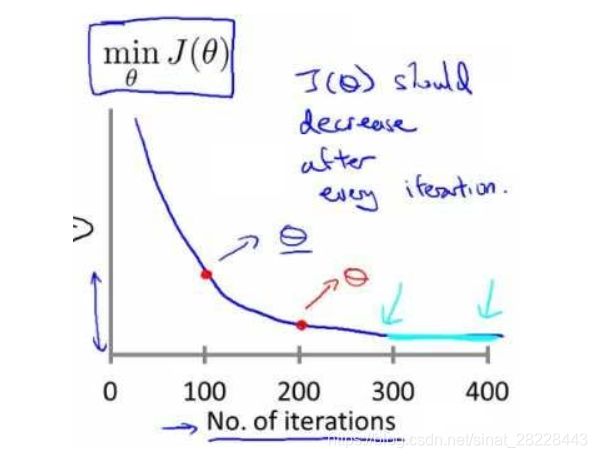
通常可考虑尝试学习率:0.01,0.03,0.1,0.3,1,3,10
-
特征和多项式回归:
线性回归并不适用于所有数据,可通过计算特征二次方、三次方等将模型转化为线性回归模型。 -
正规方程
正规方程通过求解偏导方程来找出使得代价函数最小的参数: ∂ ∂ θ j J ( θ j ) = 0 \frac{\partial}{\partial \theta_j}J(\theta_j)=0 ∂θj∂J(θj)=0
利用正规方程解出向模型参数,正规方程不需要迭代求解,一次性即可得出最优解,但特征数 n n n较大则运算代价很大。
θ = ( X T X ) − 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)−1XTy
第3周
逻辑回归 Logistic Regression
-
分类问题
预测的变量y是离散的值,根据标签数可分为二分类和多分类:
二分类:因变量属于两个类,1/0,即正类或负类
多分类:因变量有三个或以上类别,如动物分类,猫、狗、兔子等
-
逻辑回归假设
h θ ( x ) = g ( θ T X ) h_{\theta}(x) = g(\theta^TX) hθ(x)=g(θTX)
h h h为模型假设,X为特征向量,g为逻辑函数,也称sigmoid函数,是一个S形非线性映射函数,公式为: g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1,图像如下: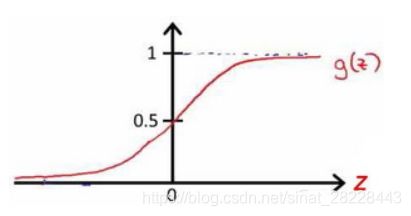
当 h θ > = 0.5 h_{\theta}>=0.5 hθ>=0.5时,预测 y = 1 y=1 y=1;当 h θ < 0.5 h_{\theta}<0.5 hθ<0.5时,预测 y = 0 y=0 y=0
-
判定边界
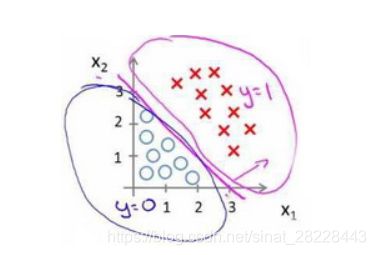
假设有模型 h ( x ) = g ( a 0 + a 1 x 1 + a 2 x 2 ) h(x)=g(a_0+a_1x_1+a_2x_2) h(x)=g(a0+a1x1+a2x2),
参数向量为[-3, 1, 1],则当 − 3 + x 1 + x 2 > = 0 时 -3+x_1+x_2>=0时 −3+x1+x2>=0时,预测 y = 1 y=1 y=1
决策边界为: − 3 + x 1 + x 2 = 0 -3+x_1+x_2=0 −3+x1+x2=0:
-
cost function
J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x ( i ) ) , y ( i ) ) C o s t ( h θ ( x ) , y ) = { − l o g ( h θ ( x ) ) i f y = 1 − l o g ( 1 − h θ ( x ) ) i f y = 0 J(\theta)=\frac{1}{m}\sum_{i=1}{m}Cost(h_{\theta}(x^{(i)}),y^{(i)}) \\ Cost(h_{\theta}(x),y) = \begin{cases} -log(h_{\theta}(x)) \ \ if \ y=1 \\ -log(1-h_{\theta}(x)) \ \ if \ y=0 \end{cases} J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))Cost(hθ(x),y)={−log(hθ(x)) if y=1−log(1−hθ(x)) if y=0
合并可得损失函数:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] J(\theta)=-\frac{1}{m}\sum_{i=1}{m}[y^{(i)}log(h_{\theta}(x^{(i)}))+(1-y^{(i)})log(1-h_{\theta}(x^{(i)}))] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
逻辑回归损失函数为交叉熵,评估真实分布与估计分布的差异程度。交叉熵常用在机器学习分类问题中的损失函数。 -
梯度下降
最小化损失函数: J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] J(\theta)=-\frac{1}{m}\sum_{i=1}{m}[y^{(i)}log(h_{\theta}(x^{(i)}))+(1-y^{(i)})log(1-h_{\theta}(x^{(i)}))] J(θ)=−m1∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
对损失函数求偏导: ∂ ∂ θ j = 1 m ∑ i = 1 m [ h θ ( x ( i ) ) − y ( i ) ] x j ( i ) \frac{\partial}{\partial \theta_j}=\frac{1}{m}\sum_{i=1}^{m}[h_{\theta}(x^{(i)})-y^{(i)}]x_j^{(i)} ∂θj∂=m1∑i=1m[hθ(x(i))−y(i)]xj(i)
repeat {
θ j : = θ j − α ∑ 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j := \theta_j-\alpha \sum_{1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)} θj:=θj−α1∑m(hθ(x(i))−y(i))xj(i) }
此时发现逻辑回归更新参数的规则看起来与线性回归基本相同,但是由于模型假设定义不同,实际上两个模型的梯度下降时两个不同的东西。
-
多分类
一对多:通过一对多的算法解决多类别分类问题,即重新标记类别标签,训练多个分类器,最终选择最高可能性的输出变量作为预测结果。
正则化 Regularization
-
过拟合 / over fitting
表现:在训练集数据上预测效果非常好,但在新数据预测效果上表现差
处理方法:1.删除部分冗余特征 2.正则化,减少参数的大小
-
欠拟合 / under fitting
在训练集和新数据上预测效果均一般
-
正则化代价函数
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 m θ j 2 ] J(\theta) = \frac{1}{2m}[\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2+\lambda \sum_{j=1}^{m}\theta_j^2] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑mθj2]
l a m b d a lambda lambda为正则化参数 -
正则化梯度下降
repeat until convergence{
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) θ j : = θ j − α 1 m [ ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ] = ( 1 − λ m ) θ j − α 1 m [ ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_0: =\theta_0-\alpha\frac{1}{m}\sum_{i=1}^{m}((h_{\theta}(x^{(i)})-y^{(i)})x_0^{(i)} \\ \theta_j: =\theta_j-\alpha\frac{1}{m}[\sum_{i=1}^{m}((h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)}+\frac{\lambda}{m}\theta_j] \\ = (1-\frac{\lambda}{m})\theta_j-\alpha\frac{1}{m}[\sum_{i=1}^{m}((h_{\theta}(x^{(i)})-y^{(i)})x_j^{(i)} \\ θ0:=θ0−αm1i=1∑m((hθ(x(i))−y(i))x0(i)θj:=θj−αm1[i=1∑m((hθ(x(i))−y(i))xj(i)+mλθj]=(1−mλ)θj−αm1[i=1∑m((hθ(x(i))−y(i))xj(i)}可以看出,正则化梯度下降算法实际是在原有算法更新规则的基础上令参数值减少了一个额外的值。
第4-5周
神经网络:表示 Neural Networks
-
大脑中的神经网络
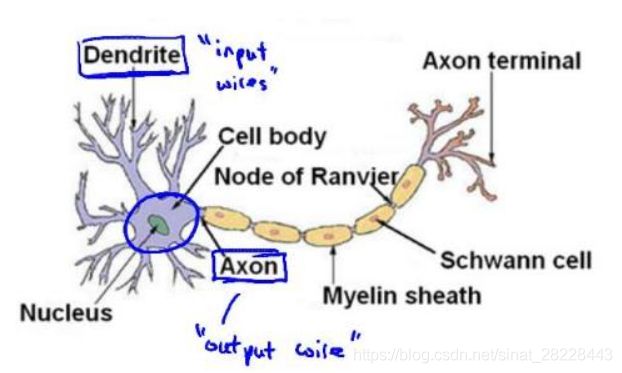
每个神经元都可以被认为是一个处理单元/神经核,含有许多输入/树突,并且有一个输出/轴突。神经网络是大量神经元相互链接并通过电脉冲来交流的网络。
-
单层神经网络模型

神经网络由输入层(input layer),隐藏层(hidden layer),输出层(output layer)组成
模型描述: a i ( j ) a_i^{(j)} ai(j)代表第 j j j层的第 i i i个激活单元。 θ ( j ) \theta^{(j)} θ(j)代表从第 j j j层映射到第 j + 1 j+1 j+1层时的权重的矩阵。
-
神经网络的直观理解
从本质上讲,神经网络可以通过学习原始特征得出一系列更复杂的特征,用于预测输出变量(与机器学习本质上的区别,机器学习最重要的是需要做大量的特征工程,而深度学习无需手工建造特征,通过神经网络学习隐藏特征)。
神经网络中,单层神经元的计算可用来表示逻辑运算
x 1 , x 2 ∈ { 0 , 1 } y = x 1 a n d x 2 x_1,x_2\in \{0, 1\} \\ y = x_1 and x_2 x1,x2∈{0,1}y=x1andx2

其中 θ 0 = − 30 , θ 1 = 20 , θ 2 = 20 \theta_0=-30,\theta_1=20,\theta_2=20 θ0=−30,θ1=20,θ2=20,输出函数即为 h θ = g ( − 30 + 20 x 1 + 20 x 2 ) h_{\theta}=g(-30+20x_1+20x_2) hθ=g(−30+20x1+20x2)


利用神经元组合更复杂的神经网络实现更复杂的运算,如XNOR功能:
X N O R = ( x 1 A N D x 2 ) O R ( ( N O R x 1 ) A N D ( N O T x 2 ) ) XNOR=(x_1 AND x_2) OR ((NOR x_1) AND (NOT x_2)) XNOR=(x1ANDx2)OR((NORx1)AND(NOTx2))
-
多分类表示
输出层使用多个神经元表示多类输出结果

神经网络的学习
-
代价函数
假设神经网络训练样本mn 个 , 每 个 包 含 一 组 输 入 个,每个包含一组输入 个,每个包含一组输入x 和 一 组 输 出 和一组输出 和一组输出y , , ,L 表 示 神 经 网 络 层 数 , 表示神经网络层数, 表示神经网络层数,S_l$表示每层的neuron个数。
J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 k y k ( i ) l o g ( h θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − ( h θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m\sum_{k=1}^k y_k^{(i)}log(h_{\theta}(x^{(i)}))_k+(1-y_k^{(i)})log(1-(h_{\theta}(x^{(i)}))_k)] + \frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}(\Theta_{ji}^{(l)})^2 J(Θ)=−m1[i=1∑mk=1∑kyk(i)log(hθ(x(i)))k+(1−yk(i))log(1−(hθ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2 -
反向传播算法
计算神经网络预测结果时采用正向传播方法,一层一层计算得到最终结果;但计算代价函数的偏导数,各层神经元的权重的偏导则利用反向传播方法,反向求出每层的误差。
正向传播:
Given one training example ( x , y ) (x, y) (x,y)
Forward propagation:
a ( 1 ) = x z ( 2 ) = Θ ( 1 ) a ( 1 ) a ( 2 ) = g ( z ( 2 ) ) ( a d d a 0 ( 2 ) ) z ( 3 ) = Θ ( 2 ) a ( 2 ) a ( 3 ) = g ( z ( 3 ) ) ( a d d a 0 ( 3 ) ) z ( 4 ) = Θ ( 3 ) a ( 3 ) a ( 4 ) = h Θ ( x ) = g ( z 4 ) a^{(1)}=x \\ z^{(2)}=\Theta^{(1)}a^{(1)} \\ a^{(2)} = g(z^{(2)}) \ (add \ a_0^{(2)}) \\ z^{(3)} = \Theta^{(2)}a^{(2)} \\ a^{(3)} = g(z^{(3)}) \ (add \ a_0^{(3)}) \\ z^{(4)} = \Theta^{(3)}a^{(3)} \\ a^(4) = h_{\Theta}(x) = g(z^{4}) a(1)=xz(2)=Θ(1)a(1)a(2)=g(z(2)) (add a0(2))z(3)=Θ(2)a(2)a(3)=g(z(3)) (add a0(3))z(4)=Θ(3)a(3)a(4)=hΘ(x)=g(z4)
反向传播计算误差: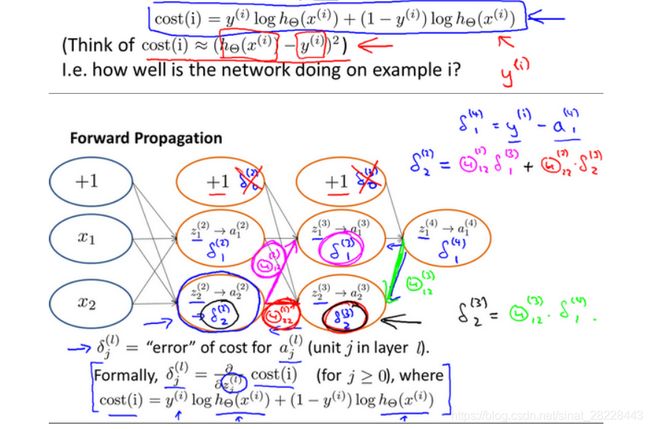
用 δ \delta δ来表示误差,则: δ ( 4 ) = a ( 4 ) − y \delta^{(4)}=a^{(4)}-y δ(4)=a(4)−y,利用这个误差值来计算前一层的误差:$\delta{(3)}=(\Theta{(3)})T\delta{(4)}*g’(z^{(3)}) $ ( δ j ( l ) = ∂ ∂ z j ( l ) = ∂ C ∂ y i ∂ y i ∂ z i ( l ) = ∂ C ∂ z ( l + 1 ) ∂ z ( l + 1 ) ∂ a j ( l ) ∂ a j ( l ) ∂ z j ( l ) ) (\delta_j^{(l)}=\frac {\partial}{\partial z_j^{(l)}}=\frac{\partial C}{\partial y_i}\frac{\partial y_i}{\partial z_i^{(l)}}=\frac{\partial C}{\partial z^{(l+1)}}\frac{\partial z^{(l+1)}}{\partial a_j^{(l)}}\frac{\partial a_j^{(l)}}{\partial z_j^{(l)}}) (δj(l)=∂zj(l)∂=∂yi∂C∂zi(l)∂yi=∂z(l+1)∂C∂aj(l)∂z(l+1)∂zj(l)∂aj(l))其中 g ′ ( z ( 3 ) ) g'(z^{(3)}) g′(z(3))是S形函数的导数, g ′ ( z ( 3 ) ) = a ( 3 ) ∗ ( 1 − a ( 3 ) ) g'(z^{(3)})=a^{(3)}*(1-a^{(3)}) g′(z(3))=a(3)∗(1−a(3)).而 ( θ ( 3 ) ) T δ ( 4 ) (\theta^{(3)})^T\delta^{(4)} (θ(3))Tδ(4)则是权重导致的误差的和。假设 λ = 0 \lambda=0 λ=0,即不做任何正则化处理时有, ∂ ∂ Θ i j ( l ) J ( Θ ) = ∂ C ∂ z j ( l ) ∂ z j ( l ) ∂ Θ i j ( l ) = a j ( l ) δ i ( l + 1 ) \frac{\partial }{\partial \Theta_{ij}^{(l)}}J(\Theta)=\frac{\partial C}{\partial z_j^{(l)}}\frac{\partial z_j^{(l)}}{\partial \Theta_{ij}^{(l)}}=a_j^{(l)}\delta_i^{(l+1)} ∂Θij(l)∂J(Θ)=∂zj(l)∂C∂Θij(l)∂zj(l)=aj(l)δi(l+1)
-
随机初始化
对于回归算法中参数都初始为0,对于这些算法都是可行的,但神经网络中如果零所有的初始参数都为0,会导致后面每层所有激活单元都会有相同的值(初始成相同的非0数也是一样)。
-
神经网络模型构建
- 构建按网络结构,网络层数、神经元数
- 参数随机初始化
- 利用正向传播方法计算所有的 a ( x ) a(x) a(x)
- 编写/定义损失函数
- 利用反向传播方法计算偏导
- 利用数值检验方法检验偏导
- 使用优化算法最小化损失函数
第6周
应用机器学习的建议
-
训练模型后的下一步
当运用训练好的模型预测未知数据的时候发现有较大的误差时:
1.获得更多的训练样本(代价较大,可考虑先采用下面的方法)
2.尝试减少特征的数量
3.尝试获得更多的特征
4.尝试增加多项式特征
5.尝试减少正则化程度lambda
6.尝试增加正则化程度lambda -
评估一个假设/模型
数据切分:70%训练集、30%测试集
利用训练集数据学习模型后,计算测试集损失
-
模型选择
利用验证集帮助选择模型:将数据随机切分60%训练集、20%验证集、20%测试集
模型选择步骤:
1.使用训练集训练出N个模型
2.用N个模型分别对验证集计算验证误差(损失函数的值)
3.选择损失函数最小的模型
4.用步骤3中选出的模型对测试集计算推广误差(泛化性) -
偏差和方差的诊断
对于训练集和验证集的损失函数误差与多项式次数表现,绘制图表

对于训练集,d较小时,模型拟合优度较低,误差较大;随着d增大,拟合程度提高,误差减小。对于验证集,d较小时,误差较大,随着d增大,误差呈现先减小后增大的趋势,转折点为模型最佳拟合点。
偏差与方差判断:训练集误差与验证集误差都比较大, 但两者误差相近时,为偏差/欠拟合;训练集误差远小于验证集误差时,方差/过拟合。
-
优化方法
1.获得更多的训练样本——解决高方差/过拟合
2.尝试减少特征的数量——解决高方差/过拟合
3.尝试获得更多的特征——解决高偏差/欠拟合
4.尝试增加多项式特征——解决高偏差/欠拟合
5.尝试减少正则化程度——解决高偏差/欠拟合
6.长hi增加正则化程度——解决高方差/过拟合
机器学习系统设计
-
构建算法的推荐方法
1.从一个简单的能快速实现的算法开始,实现该算法并用验证集数据测试这个算法
2.绘制学习曲线,判断模型状况,选择增加数据OR特征
3.进行误差分析:人工检验验证集中算法预测错误的样本,检查样本是否有某种系统化的趋势 -
样本不平衡的误差度量
混淆矩阵 预测值 Positive Negative 实际值 Positive TP FN Negative FP TN TP:实际为真,预测为真;
TN:预测为假,实际为假;
FP:预测为真,实际为假
FN:预测为假,实际为真查准率/precision: TP/(TP+FP)
查全率/recall: TP/(TP+FN)查准率与查全率平衡: F 1 = 2 ∗ P r e c i s i o n ∗ R e c a l l / ( P r e c i s i o n + R e c a l l ) F1 = 2*Precision*Recall/(Precision+Recall) F1=2∗Precision∗Recall/(Precision+Recall)
-
机器学习假设
选择具有很多参数的学习算法(复杂模型),特征包含足够的信息量,并且使用非常大的训练集,那么可以得到一个较低偏差,没有方差的模型。(数据和特征决定机器学习的上限,模型和算法只是逼近这个上限。)
第7周
支持向量机
-
支持向量机优化目标
支持向量机代价函数取与逻辑回归非常接近的直线:
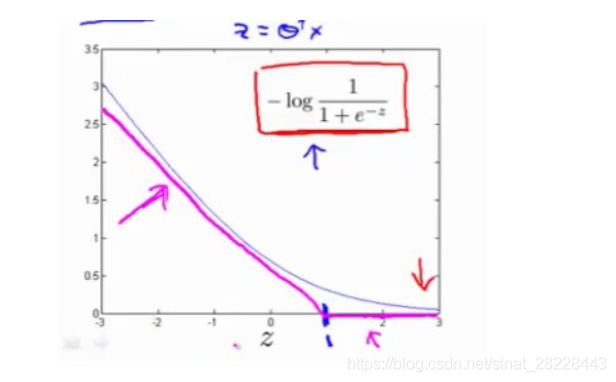
SVM hypothesis
m i n θ C ∑ i = 1 m [ y ( i ) c o s t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T x ( i ) ) ] + 1 2 ∑ i = 1 n θ j 2 min_\theta \ C\sum_{i=1}^m [y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)})cost_0(\theta^Tx^{(i)})] + \frac{1}{2}\sum_{i=1}^n\theta_j^2 minθ Ci=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21i=1∑nθj2
对于模型损失, A A A表示训练损失, B B B表示结构化风险(正则化项),逻辑回归模型优化目标结构为: A + λ B A+\lambda B A+λB,而支持向量机模型优化目标结构为 C ∗ A + B C*A+B C∗A+B。因此有 C = 1 / λ C=1/\lambda C=1/λ,支持向量机中的正则化参数与逻辑回归模型中正则化的参数程反比关系。 -
大边界/最大间隔优化

支持向量机中希望得到预测结果远远大于1或者远小于-1,在其中嵌入了额外的安全间距因子。

对于一个二分类问题,支持向量机希望从中找出这么一条决策边界,使得正样本和负样本到决策边界的间距最大(支持向量到决策边界的总距离,数据在这条边 w T x = 1 或 w T x = − 1 w^Tx=1或w^Tx=-1 wTx=1或wTx=−1上的样本点即是支持向量),因此支持向量机也被成为最大间距分类器。

若从样本点到超平面 w T x + b = 0 w^Tx+b=0 wTx+b=0的距离,支持向量到超平面的距离为 ∣ w T ∗ x + b ∣ ∣ ∣ w ∣ ∣ \frac {|w^T*x+b|}{||w||} ∣∣w∣∣∣wT∗x+b∣,即需要最大化这个距离 m a x 2 ∗ y ∗ ( w T x + b ) ∣ ∣ w ∣ ∣ max \ \frac{2*y*(w^Tx+b)}{||w||} max ∣∣w∣∣2∗y∗(wTx+b),又由于支持向量 y ( w T + b ) = 1 y(w^T+b)=1 y(wT+b)=1,因此得到 m a x 2 ∣ ∣ w ∣ ∣ max \ \frac{2}{||w||} max ∣∣w∣∣2.
当存在异常点时,可通过设置正则化参数C调整决策边界,从而达到忽略一些异常点的影响,得到泛化性能更好的分类器。
-
大边界的数学理解
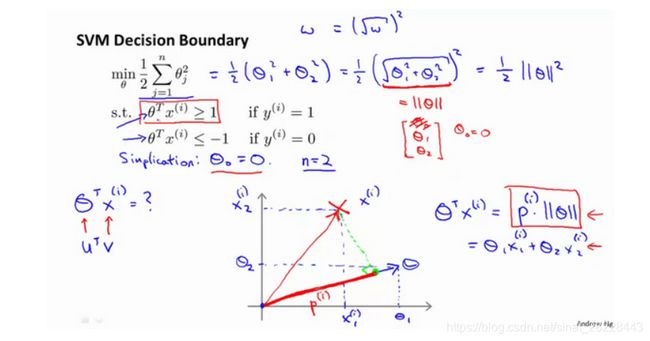
转变到支持向量机上,可得到优化目标如上,其中 p p p是 x x x投影到 θ \theta θ的长度。
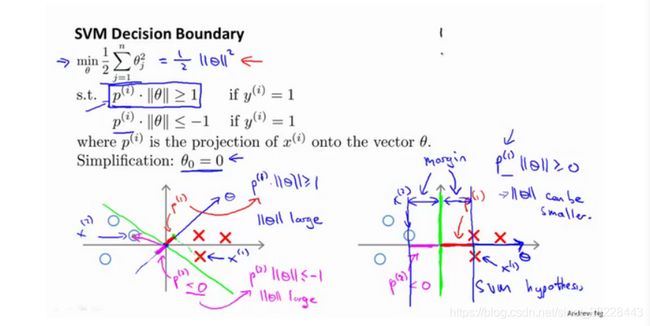
因此,可以将优化目标转化成上面的样子,约束条件 p ∗ ∣ ∣ θ ∣ ∣ > = 1 p*||\theta||>=1 p∗∣∣θ∣∣>=1,由于目标函数为最小化向量 θ \theta θ的范数,那么应该尽量选择 p p p较大的值,即数据投影到 θ \theta θ的长度最大(试图极大化这些 p ( i ) p(i) p(i)的范数),从而得到一个较小的 θ \theta θ范数。
-
核函数
非线性问题
对于非线性问题,可通过使用高级数的多项式模型来解决无法用直线进行分类的问题,即可令 f 1 = x 1 , f 2 = x 2 , . . . f 3 = x 1 ∗ x 2 , f 4 = x 1 2 . . . f_1=x_1,f_2=x_2,...f_3=x_1*x_2,f_4=x_1^2... f1=x1,f2=x2,...f3=x1∗x2,f4=x12...,从而假设 h ( x ) = w 1 f 1 + w 2 f 2 + . . . + w n f n h(x)=w_1f_1+w_2f_2+...+w_nf_n h(x)=w1f1+w2f2+...+wnfn.
但是这种方法会造成维数灾难,且计算开销大,那么此时可利用核函数来计算新的特征,达到降维的目的,并得到更高维的数据特征。
核函数使用
训练集的 m m m个样本,选取 m m m个地标,令 l ( 1 ) = x ( 1 ) , . . . l ( m ) = x ( m ) l(1)=x(1),...l(m)=x(m) l(1)=x(1),...l(m)=x(m)

通过核函数 s i m sim sim计算新特征 f f f,相应的损失函数可调整为 m i n θ C ∑ i = 1 m [ y ( i ) c o s t 1 ( θ T f ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T f ( i ) ) ] + 1 2 ∑ i = 1 n θ j 2 min_\theta \ C\sum_{i=1}^m [y^{(i)}cost_1(\theta^Tf^{(i)})+(1-y^{(i)})cost_0(\theta^Tf^{(i)})] + \frac{1}{2}\sum_{i=1}^n\theta_j^2 minθ C∑i=1m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21∑i=1nθj2,利用核函数可实现非线性可分的场景,背后的原理是通过核函数将原始的特征映射到高维空间上使得线性不可分的情况变得线性可分,从而在高维特征空间中寻找最优超平面。
最后还需对正则化项进行调整,在计算 ∑ j = 1 m θ j 2 = θ T θ \sum_{j=1}^m\theta_j^2=\theta^T\theta ∑j=1mθj2=θTθ时,用 θ T M θ \theta^TM\theta θTMθ代替 θ T θ \theta^T\theta θTθ, M M M为根据选择的核函数而不同的矩阵。
-
多种核函数
-
多项式核函数
-
高斯核函数
-
径向基核函数
-
字符串核函数
-
卡方核函数等
-
第8周
聚类Clustering
-
无监督学习
非监督学习中,通过将一系列无标签的训练数据,应用到模型算法中,寻找给定数据的内在结构。
聚类算法是一种典型的非监督学习模型,通过聚类算法将数据集中的样本点划分成不同簇,即将特征相似的样本聚类到同一个组中,从而达到数据分群的效果。
-
k-means算法
k-means算法是一个典型的聚类算法,算法目标是实现类内距离较小,类间距离较大的簇聚类。
算法步骤:
1.初始化K个随机点作为聚类中心(cluster centroids)
2.对于数据中的每个样本,计算其与K个中心点的距离,并将其与距离最近的中心点关联起来,划分成同一个簇
3.计算每一组的平均值,更新该组的中心点的位置到平均值的位置上
4.重复步骤2-3直至聚类中心点不再变化(迭代次数,或达到最小误差条件) -
k-means优化目标
k-means最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此k-means的代价函数为:
J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ k ) = 1 m ∑ i = 1 m ∣ ∣ X ( i ) − μ c ( i ) ∣ ∣ 2 J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k)=\frac{1}{m}\sum_{i=1}^m||X^{(i)}-\mu_{c^{(i)}}||^2 J(c(1),...,c(m),μ1,...,μk)=m1i=1∑m∣∣X(i)−μc(i)∣∣2
其中 μ c ( i ) \mu_{c^{(i)}} μc(i)代表与 x ( i ) x^{(i)} x(i)最近的聚类中心点。我们的优化目标就是找出使得代价函数最小的 c ( 1 ) , c ( 2 ) , . . . , c ( m ) c^{(1)},c^{(2)},...,c^{(m)} c(1),c(2),...,c(m)和 μ 1 , μ 2 , . . . , μ k : m i n c ( 1 ) , . . , c ( m ) , μ 1 , . . , μ k J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ k ) \mu_1,\mu_2,...,\mu_k: min_{c^{(1),..,c^{(m)}},\\ \mu_1,..,\mu_k} J(c^{(1),...,c^{(m)},\mu_1,...,\mu_k}) μ1,μ2,...,μk:minc(1),..,c(m),μ1,..,μkJ(c(1),...,c(m),μ1,...,μk) -
k-means随机初始化
应选择 K < m K
K<m K-means可能会得到局部最小值,因此可多次运行k-means算法,每次重新随机初始化,并比较多次模型的结果,选择损失函数最小的模型。(这种方法对于K较小时可行,当k较大时可能不会有明显的改善)
-
k-means选择聚类数
肘部法则:
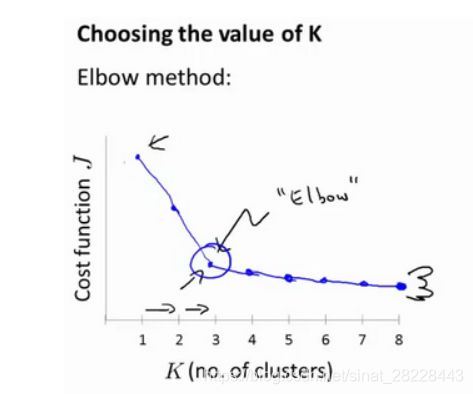
设置不同的K构建k-means模型,画出其评估指标(损失函数/轮廓系数等)与聚类数 K K K之间的关系,选择评估指标转折点对应的 K K K.
-
相似度/距离计算方法
(1)闵可夫斯基距离Minkowski(其中欧式距离:p=2)
d i s t ( X , Y ) = ( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 p dist(X,Y)=(\sum_{i=1}^n|x_i-y_i|^p)^{\frac {1}{p}} dist(X,Y)=(i=1∑n∣xi−yi∣p)p1
(2)杰卡德相似系数(Jaccard)
J ( A , B ) = ∣ A ⋂ B ∣ ∣ A ⋃ B ∣ J(A,B)=\frac{|A \bigcap B|}{|A \bigcup B|} J(A,B)=∣A⋃B∣∣A⋂B∣
(3)余弦相似度(cosine similarity) n n n维向量 x x x和 y y y的夹角记作 θ \theta θ,根据余弦定理,余弦值为:
c o s ( θ ) = x T y ∣ x ∣ ∣ y ∣ = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 ∑ i = 1 n y i 2 cos(\theta)=\frac{x^Ty}{|x||y|}=\frac{\sum_{i=1}^nx_iy_i}{\sqrt{\sum_{i=1}^nx_i^2}\sqrt{\sum_{i=1}^ny_i^2}} cos(θ)=∣x∣∣y∣xTy=∑i=1nxi2∑i=1nyi2∑i=1nxiyi
(4)Pearson皮尔逊相关系数
ρ X Y = c o v ( X , Y ) σ X σ Y = E [ ( X − μ X ) ( Y − μ Y ) ] σ X σ Y = ∑ i = 1 n ( x − μ X ) ( y − μ Y ) ∑ i = 1 n ( x − μ X ) 2 ∑ i = 1 n ( y − μ Y ) 2 \rho_{XY}=\frac{cov(X,Y)}{\sigma_X \sigma_Y}=\frac{E[(X-\mu_X)(Y-\mu_Y)]}{\sigma_X\sigma_Y}=\frac{\sum_{i=1}^n(x-\mu_X)(y-\mu_Y)}{\sqrt{\sum_{i=1}^n(x-\mu_X)^2}\sqrt{\sum_{i=1}^n(y-\mu_Y)^2}} ρXY=σXσYcov(X,Y)=σXσYE[(X−μX)(Y−μY)]=∑i=1n(x−μX)2∑i=1n(y−μY)2∑i=1n(x−μX)(y−μY)
Pearson相关系数即将 x , y x,y x,y坐标向量各自平移到原点后的夹角余弦。 -
聚类评估指标
(1)均一性: p p p
类似于精确率,一个簇中只包含一个类别的样本,则满足均一性。
(2)完整性: r r r
类似于召回率,同类别样本被归类到相同簇中,则满足完整性;每个聚簇中正确分类的样本数占该类别的总样本数比例的和
(3)V-measure
均一性和完整性的加权平均: V = ( 1 + β 2 ) ∗ p r β 2 ∗ p + r V=\frac{(1+\beta^2)*pr}{\beta^2*p+r} V=β2∗p+r(1+β2)∗pr
(4)轮廓系数
样本 i i i的轮廓系数: s ( i ) s(i) s(i)
簇内不相似度:计算样本 i 到 同 簇 其 它 样 本 的 平 均 距 离 为 i到同簇其它样本的平均距离为 i到同簇其它样本的平均距离为a(i)$,应尽可能小
簇间不相似度:计算样本 i i i到其它簇 C j C_j Cj的所有样本的平均距离 b i j b_{ij} bij,应尽可能大
轮廓系数: s ( i ) s(i) s(i)值越接近1表示样本 i i i聚类越合理,越接近-1,表示样本 i i i应该分类到另外的簇中,近似为0,表示样本 i i i应该在边界上;所有样本的 s ( i ) s(i) s(i)的均值被成为聚类结果的轮廓系统。
s ( i ) = b ( i ) − a ( i ) m a x { a ( i ) , b ( i ) } s(i)=\frac{b(i)-a(i)}{max{\{a(i),b(i)\}}} s(i)=max{a(i),b(i)}b(i)−a(i)
(5)ARI数据集 S S S共有 N N N个元素,两个聚类结果分别是:
X = { X 1 , X 2 , . . . , X r } , Y = { Y 1 , Y 2 , . . . , Y s } X=\{X_1,X_2,...,X_r\},Y=\{Y_1,Y_2,...,Y_s\} X={X1,X2,...,Xr},Y={Y1,Y2,...,Ys}
X X X和 Y Y Y的元素个数为:
a = { a 1 , a 2 , . . . , x r } , b = { b 1 , b 2 , . . . , b s } a=\{a_1,a_2,...,x_r\}, b=\{b_1,b_2,...,b_s\} a={a1,a2,...,xr},b={b1,b2,...,bs}
记: n i j = ∣ X i ⋂ Y i ∣ n_{ij} = |X_i \bigcap Y_i| nij=∣Xi⋂Yi∣
A R I = ∑ i , j C n i j 2 − [ ( ∑ i C a i 2 ) ( ∑ i C b i 2 ) ] / C n 2 1 2 [ ( ∑ i C a i 2 ) + ( ∑ i C b i 2 ) ] − [ ( ∑ i C a i 2 ) ( ∑ i C b i 2 ) ] / C n 2 ARI=\frac{\sum_{i,j}C_{n_{ij}}^2-[(\sum_{i}C_{a_i}^2)(\sum_iC_{b_i}^2)]/C_n^2}{\frac{1}{2}[(\sum_iC_{a_i}^2)+(\sum_iC_{b_i}^2)]-[(\sum_iC_{a_i}^2)(\sum_iC_{b_i}^2)]/C_n^2} ARI=21[(∑iCai2)+(∑iCbi2)]−[(∑iCai2)(∑iCbi2)]/Cn2∑i,jCnij2−[(∑iCai2)(∑iCbi2)]/Cn2
降维Dimensionally Reduction
机器学习中可通过降维将数据进行压缩,实现特征降维,过滤冗余特征,可以提高模型训练收敛速度,提高模型泛化性
-
主成分分析 Principal Component Analysis
目标分析:将n维数据降至k维,目标是找到向量 u 1 , u 2 , . . . , u k u_1,u_2,...,u_k u1,u2,...,uk使得总的投射平均均方误差最小。
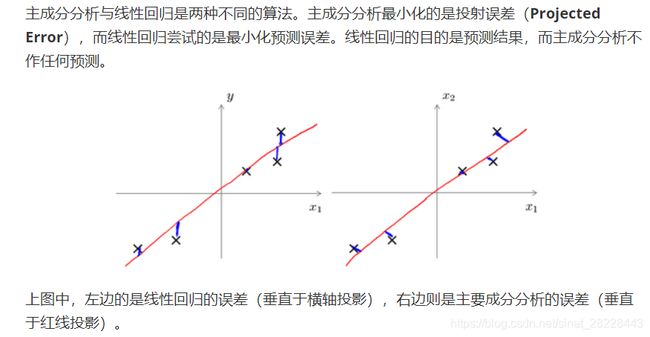
PCA算法:
1.均值归一化,计算所有特征的均值, x n e w = ( x − μ ) / σ 2 x_{new} = (x - \mu)/\sigma^2 xnew=(x−μ)/σ2
2.计算原始特征的协方差矩阵
3.利用奇异值分解方法计算协方差矩阵的特征向量U , S , V = s v d ( σ ) U,S,V=svd(\sigma) U,S,V=svd(σ)
从U中选取前k个向量,则新特征向量为: z ( i ) = U r e d u c e T ∗ x ( i ) z(i)=U_{reduce}^T*x(i) z(i)=UreduceT∗x(i)选择主成分数量:
主成分分析目标是减少投射的平均均方误差,训练集的方差为 1 / m ∗ s u m ( ∣ ∣ x ( i ) ∣ ∣ 2 1/m *sum(||x(i)||^2 1/m∗sum(∣∣x(i)∣∣2,希望在新特征的均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k k k值。
对于奇异值分解结果, U , S , V = s v d ( σ ) U,S,V=svd(\sigma) U,S,V=svd(σ),其中 S S S是 n x n nxn nxn方阵,且 S i , j = 0 S_{i,j}=0 Si,j=0当 i i i不等于 j j j,有均方误差与训练集方差的比例:
1 m ∑ i = 1 m ∣ ∣ x ( i ) − x a p p r o x ( i ) ∣ ∣ 2 1 m ∑ i = 1 m ∣ ∣ x ( i ) ∣ ∣ 2 = 1 − ∑ i = 1 k S i i ∑ i = 1 m S i i < = 1 % \frac{\frac{1}{m}\sum_{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2}{\frac{1}{m}\sum_{i=1}^m||x^{(i)}||^2}=1-\frac{\sum_{i=1}^kS_{ii}}{\sum_{i=1}^mS_{ii}}<=1\% m1∑i=1m∣∣x(i)∣∣2m1∑i=1m∣∣x(i)−xapprox(i)∣∣2=1−∑i=1mSii∑i=1kSii<=1%
在压缩过数据后,可以采用如下方法来近似地获得原有地特征: x a p p r o x ( i ) = U r e d u c e z ( i ) x_{approx}^{(i)}=U_{reduce}z^{(i)} xapprox(i)=Ureducez(i)
主成分解码:
利用PCA压缩数据后,可通过压缩表示重建原始数据的一种近似,如给定压缩后的100维数据 z z z,解码成原来的1000维数据 x a p p r o x x_{approx} xapprox
PCA算法中, z = U r e d u c e T ∗ x z=U_{reduce}^T*x z=UreduceT∗x,那么重建的原始数据的近似为: x a p p r o x = U r e d u c e ∗ z x_{approx}=U_{reduce}*z xapprox=Ureduce∗z
主成分分析应用建议:
常见错误主成分分析,将其用于减少过拟合,这么做不如采用正则化。由于主成分只是近似丢掉一些特征,并不考虑任何与结果变量有关的信息,可能会丢失非常重要的特征。
在算法运行太慢或者占用太多内存时,可考虑采用主成分分析
第9周
异常检测-Anormaly Detection
-
问题动机(目的)
(1)质量/异常问题
(2)欺诈检测
异常数据主要通过检测独立于一般情况数据的极少数特例数据进行识别 -
高斯分布/正态分布
通常如果我们认为变量 x x x符合高斯分布KaTeX parse error: Can't use function '\~' in math mode at position 3: x \̲~̲ N(\mu, \sigma^…,则其概率密度函数为 p ( x , μ , σ 2 ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) p(x, \mu, \sigma^2)=\frac{1}{\sqrt{2\pi }\sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2}) p(x,μ,σ2)=2πσ1exp(−2σ2(x−μ)2),可以利用已有地数据来预测总体中地 μ \mu μ和 σ 2 \sigma^2 σ2地计算方法如下:
μ = 1 m ∑ i = 1 m x ( i ) σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 \mu=\frac{1}{m}\sum_{i=1}^{m}x^{(i)}\\ \sigma^2 = \frac{1}{m}\sum_{i=1}^{m}(x^{(i)}-\mu)^2 μ=m1i=1∑mx(i)σ2=m1i=1∑m(x(i)−μ)2

高斯分布中参数 μ \mu μ决定数据中线位置, σ \sigma σ决定数据分布离散程度, σ \sigma σ值越大,曲线越矮宽, σ \sigma σ值越小,曲线越高细。
-
3 σ \sigma σ 原理异常检测
对给定的数据集,针对某个特征计算 u u u和 σ 2 \sigma^2 σ2的估计值:
μ j = 1 m ∑ i = 1 m x j ( ( i ) ) σ j 2 = 1 m ∑ i = 1 m ( x j ( i ) − μ j ) 2 \mu_j=\frac{1}{m}\sum_{i=1}^{m}x_j^{((i))}\\ \sigma_j^2 = \frac{1}{m}\sum_{i=1}^m(x_j^{(i)}-\mu_j)^2 μj=m1i=1∑mxj((i))σj2=m1i=1∑m(xj(i)−μj)2
根据公式获得平均值和方差的估计值,给定新的一个训练实例,根据模型计算 p ( x ) p(x) p(x): p ( x ) = ∏ j = 1 e x p ( x j ; μ j , σ j 2 ) = ∏ j = 1 1 1 2 π σ j e x p ( − ( x j − μ ) 2 2 σ j 2 ) p(x)=\prod_{j=1}^exp(x_j;\mu_j,\sigma_j^2)=\prod_{j=1}^1\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu)^2}{2\sigma_j^2}) p(x)=∏j=1exp(xj;μj,σj2)=∏j=112πσj1exp(−2σj2(xj−μ)2),当 p ( x ) < ϵ p(x)<\epsilon p(x)<ϵ时,为异常。3 σ 3\sigma 3σ原理即是取值在 ( μ − 3 σ , μ + 3 σ ) (\mu-3\sigma, \mu+3\sigma) (μ−3σ,μ+3σ)区间内的数据为正常数据,超过这个区间内的数据为异常数据.
-
开发和评价一个异常检系统
异常检测算法使用非监督学习方式实现,使用带标记(极少量异常)的数据开始,从中选择部分正常数据构建训练集,剩下数据分成验证集与测试集。
假设有1w条正常数据,20条异常数据:
(1)6k条正常数据作为训练集
(2)2k条正常数据和10条异常数据作为验证集
(3)2k条正常数据和10条异常数据作为测试集
检测系统如下:
(1)根据训练集数据,估计特征的平均值和方差并构建p(x)函数
(2)对验证集,尝试使用不同的e值作为阈值,预测数据是否异常,根据F1值或精确率、召回率来选择最佳e
(3)根据选择的e,对测试集预测,计算异常检测系统的F1值、精确率、召回率等。 -
异常检测VS监督学习
异常检测 监督学习 非常少量的正向类(异常数据 y = 1 y=1 y=1),大量的负向类( y = 0 y=0 y=0) 同时有大量的正向类和负向类 许多不同种类的异常,非常难。根据非常少量的正向类数据来训练算法。 有足够多的正向类实例,足够用于训练算法,未来遇到的正向类实例可能与训练集中的非常近似 未来遇到的异常可能与已掌握的异常、非常的不同 例如:欺诈行为检测 生产(例如飞机引擎) 检测数据中心的计算机运行状况 例如:邮件过滤器 天气预报 肿瘤分类 -
选择特征
利用高斯分布进行异常检测,假设特征符合高斯分布,当数据分布不是高斯分布时,可利用对数函数、求幂等将数据转换成高斯分布。
异常检测误差分析:当异常数据被错误预测为正常数据时,可分析数据样本,观察主要问题,增加有效新特征,捕捉不同的异常情况。
-
多元高斯分布
一般高斯分布模型中,通过分别计算每个特征对应的 p ( x ) p(x) p(x)然后将其累乘;多元高斯分布模型中,将构建特征的协方差矩阵,用所有的特征一起计算 p ( x ) p(x) p(x)
首先计算所有特征的平均值,然后再计算协方差矩阵:
p ( x ) = ∏ j = 1 n p ( x j ; μ , σ 2 ) = ∏ j = 1 n 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) μ = 1 m ∑ i = 1 m x ( i ) ∑ = 1 m ∑ i = 1 m ( x ( i ) − μ ) ( x ( i ) − μ ) T = 1 m ( X − μ ) T ( X − μ ) p(x)=\prod_{j=1}^np(x_j;\mu,\sigma^2)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2})\\ \mu=\frac{1}{m}\sum_{i=1}^mx^{(i)}\\ \sum = \frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)(x^{(i)}-\mu)^T=\frac{1}{m}(X-\mu)^T(X-\mu) p(x)=j=1∏np(xj;μ,σ2)=j=1∏n2πσj1exp(−2σj2(xj−μj)2)μ=m1i=1∑mx(i)∑=m1i=1∑m(x(i)−μ)(x(i)−μ)T=m1(X−μ)T(X−μ)
注:其中 μ \mu μ是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。最后计算多元高斯分布 p ( x ) : p ( x ) = 1 ( 2 π ) n 2 ∣ s u m ∣ 1 2 e x p ( − 1 2 ( x − μ ) T ∑ − 1 ( x − μ ) ) p(x): p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|sum|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^T\sum^{-1}(x-\mu)) p(x):p(x)=(2π)2n∣sum∣211exp(−21(x−μ)T∑−1(x−μ)) -
使用多元高斯分布进行异常检测

推荐系统
-
基于内容的推荐系统
假设预测用户给电影打分的场景,有5部电影和4个用户:

假设每部电影有两个特征,如 x 1 x1 x1代表电影的浪漫程度, x 2 x2 x2代表电影的动作程度
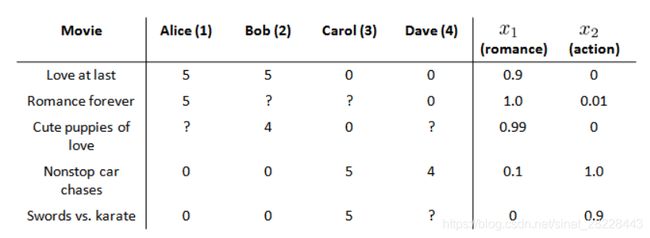
针对这个场景,可以构建线性回归模型,学习用户对电影的评分。代价函数为:
m i n θ ( 1 ) , . . . , θ ( n u ) 1 2 ∑ j = 1 n u ∑ i : r ( i , j ) = 1 ( ( θ ( i ) ) − y ( i , j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 min_{\theta^{(1)},...,\theta^{(n_u)}}\frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}((\theta^{(i)})-y{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(\theta_k^{(j)})^2 minθ(1),...,θ(nu)21j=1∑nui:r(i,j)=1∑((θ(i))−y(i,j))2+2λj=1∑nuk=1∑n(θk(j))2
利用梯度下降法来求解最优解,计算代价函数的偏导数后得到梯度下降的更新公式为:
θ k ( j ) : = θ k ( j ) − α ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T − y ( i , j ) ) x k ( i ) ( f o r k = 0 ) θ k ( j ) : = θ k ( j ) − α ( ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T − y ( i , j ) ) x k ( i ) + λ θ k ( i ) ) ( f o r k ≠ 0 ) \theta_k^{(j)}:=\theta_k^{(j)}-\alpha\sum_{i:r(i,j)=1}((\theta^{(j)})^T-y^{(i,j)})x_k^{(i)} \ \ (for \ k=0)\\ \theta_k^{(j)}:=\theta_k^{(j)}-\alpha(\sum_{i:r(i,j)=1}((\theta^{(j)})^T-y^{(i,j)})x_k^{(i)} + \lambda\theta_k^{(i)}) \ \ (for \ k \ne 0)\\ θk(j):=θk(j)−αi:r(i,j)=1∑((θ(j))T−y(i,j))xk(i) (for k=0)θk(j):=θk(j)−α(i:r(i,j)=1∑((θ(j))T−y(i,j))xk(i)+λθk(i)) (for k=0)
-
协同过滤
对于只有用户打分和电影数据,用户的参数和电影特征均未知,协同过滤可同时学习两者:
J ( x ( 1 ) , . . , x n m , θ ( 1 ) , . . . , θ ( n u ) ) = 1 2 ∑ ( i ; j ) : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k − 1 n ( x k ( j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 J(x^{(1)},..,x^{n_m},\theta^{(1)},...,\theta^{(n_u)})=\frac{1}{2}\sum_{(i;j):r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{i=1}^{n_m}\sum_{k-1}^n(x_k^{(j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(\theta_k^{(j)})^2 J(x(1),..,xnm,θ(1),...,θ(nu))=21(i;j):r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λi=1∑nmk−1∑n(xk(j))2+2λj=1∑nuk=1∑n(θk(j))2
对代价函数求偏导数的结果如下:
x k ( i ) : = x k ( i ) − α ( ∑ j : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) θ k j + λ x k ( i ) ) v θ k ( i ) = : θ k ( i ) − α ( ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T − y ( i , j ) ) x k ( i ) + λ θ k ( j ) ) x_k^{(i)}:=x_k^{(i)}-\alpha(\sum_{j:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i,j)})\theta_k^j+\lambda x_k^{(i)})v\\ \theta_k^{(i)}=:\theta_k^{(i)}-\alpha(\sum_{i:r(i,j)=1}((\theta^{(j)})^T-y^{(i,j)})x_k^{(i)}+\lambda \theta_k^{(j)}) xk(i):=xk(i)−α(j:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))θkj+λxk(i))vθk(i)=:θk(i)−α(i:r(i,j)=1∑((θ(j))T−y(i,j))xk(i)+λθk(j))
(1)基于item推荐:根据物品相似度推荐相似物品
(2)基于user推荐:根据相似用户群体推荐相关物品
-
目标变量评分结果处理
建模前可先对打分矩阵进行均值归一化处理,将每个用户对某部电影的评分减去该电影评分的均值
-
冷启动问题
对于用户冷启动问题,一般使用物品的平均打分作为初始打分
第10周
大规模机器学习
-
梯度下降
随机梯度下降算法根据shuffle后的数据,每次迭代更新参数只使用一个样本计算损失函数。
随机梯度下降算法迭代过程中损失函数可能会出现震荡着下降的情况(锯齿形状)。
-
小批量梯度下降-mini batch Gradient Descent
小批量梯度算法每次迭代使用部分训练样本进行计算
-
在线学习
根据初始训练模型,针对一个连续的数据流,定时对数据流进行训练学习,然后丢弃训练过的样本。在线学习机制可以针对用户的当前行为不断地更新模型以适应新用户群。