【强化学习论文解读 2】 Theory and application to reward shaping
【强化学习论文解读 2】 Theory and application to reward shaping
- 1. 引言
- 2. 论文解读
-
- 2.1 背景
- 2.2 预备知识
- 2.3 Reward shaping的充分必要条件
- 2.4 相关推论
- 3. 总结
1. 引言
本文介绍一篇1999年发表在ICML的文章:Policy invariance under reward transformations: Theory and application to reward shaping。论文的作者是大家非常熟悉的吴恩达(Andrew Ng)老师。
论文传送门:Policy invariance under reward transformations: Theory and application to reward shaping
论文的亮点是:给出了reward shaping(奖励塑造)的充分必要条件,即:对奖励做何种修改不会改变MDP(马尔科夫决策过程)的最优策略。
2. 论文解读
2.1 背景
在连续决策问题中,给定奖励函数和环境模型,那么最优策略是确定的。一个很自然的问题是:我们能够对奖励函数做怎样的修改能够保证最优策略是不变的呢? 因为一个好的奖励函数能够加快策略收敛速度,所以我们想知道我们能对它修改的“自由”是多少?
在utility theory领域(主要研究单步决策)中,有学者给出了对于utility function的相应问题的答案,那就是:对于没有不确定性的单步决策,utilities上的任何单调变换都使最优决策保持不变;对于有不确定性的单步决策,只有正线性变换才能保持最优决策不变。
在改变reward function的情况下,对于连续决策问题的策略不变性还没有人研究。
这个问题是非常重要的,因为在强化学习问题中,我们常常为了加快收敛速度会设置一些“引导性”的奖励,如果这些奖励设置地不好,很可能会导致最优策略发生改变。
2.2 预备知识
在证明之前,我们需要些预备知识。首先来看符号定义。
Markov decision process (MDP) 记作 M = ( S , A , T , γ , R ) M=(S, A, T, \gamma, R) M=(S,A,T,γ,R)
其中: S S S 是有限状态集; A = { a 1 , … , a k } A=\left\{a_{1}, \ldots, a_{k}\right\} A={a1,…,ak} 是动作集( k ≥ 2 k \geq 2 k≥2) ; T = { P s a ( ⋅ ) ∣ s ∈ S , a ∈ A } T=\left\{P_{s a}(\cdot) \mid s \in S, a \in A\right\} T={Psa(⋅)∣s∈S,a∈A} 是下一状态转移概率, P s a ( s ′ ) P_{s a}\left(s^{\prime}\right) Psa(s′)是在状态 s s s下采取动作 a a a得到状态 s ′ s^{\prime} s′的概率; γ ∈ ( 0 , 1 ] \gamma \in(0,1] γ∈(0,1]是折扣因子; R R R 代表奖励分布。
为了简化问题,作者将奖励 R R R都假定为确定性的,即为有界实值函数。将奖励函数 R R R写作: R ( s , a , s ′ ) R\left(s, a, s^{\prime}\right) R(s,a,s′),即:映射关系为 S × A × S ↦ R S \times A \times S \mapsto \mathbb{R} S×A×S↦R
在一个MDP问题 M M M下,执行策略 π \pi π得到的价值函数函数记为: V M π V_{M}^{\pi} VMπ. V M π ( s ) = E [ r 1 + V_{M}^{\pi}(s)=\mathrm{E}\left[r_{1}+\right. VMπ(s)=E[r1+ γ r 2 + γ 2 r 3 + … ; π , s ] \left.\gamma r_{2}+\gamma^{2} r_{3}+\ldots ; \pi, s\right] γr2+γ2r3+…;π,s], 代表其在状态 s s s下的价值。
Q函数(即动作价值函数)为:

对于MDP问题M而言,最优状态价值函数记作 V M ∗ ( s ) = sup π V M π ( s ) V_{M}^{*}(s)=\sup _{\pi} V_{M}^{\pi}(s) VM∗(s)=supπVMπ(s),最优动作价值函数记作 Q M ∗ ( s , a ) = sup π Q M π ( s , a ) . Q_{M}^{*}(s, a)=\sup _{\pi} Q_{M}^{\pi}(s, a) . QM∗(s,a)=supπQMπ(s,a). 最优策略为 π M ∗ ( s ) = arg max a ∈ A Q M ∗ ( s , a ) . \pi_{M}^{*}(s)=\arg \max _{a \in A} Q_{M}^{*}(s, a) . πM∗(s)=argmaxa∈AQM∗(s,a). 当然,最优策略可能不唯一,只要所有的动作 a a a满足 arg max a ∈ A Q M ∗ ( s , a ) \arg \max _{a \in A} Q_{M}^{*}(s, a) argmaxa∈AQM∗(s,a)就是最优策略。后续为了推导公式的简便,可能会直接扔掉下标“M”
2.3 Reward shaping的充分必要条件
假设原MDP问题为: M = ( S , A , T , γ , R ) M=(S, A, T, \gamma, R) M=(S,A,T,γ,R),reward shaping后的MDP问题为: M ′ = ( S , A , T , γ , R ′ ) M^{\prime}=\left(S, A, T, \gamma, R^{\prime}\right) M′=(S,A,T,γ,R′),其中 R ′ = R + F R^{\prime}=R+F R′=R+F, F F F和 R R R一样,是个有界实值函数,称为shaping reward function,映射关系为 F : S × A × S ↦ R F: S \times A \times S \mapsto \mathbb{R} F:S×A×S↦R(后面证明可以知道,其实 F F F只是个关于状态 s s s和状态 s ′ s' s′的函数)
F ( s , a , s ′ ) F\left(s, a, s^{\prime}\right) F(s,a,s′)是我们比较喜欢动手脚的地方,比如:如果为了鼓励agent接近一个目标,那么就设置当状态 s ′ s^{\prime} s′比状态 s s s更靠近目标时, F ( s , a , s ′ ) F\left(s, a, s^{\prime}\right) F(s,a,s′)为一个正数,反之则为一个负数;再比如:如果为了鼓励agent在某个状态 S 0 S_0 S0下采取动作 a 1 a_1 a1,那么只要令 F ( s , a , s ′ ) F\left(s, a, s^{\prime}\right) F(s,a,s′)在采取动作 a 1 a_1 a1时为一个正数,其他动作时为0即可。
首先,考虑一个环形状态转移情况,即: s 1 → s 2 → ⋯ → s n → s 1 → ⋯ s_{1} \rightarrow s_{2} \rightarrow \cdots \rightarrow s_{n} \rightarrow s_{1} \rightarrow \cdots s1→s2→⋯→sn→s1→⋯, 如果shaping reward F F F 产生了净收益 ( F ( s 1 , a 1 , s 2 ) + ⋯ + \left(F\left(s_{1}, a_{1}, s_{2}\right)+\cdots+\right. (F(s1,a1,s2)+⋯+ F ( s n − 1 , a n − 1 , s n ) + F ( s n , a n , s 1 ) > 0 ) \left.F\left(s_{n-1}, a_{n-1}, s_{n}\right)+F\left(s_{n}, a_{n}, s_{1}\right)>0\right) F(sn−1,an−1,sn)+F(sn,an,s1)>0),那么agent会被这个 F F F奖励“分心”,可能导致不断地“转圈刷分”。
基于这点观察,大致可以猜到 F F F应该要是个势能差的形式,即: F ( s , a , s ′ ) = Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=Φ(s′)−Φ(s),其中 Φ ( s ) \Phi(s) Φ(s)是状态 s s s的函数(即类似于物理学中的势能含义),这样才能避免“转圈刷分”的情况出现。当然 F ( s , a , s ′ ) = Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=Φ(s′)−Φ(s)只是针对折扣因子 γ = 1 \gamma=1 γ=1的情况;对于 γ < 1 \gamma<1 γ<1的情况, F ( s , a , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=γΦ(s′)−Φ(s),至于为什么是这个形式,就是通过理论推导得到的。
以下定理给出了shaping reward function F F F 在不改变最优策略情况下的充分必要条件(红框部分是定理的充分性和必要性的转述),其中 s 0 s_0 s0表示吸收态,也就是强化学习中的终态:

充分性说明了,如果在给奖励函数 R R R添加了一个基于势能的函数 F ( s , a , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=γΦ(s′)−Φ(s),那么最优策略保持不变;必要性说明了,如果在没有状态转移 T T T和奖励 R R R的先验知识,那么想要不改变最优策略,我们只能选择基于势能的函数 F F F。(如果我们有非常丰富的状态转移 T T T和奖励 R R R的先验知识,那么可以选择其它种类的shaping function,不一定要是基于势能的形式)
此定理重要的是: Φ ( s ) \Phi(s) Φ(s)可以作为人类专家知识的入口,只要 Φ ( s ) \Phi(s) Φ(s)选得好,那么能大幅加快强化学习的训练。
下面对充分性和必要性的证明做一个简单的论述,有一些细枝末节的地方没有展开,严谨论证请直接参考原论文。
充分性证明:
我们已知最优Q函数满足bellman方程:

通过简单的加减变换操作,得到:
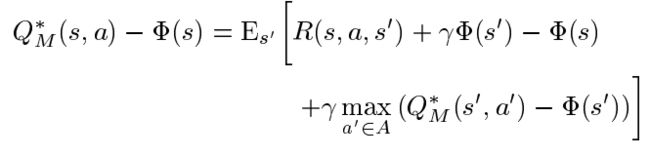
不妨定义:
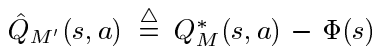
再把 F F F的定义式 F ( s , a , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=γΦ(s′)−Φ(s)代入变换后的方程,得到:

而此方程就是reward shaping后的MDP问题 M ′ M' M′的bellman方程。 M ′ M' M′的最优Q函数就是 Q M ′ ∗ ( s , a ) = Q ^ M ′ ( s , a ) = Q M ∗ ( s , a ) − Φ ( s ) Q_{M^{\prime}}^{*}(s, a)=\hat{Q}_{M^{\prime}}(s, a)=Q_{M}^{*}(s, a)-\Phi(s) QM′∗(s,a)=Q^M′(s,a)=QM∗(s,a)−Φ(s)
那么 M ′ M^{\prime} M′的最优策略 π M ′ ∗ ( s ) \pi_{M^{\prime}}^{*}(s) πM′∗(s)为:

可以看到,由于 Φ ( s ) \Phi(s) Φ(s)仅是状态 s s s的函数,与动作无关,故 M ′ M^{\prime} M′的最优策略与 M M M的最优策略完全一致,充分性证毕。
必要性证明:
首先看一个引理:如果说reward shaping函数 F ( s , a , s ′ ) F(s,a,s') F(s,a,s′)的值与动作有关,那么一定存在转移函数 T T T和奖励函数 R R R,使得在 M M M中的最优策略放在 M ′ M' M′中不是最优。(这里只要举一个例子即可)
证明过程如下:

接着下面进一步地证明 F ( s , a , s ′ ) F(s,a,s') F(s,a,s′)不仅与动作无关,而且 F ( s , a , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=γΦ(s′)−Φ(s)。如果 F ( s , a , s ′ ) F(s,a,s') F(s,a,s′)不是这样,那么最优策略就会改变。(这部分证明,我感觉按照作者的证明思路, F ( s , a , s ′ ) = k ( γ Φ ( s ′ ) − Φ ( s ) ) F\left(s, a, s^{\prime}\right)=k(\gamma\Phi\left(s^{\prime}\right)-\Phi(s)) F(s,a,s′)=k(γΦ(s′)−Φ(s))同样满足证明过程, k k k可以是任意实数,也许是作者想要强制保证 Φ ( s ) \Phi(s) Φ(s)前的系数为-1,这样把 k k k吸收到 Φ ( ⋅ ) \Phi(·) Φ(⋅)中,就得到了作者的式子)
证明的主要思路就是构造一个例子,即 F ( s , s ′ ) ≠ γ Φ ( s ′ ) − Φ ( s ) F\left(s, s^{\prime}\right) \neq \gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,s′)=γΦ(s′)−Φ(s)时,必会存在在 M M M中的最优策略放在 M ′ M' M′中不是最优。
证明过程如下:



2.4 相关推论
根据定理1的充分性证明过程,可得推论:

推论说的是,如果奖励塑造的过程中,使用的是 F ( s , a , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) F\left(s, a, s^{\prime}\right)=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,a,s′)=γΦ(s′)−Φ(s)的形式,去加在奖励函数上,那么是不会改变最优动作价值函数 Q M ′ ∗ ( s , a ) Q_{M^{\prime}}^{*}(s, a) QM′∗(s,a)和最优状态价值函数 V M ′ ∗ ( s ) V_{M^{\prime}}^{*}(s) VM′∗(s)。最优动作价值函数不改变是通过充分性的证明过程得到的,而最优状态价值函数不改变是因为有等式: V ∗ ( s ) = V^{*}(s)= V∗(s)= max a ∈ A Q ∗ ( s , a ) \max _{a \in A} Q^{*}(s, a) maxa∈AQ∗(s,a)。
对于此推论,作者做了两个备注。
备注一:鲁棒性。即:不仅仅是对最优策略,对任意策略 π \pi π,推论2中的恒等式都是成立的。如果一个策略 π \pi π,在 M ′ M' M′中接近最优了,那么此策略在 M M M中也会接近最优,这也就意味着基于势能的reward shaping还具备鲁棒性。
原文表述如下:

备注二:若奖励函数设为势能差,那么所有策略均最优。即:如果我们把奖励函数 R R R设为势能差的形式: R ( s , a , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) R\left(s, a, s^{\prime}\right)=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) R(s,a,s′)=γΦ(s′)−Φ(s),那么显然这个奖励函数没有任何实质性的对动作的偏向,这就会导致不管什么策略,算出来都会是最优策略。
原文表述如下:

作者还说道:对于半马尔可夫决策过程(动作需要不同的时间去执行),可以令 F ( s , a , s ′ , τ ) = F\left(s, a, s^{\prime}, \tau\right)= F(s,a,s′,τ)= e − β τ Φ ( s ′ ) − Φ ( s ) e^{-\beta \tau} \Phi\left(s^{\prime}\right)-\Phi(s) e−βτΦ(s′)−Φ(s),其中 τ \tau τ是动作完成的时间, β \beta β是折扣率。
3. 总结
对于我们没有状态转移 T T T和奖励 R R R的先验知识的情况(这是我们model-free方法经常遇到的情况),那么想要通过改变奖励函数 R ( s , a , s ′ ) R(s,a,s') R(s,a,s′)来加快强化学习收敛,只能令新的奖励函数为 R ′ ( s , a , s ′ ) = R ( s , a , s ′ ) + F ( s , s ′ ) R'(s,a,s')=R(s,a,s')+F(s,s') R′(s,a,s′)=R(s,a,s′)+F(s,s′),其中 F ( s , s ′ ) = γ Φ ( s ′ ) − Φ ( s ) F(s,s')=\gamma\Phi\left(s^{\prime}\right)-\Phi(s) F(s,s′)=γΦ(s′)−Φ(s),而 Φ ( s ) \Phi(s) Φ(s)是与状态有关的函数即可,这样才不会改变最优策略。
对于 Φ ( s ) \Phi(s) Φ(s)的构造,推荐使用基于距离的启发式(a distance-based heuristic),或者基于子目标的启发式(a subgoal-based heuristic)。
注:虽然原文写的是 F ( s , a , s ′ ) F(s,a,s') F(s,a,s′),但是写成 F ( s , s ′ ) F(s,s') F(s,s′)也是一样的,因为和动作 a a a无关。