Tensorflow复现DenseNet — cifar-10正确率91%
Tensorflow复现DenseNet
- 一. 网络特性
-
- 1.从根本解决问题
- 2.更少的参数
- 3.避免梯度消失
- 二.网络结构
- 三.完整代码:
- 四.训练结果
- 五.问题记录
-
- 1.参数配置
- 2.dropout的使用
偶然了解到一种据说比ResNet更优的网络,兴致勃勃学习一下,特此记录===
此次使用的仍为kaggle提供的cifar-10数据集:kaggle比赛链接
一. 网络特性
1.从根本解决问题
虽说ResNet和DenseNet是两种不同的网络,但是它们要解决的问题是相同的,即堆叠CNN层数模型非但未进步,反而发生退化。在ResNet的博客里提过退化的原因,即模型训练带来的正影响不能抵消错误信息累加带来的负影响。ResNet的解决思路是尽量避免不必要的训练,通过短路回溯的思想让正影响大于等于负影响。而DenseNet的解决思路是把每一层的输出都直连到了后面每一层的输入上,因此网络在训练的时候可以汲取前面训练的经验,训练效果更好也就是正影响增大。与Resnet相比,这种方法是在根本上解决了问题。打个比方来说,ResNet是在走弯路的时候及时改正,DenseNet是减小了走弯路的几率。
2.更少的参数
正常来说,我们把每一层的输出都直连到了后面每一层的输入上,网络按理应该更复杂,计算量,参数量都应该更大,但为什么会有更少的参数呢?这要归功于卷积层,首先我们要理解卷积层的作用,即提取特征。对于经典的多层卷积神经网络,卷积层负责特征提取,池化层负责特征选择,全连接层负责分类。而每一层卷积,都只负责提取自己要提取的特征,且只与自己前后两层之间有关系。换句话说,卷积层仅能利用上一层卷积提取的特征,而如果想利用其他提取过的特征,则需要重新卷积获取。因为一个通道就是对一个特征的检测,所以这造成了channel偏多,参数量也随之增多。而对于DenseNet,因为卷积层的输入包含了前面每一层的输出,所以它可以利用任意提取过的特征,需要进行卷积的次数减少,channel减少,参数量也就随之减少了。
3.避免梯度消失
对于解决这个问题,ResNet的办法是通过恒等映射传递梯度。而因为DenseNet把每一层的输出都直连到了后面每一层的输入上,所以梯度也可以通过直连直接传到靠前的层级。
二.网络结构
网络结构图(对于ImageNet)如下:
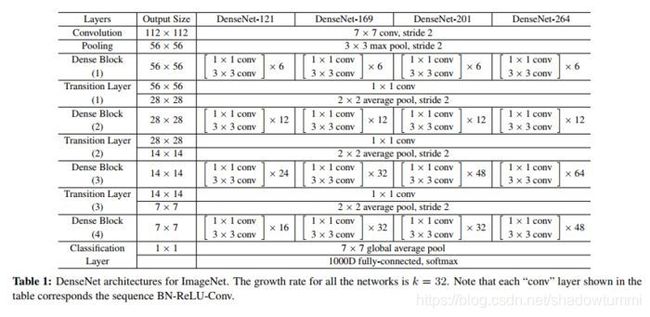
这个应该更好理解一些:
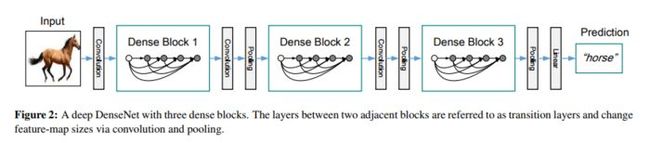
我们首先搭建Feature Block,也就是流入Dense Block之前的处理:
# Feature Block:输入层与第一个 Dense Block中间的部分
def featureBlock(self, inputs):
outputs = tf.layers.conv2d(inputs=inputs, filters=2*self.k, kernel_size=3, strides=1, padding='same',
activation=None, use_bias=False)
outputs = tf.nn.relu(tf.layers.batch_normalization(outputs, training=self.training))
# outputs = tf.layers.max_pooling2d(outputs, pool_size=3, strides=2, padding='same')
return outputs
之后是Dense Layer,也就是图中圆点:
# Dense Layer
def denseLayer(self, inputs):
outputs = tf.nn.relu(tf.layers.batch_normalization(inputs, training=self.training))
if self.bottleneck:
outputs = self.bottleneck_layer(outputs)
outputs = tf.layers.conv2d(inputs=outputs, filters=self.k, kernel_size=3, strides=1, padding='same',
activation=None, use_bias=False)
return outputs
为了减少 feature-maps的数量,DenseNet还提供了Bottleneck结构:
# Bottleneck:可选,减少 feature-maps的数量
def bottleneck_layer(self, inputs):
outputs = tf.layers.conv2d(inputs=inputs, filters=self.k*4, kernel_size=1, strides=1, padding='same',
activation=None, use_bias=False)
outputs = tf.nn.relu(tf.layers.batch_normalization(outputs, training=self.training))
return outputs
之后是Dense Block:
# Dense Block:由多层 Dense Layer组成
def denseBlock(self, inputs, num_residual):
# num_residual: 此Block有多少层layer
layer_inputs = inputs
for i in range(num_residual):
layer_outputs = self.denseLayer(layer_inputs)
layer_inputs = tf.concat([layer_inputs, layer_outputs], -1)
return layer_outputs
连接Dense Block的Transition:
# Transition:连接 Dense Block
def transition(self, inputs):
outputs = tf.nn.relu(tf.layers.batch_normalization(inputs, training=self.training))
outputs = tf.layers.conv2d(inputs=outputs, filters=int(outputs.shape[1])*self.compression, kernel_size=1, strides=1, padding='same',
activation=None, use_bias=False)
outputs = tf.layers.average_pooling2d(outputs, pool_size=2, strides=2, padding='same')
return outputs
将数据处理用于分类的Classification Block:
# Classification Block: 将三维数据打平用于分类
def classificationBlock(self, inputs):
outputs = tf.nn.relu(tf.layers.batch_normalization(inputs, training=self.training))
outputs = tf.layers.average_pooling2d(outputs, pool_size=outputs.shape[1:3], strides=1)
return outputs
三.完整代码:
DenseNet:
class DenseNet():
def __init__(self, k, bottleneck, training, compression):
self.k = k
self.bottleneck = bottleneck
self.training = training
self.compression = compression
# Feature Block:输入层与第一个 Dense Block中间的部分
def featureBlock(self, inputs):
outputs = tf.layers.conv2d(inputs=inputs, filters=self.k*2, kernel_size=3, strides=1, padding='same',
activation=None, use_bias=False)
outputs = tf.nn.relu(tf.layers.batch_normalization(outputs, training=self.training))
# outputs = tf.layers.max_pooling2d(outputs, pool_size=3, strides=2, padding='same')
return outputs
# Bottleneck:可选,减少 feature-maps的数量
def bottleneck_layer(self, inputs):
outputs = tf.layers.conv2d(inputs=inputs, filters=self.k*4, kernel_size=1, strides=1, padding='same',
activation=None, use_bias=False)
outputs = tf.nn.relu(tf.layers.batch_normalization(outputs, training=self.training))
return outputs
# Dense Layer
def denseLayer(self, inputs):
outputs = tf.nn.relu(tf.layers.batch_normalization(inputs, training=self.training))
if self.bottleneck:
outputs = self.bottleneck_layer(outputs)
outputs = tf.layers.conv2d(inputs=outputs, filters=self.k, kernel_size=3, strides=1, padding='same',
activation=None, use_bias=False)
return outputs
# Dense Block:由多层 Dense Layer组成
def denseBlock(self, inputs, num_residual):
# num_residual: 此Block有多少层layer
layer_inputs = inputs
for i in range(num_residual):
layer_outputs = self.denseLayer(layer_inputs)
layer_inputs = tf.concat([layer_inputs, layer_outputs], -1)
return layer_outputs
# Transition:连接 Dense Block
def transition(self, inputs):
outputs = tf.nn.relu(tf.layers.batch_normalization(inputs, training=self.training))
outputs = tf.layers.conv2d(inputs=outputs, filters=int(outputs.shape[1])*self.compression, kernel_size=1, strides=1, padding='same',
activation=None, use_bias=False)
outputs = tf.layers.average_pooling2d(outputs, pool_size=2, strides=2, padding='same')
return outputs
# ClassificationBlock: 将三维数据打平用于分类
def classificationBlock(self, inputs):
outputs = tf.nn.relu(tf.layers.batch_normalization(inputs, training=self.training))
outputs = tf.layers.average_pooling2d(outputs, pool_size=outputs.shape[1:3], strides=1)
return outputs
数据处理:
class Datamanage:
def image_manage(self, img_file, flag):
if flag == 'train':
img = Image.open('train/' + img_file)
img_size = img.resize((40, 40), Image.ANTIALIAS)
img_arr = np.array(img_size)
a = random.randint(0, 8)
b = random.randint(0, 8)
cropped = img_arr[a:a+32, b:b+32]
f = random.randint(0, 1)
if f == 1:
cropped = cv2.flip(cropped, 1)
img_result = cp.reshape(cropped, (1, -1))
else:
img = Image.open('train/' + img_file) # 这里的路径需要注意,训练和测试的时候是不一样的,
# 训练时测试集也是train文件夹里的,测试时改为test
img_size = img.resize((40, 40), Image.ANTIALIAS)
img_arr = np.array(img_size)
cropped = img_arr[4:36, 4:36]
img_result = cp.reshape(cropped, (1, -1))
return img_result
def read_and_convert(self, filelist, flag):
if flag == 'train':
data = self.image_manage(filelist[0], 'train')
for i in range(1, len(filelist)):
img = filelist[i]
data =np.concatenate((data, self.image_manage(img, 'train')), axis=0)
else:
data = self.image_manage(filelist[0], 'test')
for i in range(1, len(filelist)):
img = filelist[i]
data =np.concatenate((data, self.image_manage(img, 'test')), axis=0)
return data
def label_manage(self, csv_path, num_classes):
label = self.csv_read(csv_path)
total_y = np.zeros((len(label), num_classes))
for i in range(len(label)):
if label[i]=='airplane': total_y[i][0] = 1
elif label[i]=='automobile': total_y[i][1] = 1
elif label[i]=='bird': total_y[i][2] = 1
elif label[i]=='cat': total_y[i][3] = 1
elif label[i]=='deer': total_y[i][4] = 1
elif label[i]=='dog': total_y[i][5] = 1
elif label[i]=='frog': total_y[i][6] = 1
elif label[i]=='horse': total_y[i][7] = 1
elif label[i]=='ship': total_y[i][8] = 1
elif label[i]=='truck': total_y[i][9] = 1
return total_y
def csv_read(self, data_path):
label = []
with open(data_path, "r") as f:
reader = csv.reader(f)
for row in reader:
label.append(row[1])
new_label = np.reshape(label[1:], (-1, 1))
return new_label
def csv_write(self, data):
f = open('result.csv', 'w', encoding='utf-8', newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(["id", "label"])
for i in range(len(data)):
csv_writer.writerow([str(i+1), data[i]])
参数设置:
k = 32
input_size = 32*32*3
num_classes = 10
num_blocks = 4
compression = 1
num_residuals = [6, 12, 24, 16]
bottleneck = False
training_iterations = 30000 # 训练轮数
weight_decay = 2e-4 # 权重衰减系数
数据读取:
path = 'train/'
data = os.listdir(path)
data.sort(key=lambda x:int(x.split('.')[0]))
manage = Datamanage()
label = manage.label_manage('train.csv', num_classes)
x_train = data[:49000]; x_test = data[49000:]
y_train = label[:49000]; y_test = label[49000:]
y_test = [np.argmax(x) for x in y_test]
网络搭建:
X = tf.placeholder(tf.float32, shape = [None, input_size], name='x')
Y = tf.placeholder(tf.float32, shape = [None, num_classes], name='y')
training = tf.placeholder(tf.bool, name="training")
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
densenet = DenseNet(k, bottleneck, training, compression)
input_images = tf.reshape(X, [-1, 32, 32, 3])
input_images = tf.image.per_image_standardization(input_images) # 图片标准化处理`
block = densenet.featureBlock(input_images)
# 循环DenseBlock
block = densenet.denseBlock(block, num_residuals[0])
for i in range(num_blocks-1):
block = densenet.transition(block)
block = densenet.denseBlock(block, num_residuals[i+1])
block = densenet.classificationBlock(block)
block = tf.layers.dropout(inputs=block, rate=keep_prob)
final_opt = tf.layers.dense(inputs=block, units=10)
tf.add_to_collection('pred_network', final_opt)
global_step = tf.Variable(0, trainable=False) # 学习率衰减
'''
分段学习率
'''
boundaries = [5000, 10000, 15000, 20000, 25000]
values = [0.1, 0.05, 0.01, 0.005, 0.001, 0.0005]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, values)
'''
持续衰减
'''
# initial_learning_rate = 0.002 # 初始学习率
# learning_rate = tf.train.exponential_decay(learning_rate=initial_learning_rate, global_step=global_step, decay_steps=200, decay_rate=0.95)
'''
计算loss
'''
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=final_opt))
l2_loss = weight_decay * tf.add_n([tf.nn.l2_loss(tf.cast(v, tf.float32)) for v in tf.trainable_variables()])
tf.summary.scalar('l2_loss', l2_loss)
loss = loss + l2_loss
'''
定义优化器
'''
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
opt = optimizer.minimize(loss, global_step=global_step)
训练:
'''
初始化
'''
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
'''
训练
'''
for i in range(training_iterations):
start_step = i*64 % 49000
stop_step = start_step + 64
batch_x, batch_y = x_train[start_step:stop_step], y_train[start_step:stop_step]
batch_x = manage.read_and_convert(batch_x, 'train')
training_loss = sess.run([opt, loss, learning_rate], feed_dict={X:batch_x, Y:batch_y, training:True, keep_prob:0.2})
if i%10 == 0:
test_data = manage.read_and_convert(x_test[:1000], 'test')
result = sess.run(final_opt, feed_dict={X:test_data[:1000], training:False, keep_prob:1})
result = [np.argmax(x) for x in result]
print("step : %d, training loss = %g, accuracy_score = %g, learning_rate = %g" % (i, training_loss[1], metrics.accuracy_score(y_test[:1000], result), training_loss[2]))
if(metrics.accuracy_score(y_test[:1000], result) > 0.915):
break
saver.save(sess, './data/resnet.ckpt') # 模型保存
测试复用:
path = "test/"
manage = Datamanage()
filelist = os.listdir(path)
filelist.sort(key=lambda x:int(x.split('.')[0]))
saver = tf.train.import_meta_graph("./data/resnet.ckpt.meta")
results = []
with tf.Session() as sess:
saver.restore(sess, "./data/resnet.ckpt")
graph = tf.get_default_graph()
x = graph.get_operation_by_name("x").outputs[0]
y = tf.get_collection("pred_network")[0]
training = graph.get_operation_by_name("training").outputs[0]
keep_prob = graph.get_operation_by_name("keep_prob").outputs[0]
for i in range(len(filelist) // 100):
s = i*100; e = (i+1)*100
data = manage.read_and_convert(filelist[s:e], 'test')
result = sess.run(y, feed_dict={x:data, training:False, keep_prob:1})
result = [np.argmax(x) for x in result]
for re in result:
if re==0: results.append('airplane')
elif re==1: results.append('automobile')
elif re==2: results.append('bird')
elif re==3: results.append('cat')
elif re==4: results.append('deer')
elif re==5: results.append('dog')
elif re==6: results.append('frog')
elif re==7: results.append('horse')
elif re==8: results.append('ship')
elif re==9: results.append('truck')
print("num=====", i*100)
# print(results)
manage.csv_write(results)
print('done!!')
四.训练结果
训练结果如下:

提交至kaggle进行评测:

五.问题记录
1.参数配置
首先根据原文对cifar-10的配置进行训练,原文用三个Dense Block,且每个Block层数相同,说k=12时效果就会很好。但是我跑完正确率只有89%左右,尝试增大k值,但是显存不足跑不起来。于是我采用对ImageNet的配置,且不使用Dense Neck结构以及compression设为1,用最朴素的DenseNet进行测试,效果还不错。
2.dropout的使用
原文是在Dense Layer里面添加了dropout,最开始跑的时候,我并没有加这层,结果出现了过拟合,但是加上了之后情况并未改善。经查阅,dropout会对BN有所影响,二者不能达到1+1=2的效果,于是把dropout放在网络最后,全连接层之前,情况得以改善。
参考资料如下:
DenseNet:比ResNet更优的CNN模型
论文解读|【Densenet】密集连接的卷积网络(附Pytorch代码讲解)