重磅开源!Twins:更高效的视觉Transformer主干网,完美适配下游检测、分割任务...
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

Twins: Revisiting the Design of Spatial Attention in
Vision Transformers
单位:美团、阿德莱德大学
Arxiv: http://arxiv.org/abs/2104.13840
Github: https://github.com/Meituan-AutoML/Twins (分类、分割代码及模型均已开源)
值得注意的是,Twins 直接涵盖了 CPVT 的代码,相当于 Twins 和 CPVT 同时开源。
 Twins 代码 Github 截图
Twins 代码 Github 截图 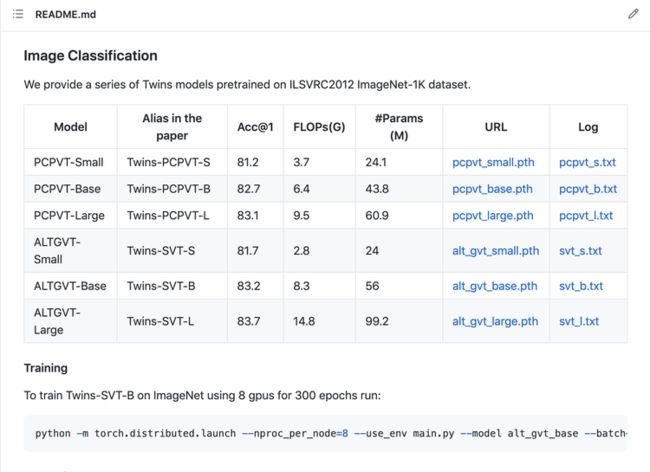 Twins 预训练模型
Twins 预训练模型
视觉注意力模型(Vision Transformer [1])已然是视觉领域的第一热点,近期工作如金字塔 Transformer 模型 PVT [2] ,Swin [3] 聚焦于将其应用于目标检测、分割等稠密任务。将 Vision Transformer 适配下游任务、高效地对计算模式进行重新设计成为当下研究的重点。
美团和阿德莱德大学合作的这篇文章 Twins 提出了两种新的 Transformer 架构,分别起名叫 Twins-PCPVT 和 Twins-SVT。
第一种架构 Twins-PCPVT 通过将 PVT 中的位置编码(和 DeiT一样的固定长度可学习位置编码)进行替换为该团队前不久在 CPVT [4] 中提出的条件位置编码 (Conditional Positional Encodings) ,可以在分类和下游任务上可以直接获得大幅的性能提升,尤其是在稠密任务上,由于条件位置编码 CPE 支持输入可变长度,使得视觉 Transformer 能够灵活处理来自不同空间尺度的特征。该架构说明 PVT 在仅仅通过 CPVT 的条件位置编码增强后就可以媲美或超越 Swin 的性能,这个发现证实 PVT 性能不及 Swin 的原因是使用了不适合的位置编码。可见能够灵活处理变化分辨率的位置编码如 CPE,对于下游任务的影响很大。
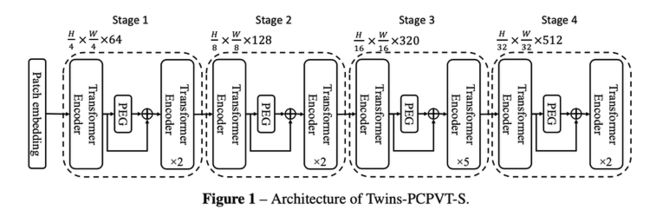 图 1: Twins-PCPVT-S 模型结构,使用了CPVT 提出的条件位置编码器(PEG)
图 1: Twins-PCPVT-S 模型结构,使用了CPVT 提出的条件位置编码器(PEG)
第二种架构 Twins-SVT (图2)基于对当前全局注意力的细致分析,对注意力策略进行了优化改进,新的策略融合了局部-全局注意力机制,作者将其类比于卷积神经网络中的深度可分离卷积 (depthwise separable convolution),并命名作空间可分离自注意力(Spatially Separable Self-Attention,SSSA)。与深度可分离卷积不同的是,Twins-SVT 提出的空间可分离自注意力( 图3) 是对特征的空间维度进行分组计算各组的自注意力,再从全局对分组注意力结果进行融合。
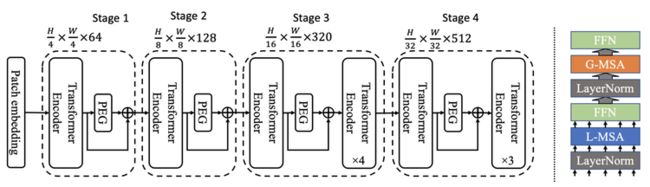 图 2: Twins-SVT-L 模型结构,右侧为两个相邻 Encoder 的结合方式
图 2: Twins-SVT-L 模型结构,右侧为两个相邻 Encoder 的结合方式
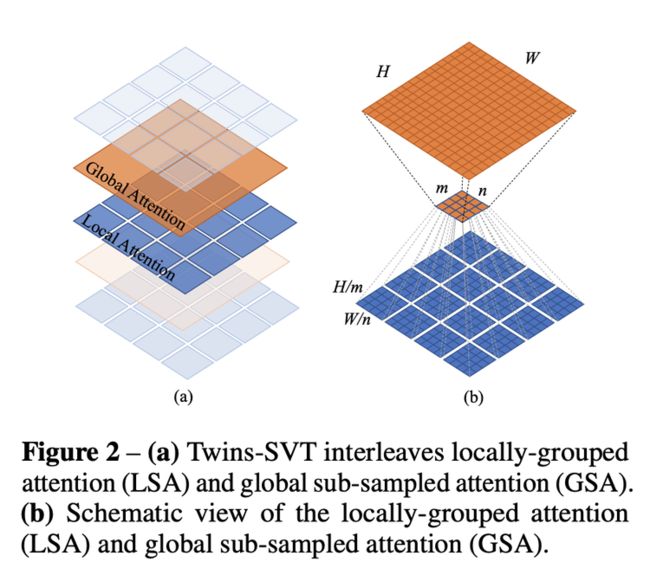 图3. Twins 提出的空间可分离自注意力机制 (SSSA)
图3. Twins 提出的空间可分离自注意力机制 (SSSA)
空间可分离自注意力使用局部-全局注意力交替(LSA-GSA)的机制,可以大幅降低计算成本,复杂度从输入的平方 O(H2W2d) 降为线性 O(mnHWd),通过将分组计算的注意力进行归纳并作为计算全局自注意力的键值,使得局部的注意力可以传导到全局。SVT 在实现上完全采用现有主流的深度学习框架实现,不需要额外的底层适配。具体的计算方式有公式(1)给定。
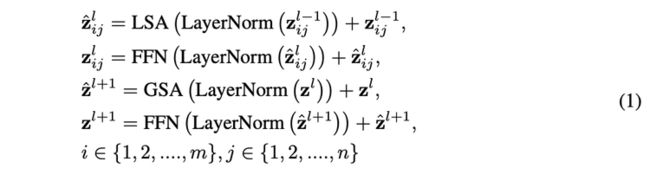
文中还给出了这种新型注意力(SSSA)的实现代码。
实验结果
ImageNet-1k 分类任务
Twins 的双胞胎模型 Twins-PCPVT 和 Twins-SVT 在分类任务上同等量级模型均取得 SOTA 结果,吞吐率也占优。
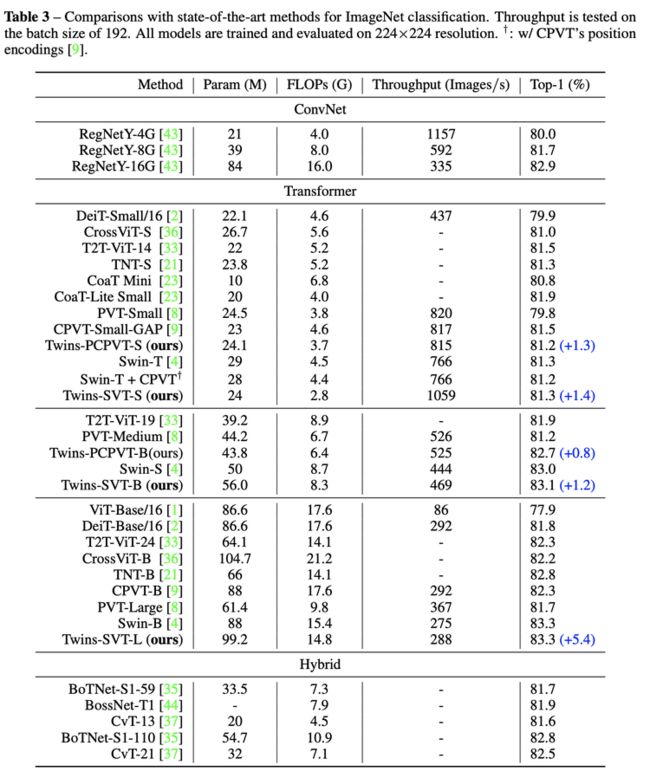
Twins 在下游任务中, 严格对齐了 PVT 的配置,对现有方法进行了公平对比,并在此基础上比肩 Swin。
ADE20K 分割
在语义分割任务上 ADE20K ,Twins 模型做主干网也达到了 SOTA 结果。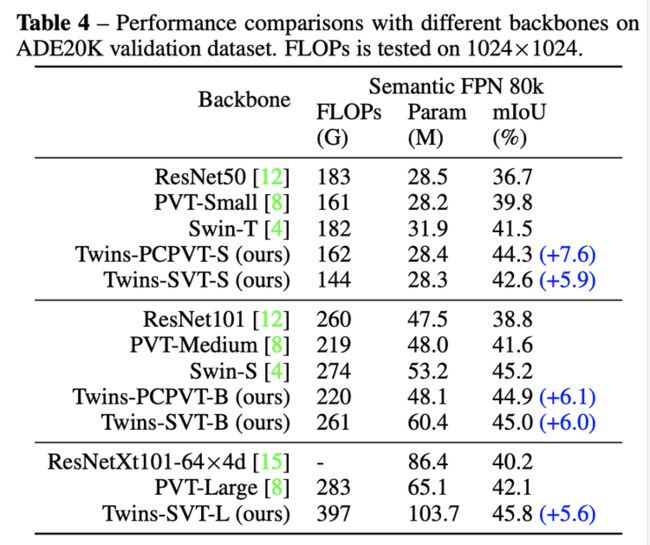
COCO 目标检测(Retina 框架)
在经典的 COCO 目标检测任务中,使用 Retina 框架,Twins 模型大幅超过了 PVT,且证明 PVT 在通过 CPVT 的编码方式增强之后,可以超过或媲美 Swin 同量级模型。
COCO 目标检测(Mask-RCNN 框架)
在 Mask-RCNN 框架下,Twins 模型在 COCO 上有较好的性能优势。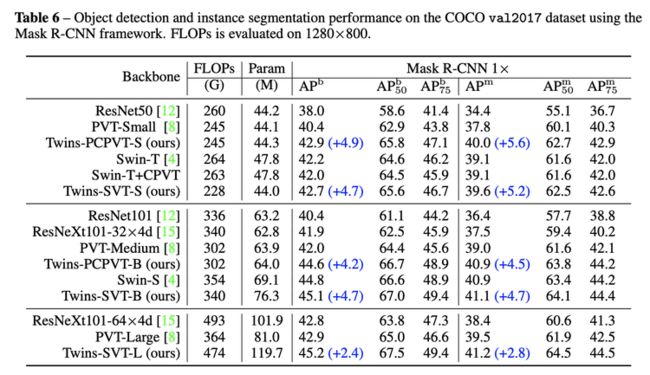
参考文献
An image is worth 16x16 words: Transformers for image recognition at scale https://openreview.net/pdf?id=YicbFdNTTy
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions https://arxiv.org/pdf/2102.12122.pdf
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows https://arxiv.org/pdf/2103.14030.pdf
Conditional Positional Encodings for Vision Transformers https://arxiv.org/abs/2102.10882
论文PDF和代码下载
后台回复:Twins,即可下载上述论文和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看