【深度神经网络】LeNet-PyTorch
搭建LeNet 并基于CIFAR10训练
-
- Result
- Model
- Train
- Predict
哪里学的?指路
小破站:深度学习-图像分类(霹雳吧啦Wz)
其他人整理的笔记CSDN:fun1024
大佬们都很牛
另外,这是学完之后的复盘笔记
首先安装pytorch,官网合适版本cmd命令安装.
配置pycharm的python环境与默认的要一致,不然包包不互通.
Pytorch Tensor的通道顺序:[batch,channel,height,width]
Result
 跑了两张dog和car都识别错的,找了张plane识别对了.
跑了两张dog和car都识别错的,找了张plane识别对了.
(图片是自己另外找的,随便找,放到文件里路径写得对都没事)
Model
# 使用torch.nn包来构建神经网络
import torch.nn as nn
import torch.nn.functional as F
# 继承于nn.Module这个父类
calss LeNet(nn.Module):
# 初始化网络结构
def__init__(self):
super(LeNet,self).__init__()
# 输入矩阵的深度,也就是输入图像RGB所以深度=3
# 输出矩阵的深度,也等于卷积核的个数
# 卷积核的尺寸5x5
self.conv1 = nn.Conv2d(3, 16, 5)
# 最大池化(卷积核尺寸,步距)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
# 全连接层
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 正向传播过程
# 激活函数ReLU
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
# output=(32-5+2*0)/1+1=28
x = self.pool1(x) # output(16, 14, 14),池化只改宽高不改变深度16
x = F.relu(self.conv2(x)) #output(32, 10, 10)
x = self.pool2(x) #output(32, 5, 5)
x = x.view(-1, 32*5*5) # view()展平三维张量成一维向量
# output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10),定义好的
return x
计算经卷积后输出尺寸
o u t p u t = W − F + 2 P S + 1 output=\frac{W-F+2P}{S}+1 output=SW−F+2P+1
其中,输入图片size=WxW
卷积核size=FxF
步距stride=S
padding像素数P
Train
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
# 数据预处理
# transforms.ToTensor()将numpy的ndarray或PIL.Image读的图片转换成形状为(C,H, W)的Tensor格式
# 且/255归一化到[0, 1.0]之间
transform = transform.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))])
# 导入加载训练数据集,50000张训练图片
# torchvision.datasets在线导入pytorch中的数据集
train_set = torchvision.datasets.CIFAR10(root='./data',tarin=True,download=True,transform=transform)
# 分批次去读入,硬件算力有限一次性读完吃不消
train_loader = torch.utils.data.DataLoader(train_set,batch_size=36,shuffle=True,num_workers=0) # windows就给0
# 导入加载验证集,10000张验证图片
val_set = torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform)
val_loader = torch.utils.data.DataLoader(val_set,batch_size=5000,shuffle=False,num_workers=0)
# 获取测试集里的图像和标签,用于精度计算
val_data_iter = iter(val_loader)
val_image,val_label = val_data_iter.next()
# CIFAR10的十种图像类
calsses = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
# 实例化
net = LeNet()
loss_function = nn.CrossEntropyLoss()
# adam优化器,学习率=0.001
# 超参都可以自己试验修改寻找最优,一般会靠一些经验设初值
optimizer = optim.Adam(net.parameters(),lr=0.001)
# epoch可以理解为轮数,训练重复几轮,一般来说可能越多精度越高
for epoch in range(5):
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
inputs, labels = data
# 清除历史梯度
optimizer.zero_grad()
outputs = net(inputs)
loss = loss_function(outputs, lables)
loss.backward()
optimizer.step()
#打印
running_loss +=loss.item()
if step % 500 ==499:
# 冻结参数
# 在以下步骤汇总不用计算每个节点的损失梯度以防占用内存
with torch.no_grad():
outputs = net(val_image)
# 以output中值最大位置对应的标签作为预测输出
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
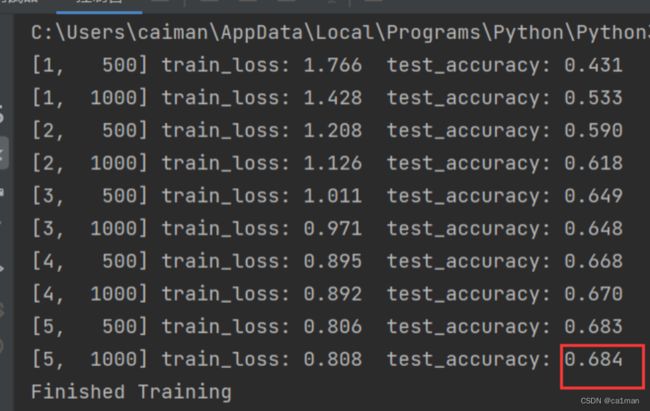
print('[%d,%5d] train_loss:%3f test_accuracy:%.3f'%(epoch+1,step+1,running_loss / 500,accuracy))
running_loss = 0.0
print('Finshed Training')
# 保存训练得到的参数
save_path = './Lenet.pth'
torch.save(net.state_dict(),save_path)
if __name__ == '__main__':
main()
Predict
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet # model.py
def main():
# 数据预处理
transform = transforms.Compose(
[transforms.Resize((32, 32)), # 剪裁跟训练图像那个一样的大小
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
# 加载训练好的模型参数
net.load_state_dict(torch.load('Lenet.pth'))
#要测试的图像,放在源文件目录下
im = Image.open('3.jpg')
im = transform(im) # [C, H, W]
# 扩充维度,张量的参数最开始就提到过了
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
# 最大值预测输出
predict = torch.max(outputs, dim=1)[1].numpy()
print(classes[int(predict)])
#每个相似度输出,预测结果输出10个概率
# predict = torch.softmax(outputs, dim=1)
# print(predict)
# 运不运行注意这里的注释去掉没有
if __name__ == '__main__':
main()
三个部分均保存为.py文件一个文件夹下运行即可