如何用ARIMA模型做预测?
1、作用
ARIMA模型的全称叫做自回归移动平均模型,是统计模型中最常见的一种用来进行时间序列预测的模型。
2、输入输出描述
输入:特征序列为1个时间序列数据定量变量
输出:未来N天的预测值
3、学习网站
SPSSPRO-免费专业的在线数据分析平台
4、案例示例
案例:基于1985-2021年某杂志的销售量,预测某商品的未来五年的销售量。
5、案例数据
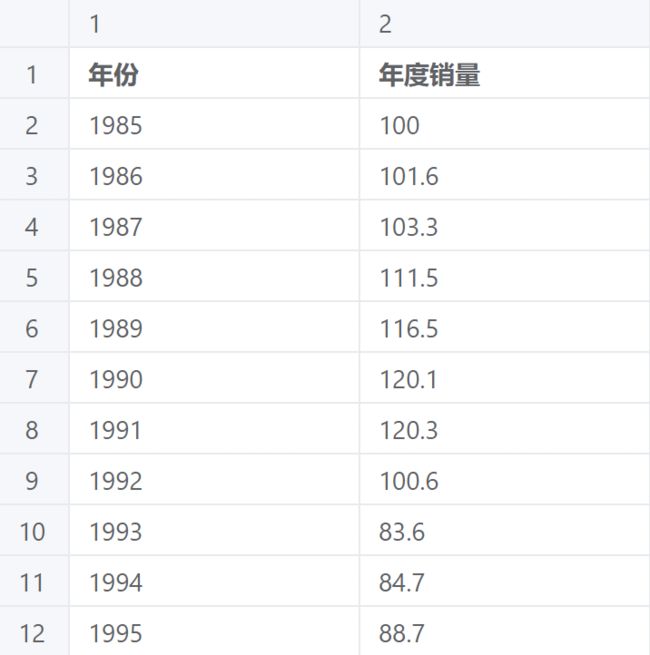
ARIMA案例数据
6、案例操作
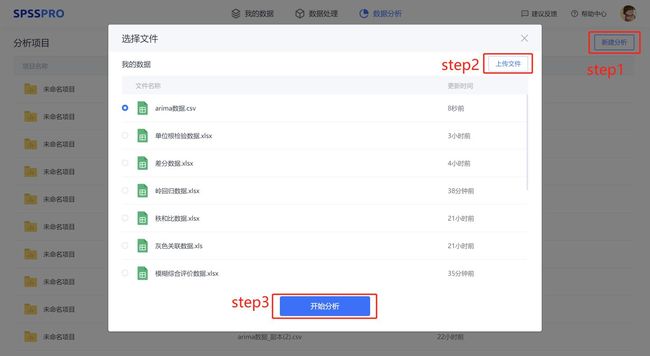
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
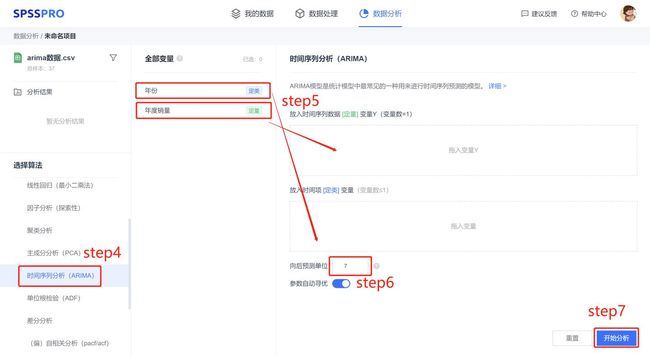
step4:选择【时间序列分析(ARIMA)】;
step5:查看对应的数据数据格式,【时间序列分析(ARIMA)】要求输入1个时间序列数据定量变量。
step6:选择向后预测的期数。
step7:点击【开始分析】,完成全部操作。
7、输出结果分析
输出结果1:ADF检验表

*p<0.05,**p<0.01,***p<0.001
智能分析:该序列检验的结果显示,基于字段年度销量:
在差分为0阶时,显著性P值为0.998,水平上不要呈现显著性,不能拒绝原假设,该序列为不平稳的时间序列。 在差分为1阶时,显著性P值为0.023*,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
在差分为2阶时,显著性P值为0.000***,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
(注意:在理论上,足够多的差分运算可以充分提取原时间序列中的非平稳确定性信息。但进行差分运算需要注意的是,差分运算的阶数不是越多越好。差分是对信息的提取、加工的过程,每次差分都会有信息的损失,所以差分的阶数需要适当,以免过度差分。)
输出结果2:最佳差分序列图

图表说明:由于一阶差分后序列进行单位根检验的P值小于0.05,说明一阶差分后序列是平稳数据,上图展示了原始数据1阶差分后的时序图。
输出结果3:最终差分数据自相关图(ACF)
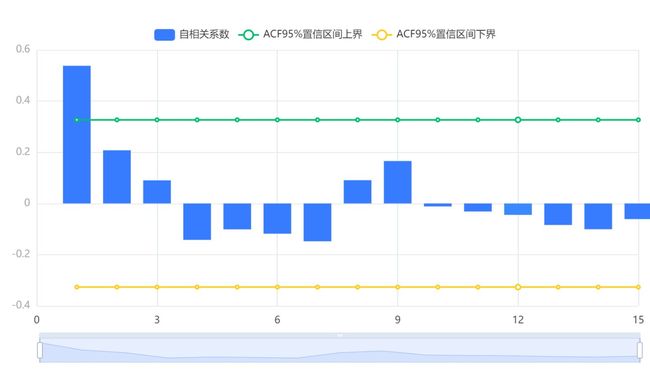
图表说明:由自相关图可知,一阶自相关系数很明显地大于2倍标准差范围,自一阶自相关系数后,其余自相关系数都在2倍标准差范围以内,我们可以判断自相关图为截尾。
输出结果4:最终差分数据偏自相关图(PACF)
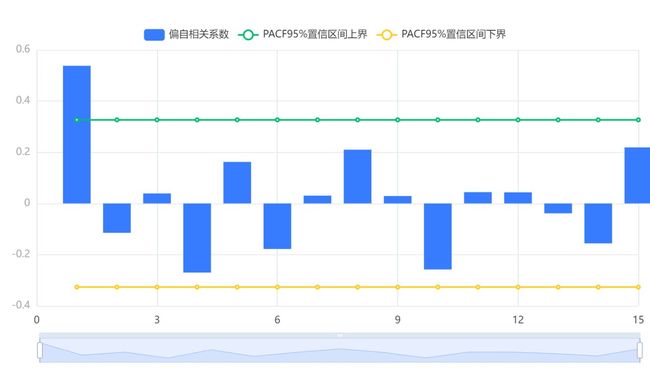
图表说明:由偏自相关图可知,一阶偏自相关系数很明显地大于2倍标准差范围,自一阶偏自相关系数后,其余自相关系数都在2倍标准差范围以内,我们可以判断偏自相关图为截尾。
输出结果5:模型参数表
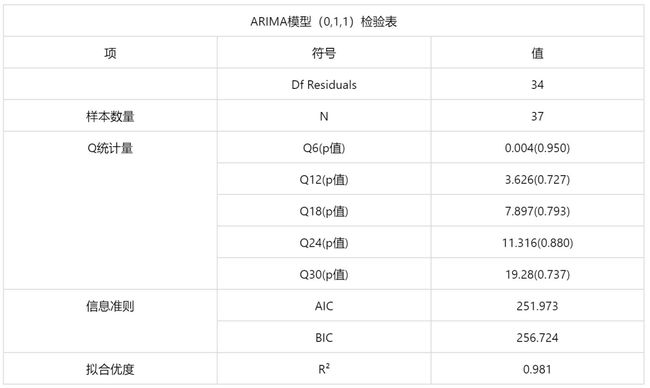
*p<0.05,**p<0.01,***p<0.001
图表说明:由于通过自相关分析和偏自相关分析来判断ARIMA的参数存在人为主观性,SPSSPRO基于AIC信息准则自动寻找最优参数,模型结果为ARIMA模型(0,1,1)检验表,基于字段:年度销量,从Q统计量结果分析可以得到:Q6在水平上不呈现显著性,不能拒绝模型的残差为白噪声序列的假设,同时模型的拟合优度R2为0.981,模型表现优秀,模型基本满足要求。(注意:一般来说,只检验前6期和前12延迟的Q统计量(即Q6和Q12)就可得出残差是否是随机序列的结论。这是因为平稳序列通常具有短期相关性,如果一个短期延迟序列值之间不存在显著的相关关系,通常延迟之间就更不会存在显著的相关关系。)
输出结果6:模型残差自相关图(ACF
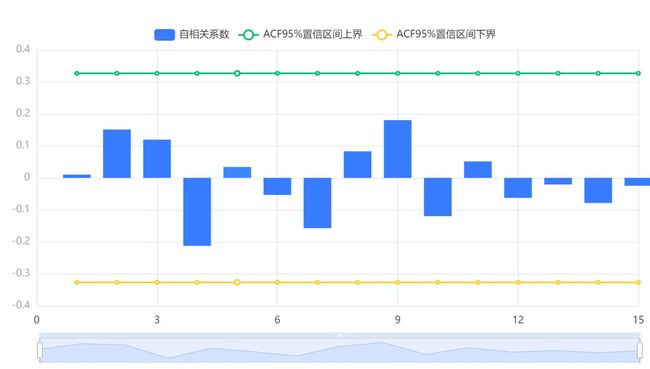
图表说明:上图展示了模型的残差自相关图,(ACF)若相关系数均在虚线(2倍标准差)内,自回归模型(AR)残差为白噪声序列,时间序列要求模型残差为白噪声序列。很明显,残差的自相关系数均在虚线内。
输出结果7:模型残差偏自相关图(PACF)
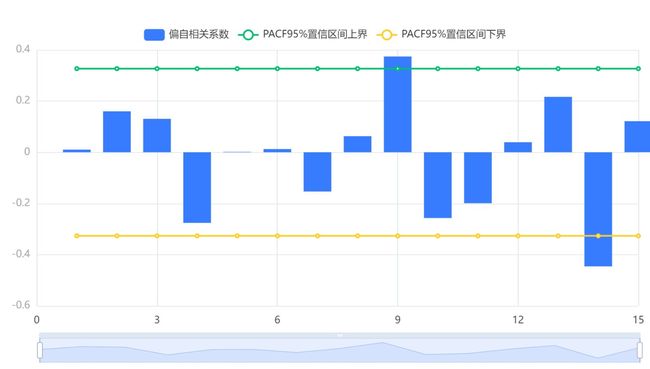
图表说明:上图展示了模型的残差偏自相关图(PACF),若相关系数均在虚线内,滑动平均模型(MA)残差为白噪声序列,时间序列要求模型残差为白噪声序列。很明显,残差的大部分偏自相关系数均在虚线内,即便第9阶与第14阶超过了2倍标准差,这可能是由于偶然因素引起的。
输出结果8:模型检验表

*p<0.05,**p<0.01,***p<0.001
图表说明:基于字段年度销量,SPSSPRO基于AIC信息准则自动寻找最优参数,模型结果为ARIMA模型(0,1,1)检验表且基于1差分数据,模型公式如下: y(t)=4.996+0.671*ε(t-1)
输出结果9:时间序列图
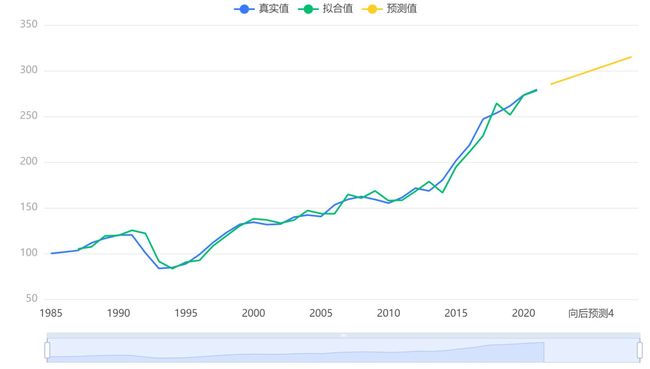
图表说明:上图表示了该时间序列模型的原始数据图、模型拟合值、模型预测值。从图可知,拟合序列趋势与真实序列趋势有着极大的相似性,说明拟合效果较好。
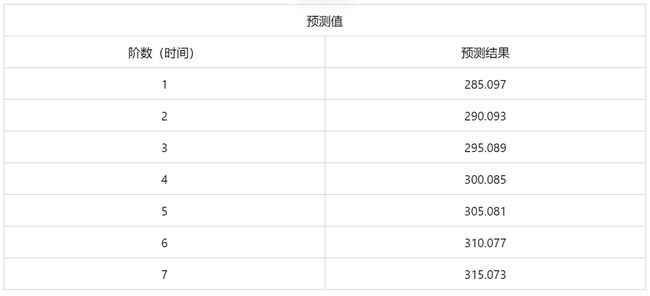
输出结果10:时间序列预测表
图表说明:上表显示了时间序列模型最近5期数据预测情况。
8、注意事项
- 出现以下情况,通常视为(偏)自相关系数d阶截尾:
- 在最初的d阶明显大于2倍标准差范围
- 之后几乎95%的(偏)自相关系数都落在2倍标准差范围以内
- 且由非零自相关系数衰减为在零附近小值波动的过程非常突然
- 出现以下情况,通常视为(偏)自相关系数拖尾:
- 如果有超过5%的样本(偏)自相关系数都落在两倍标准差范围之外
- 或者是由显著非0的(偏)自相关系数衰减为小值波动的过程比较缓慢或非常连续
- 分析自相关图和偏自相关图后,可以建立ARMA模型:
- 偏自相关(PACF)图在p阶进行截尾,自相关(ACF)图拖尾,ARMA模型可简化为AR(p)模型;
- 自相关(PACF)图在q阶进行截尾,偏自相关(ACF)图拖尾,ARMA模型可简化为MA(q)模型;
- 倘若自相关与偏自相关图均拖尾,可结合PACF、ACF图中最显著的阶数(最小值)作为p、q值;
- 倘若自相关与偏自相关图均截尾,可以选择更换更高的差分,或不适合建立ARMA模型;
- SPSSPRO默认采用AIC准则对q与p进行寻优定阶,采用adf检验+差分分析选择最优的差分阶层d
9、模型理论
ARIMA模型是被广泛运用于对各类时间序列数据分析和建模的方法。模型基于如下的观念:要预测的时间序列是由某个随机过程生成的.如果生成序列的随机过程不随时间变化,则该随机过程的结构可 以被确切地刻画和描述。利用序列过去的观察值,可以外推出序列的未来值。在ARIMA模型中,序列的未来值被表示成滞后项和随机干扰项的当期及滞后期的线性函数,即模型的一般形式如下式所示:
![]()
ARIMA模型的建模过程可以分为以下四个步骤:
步骤1 时间序列的平稳性检验.通常采用ADF或PP检验方法,对原始序列进行单位根检验.如果序列不 满足平稳性条件,可以通过差分变换或者对数差分变换,将非平稳时间序列转化为平稳时间序列,然后对平 稳时间序列构建ARIMA模型;
步骤2 确定模型的阶数.通过借助一些能够描述序列特征的统计量,如自相关(AC)系数和偏自相关(PAC) 系数,初步识别模型的可能形式,然后根据AIC等定阶准则,从可供选择的模型中选择一个最佳模型;
步骤3 参数估计与诊断检验.包括检验模型参数的显著性,模型本身的有效性以及检验残差序列是否为白噪 声序列.如果模型通过检验,则模型设定基本正确,否则,必须重新确定模型的形式,并诊断检验,直至得到设 定正确的模型形式;
步骤4 用建立的ARIMA模型进行预测.
10、参考文献
[1] 王燕.应用时间序列分析[M].北京:中国人民大学出版社2005.
[2] 郑莉,段冬梅,陆凤彬,等. 我国猪肉消费需求量集成预测——基于ARIMA、VAR和VEC模型的实证[J]. 系统工程理论与实践,2013,33(4):918-925.