PyTorch深度学习实践-P11卷积神经网络(高级篇)
复习
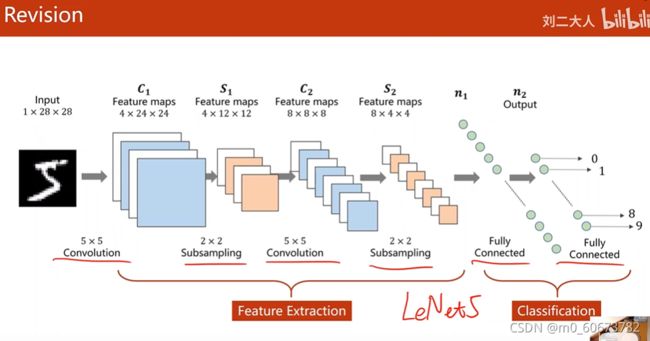
此网络结构与LeNet5很像,LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,是早期卷积神经网络中最有代表性的实验系统之一。参考资料:卷积神经网络的网络结构——以LeNet-5为例_strint的专栏-CSDN博客_lenet5卷积神经网络结构
 GoogLeNet:不是串行结构的CNN
GoogLeNet:不是串行结构的CNN
- 蓝色:卷积,红色:池化,黄色:softmax,other:拼接或者其他
- 减少代码冗余:函数/类,图中蓝蓝红 四个蓝 重复多次,考虑变成一块
- 蓝蓝红 四个蓝叫 Inception 套娃
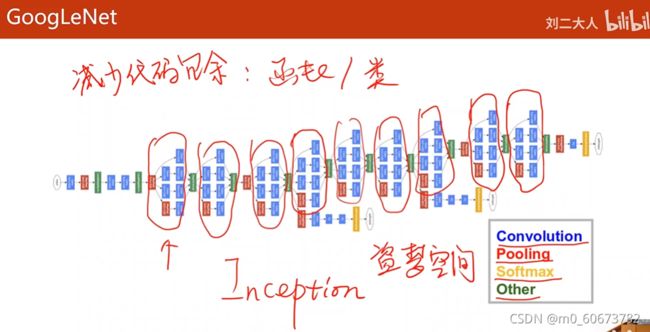
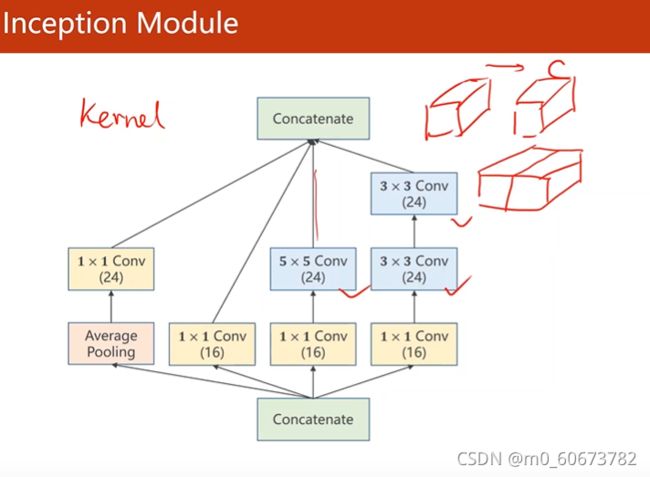
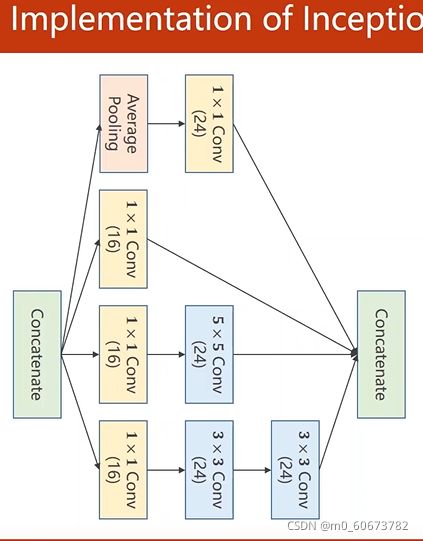
Inception module
- 一些超参数(比如kernel大小)很难确定,googlenet出发点是不知道哪个参数好,就把集中卷积都用,把他们结果挪在一起,哪种参数好他的权重就会变大,然后通过训练自动找到最优的几种组合
- 3*3 Conv
- Concatenate 把张量沿着通道拼接在一起
- average pooling 均值池化,要保证四个通道w h 一样
- 1*1卷积,表示卷积核1*1,个数取决于输入张量的通道,可以跨越不同通道相同位置元素的值(信息融合)最主要:改变通道数
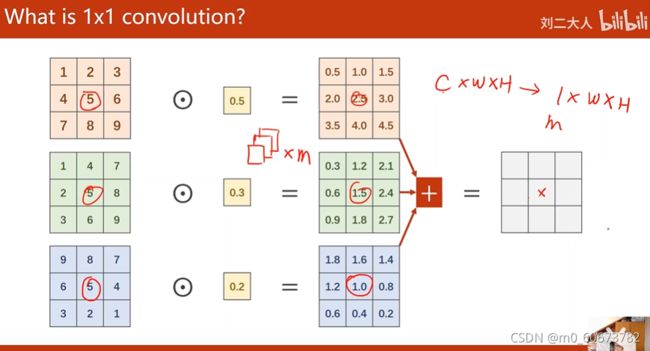
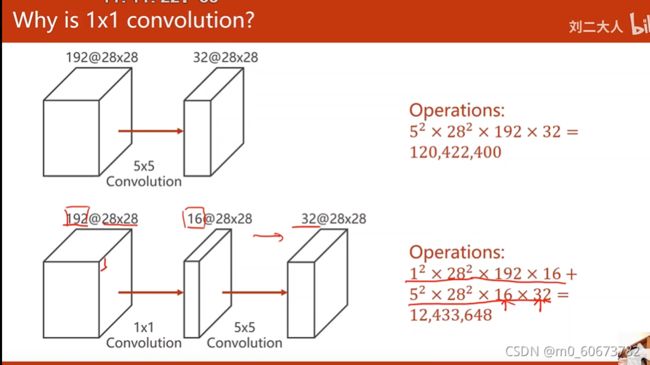
- (先padding)192*28*28经过5*5卷积变成32*28*28需要经过5^2*28^2*192*32, 卷积核大小5*5,与每个像素相乘28*28,然后乘通道数192,运算做了32次才能得到输出通道,共120million次
- 降低运算量:卷积核大小*像素*输入通道*输出通道,1*1卷积变成16*28*28的张量,在通过5*5的卷积变成32*28*28,运算量:1^2*28*28*192*16+5*5*28*28*16*32=12million
- 有时候把1*1卷积称为network in network
inception module 的代码实现:
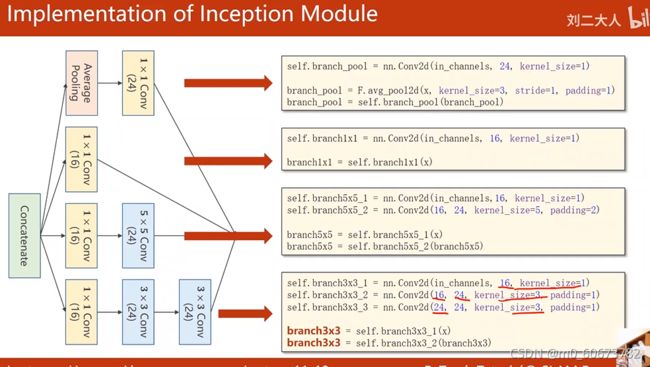
#第一个分支 池化分支branch——pool
#输出通道24,1*1卷积
self.branch_pool=nn.Conv2d(in_channels,24,kernel_size=1)
#forward
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)#可以保证average之后大小不变
branch_pool=self.branch_pool(branch_pool)#
#第二个分支branch1x1,1*1分支,16通道,kernel size=1
self.branch1x1=nn.Conv2d(in_channels,16,kernel_size=1)
branch1x1=self.branch1x1(x)
#第三个分支branch5x5分为两个模块, 1*1卷积,5*5,保证图片大小不变padding设成2,通道数输出16、24
self.branch5x5_1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2=nn.Conv2d(16,24,kernel_size=5,padding=2)
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
#第四个分支branch3x3,分成三块,一个1x1,3x3,3x3
self.branch3x3_1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2=nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3=nn.Conv2d(24,24,kernel_size=3,padding=1)
branch3x3=self.branch3x3_1(x)
branch3x3=self.branch3x3_2(branch3x3)
branch3x3=self.branch3x3_3(branch3x3)
- 沿着通道数把四个块拼接
#把前面的四个分支放到一个列表里,然后用cat沿着dim=1把他们拼起来 batch——size channel wideth height
outputs=[branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs.dim=1)- Iception全部代码
#inception block 抽象成一个类,以后可以
class InceptionA(nn.Module):
def __init__(self,in_channels):
super(InceptionA,self).__init__()
#in_channels没有写具体的数字为了实例化的时候可以指定输入通道数
#第一层
self.branch_pool=nn.Conv2d(in_channels,16,kernel_size=1)
# 第二层
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
# 第三层
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
#第四层
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self,x):
#第一层
branch1x1 = self.branch1x1(x)
#第二层
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
# 第三层
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
# 第四层
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) # 可以保证average之后大小不变
branch_pool = self.branch_pool(branch_pool)
#cat拼接
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs.dim=1)- 用inception写网络
#构造网络
class Net(nn.Module):
def __init__(self):
self.conv1=nn.Conv2d(1,10,kernel_size=5)
#88从inception来,将88降到20
self.conv2 = nn.Conv2d(88,20,kernel_size=5)
self.incep1=InceptionA(in_channels=10)
self.incep2=InceptionA(in_channels=20)
#maxpooling 和全连接
self.mp=nn.MaxPool2d(2)
self.fc=nn.Linear(1408,10)
def forward(selfself,x):
in_size=x.size(0)
#卷积 池化 relu,conv1之后输入通道变成10个
x=F.relu(self.mp(self.conv1(x)))
#incption后输出通道24+16+24+24=88个
x=self.incep1(x)
#conv2之后输出20
x=F.relu(self.mp(self.conv2(x)))
#输出88通道
x = self.incep2(x)
#变成向量
x=x.view(in_size,-1)
#全连接
x=self.fc(x)
return x
完整代码:
import torch.nn as nn
import torch
import torch.nn.functional as F
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
batch_size=64
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
train_dataset=datasets.MNIST(root="mnist",
train=True,
download=False,
transform=transform)
train_loader=DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset=datasets.MNIST(root='mnist',
train=False,
download=False,
transform=transform)
test_loader=DataLoader(dataset=test_dataset,
shuffle=False)
class InceptionA(torch.nn.Module):
def __init__(self,in_channels):
super(InceptionA,self).__init__()
self.branch_pool=torch.nn.Conv2d(in_channels,24,kernel_size=1)
self.branch1x1=torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_1=torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2=torch.nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1=torch.nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2=torch.nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3=torch.nn.Conv2d(24,24,kernel_size=3,padding=1)
def forward(self,x):
branch1x1=self.branch1x1(x)
branch5x5=self.branch5x5_2(self.branch5x5_1(x))
branch3x3=self.branch3x3_3(self.branch3x3_2(self.branch3x3_1(x)))
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool=self.branch_pool(branch_pool)
outputs=[branch1x1,branch3x3,branch5x5,branch_pool]
return torch.cat(outputs,dim=1)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1=torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2=torch.nn.Conv2d(88,20,kernel_size=5)
self.incep1=InceptionA(in_channels=10)
self.incep2=InceptionA(in_channels=20)
self.mp=nn.MaxPool2d(2)
self.fc=torch.nn.Linear(1408,10)
def forward(self,x):
in_size=x.size(0)
x=F.relu(self.mp(self.conv1(x)))
x=self.incep1(x)
x=F.relu(self.mp(self.conv2(x)))
x=self.incep2(x)
x=x.view(in_size,-1)
x=self.fc(x)
return x
net=Net()
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(net.parameters(),lr=0.01)
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,targets=data
inputs,targets=inputs.to(device),targets.to(device)
optimizer.zero_grad()
#forward
y_pred=net(inputs)
#backward
loss=criterion(y_pred,targets)
loss.backward()
#update
optimizer.step()
running_loss+=loss.item()
if(batch_idx%300==299):
print("[%d,%d]loss:%.3f"%(epoch+1,batch_idx+1,running_loss/300))
running_loss=0.0
accuracy=[]
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
images,labels=data
images,labels = images.to(device), labels.to(device)
outputs=net(images)
_,predicted=torch.max(outputs.data,dim=1)
total+=labels.size(0)
correct+=(labels==predicted).sum().item()
print("accuracy on test set:%d %% [%d/%d]"%(100*correct/total,correct,total))
accuracy.append(100 * correct / total)
if __name__=="__main__":
for epoch in range(10):
train(epoch)
test()
plt.plot(range(10),accuracy)
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.grid()
plt.show()
print("done")
- 把 inception 和 net替代上一讲,就能得到mnist的结果如下:
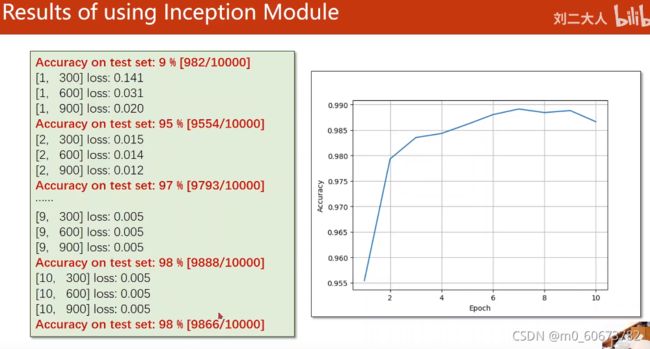
- 可以看到准确率后来下降了,所以不是训练轮数越多越好
ResidualNet残差
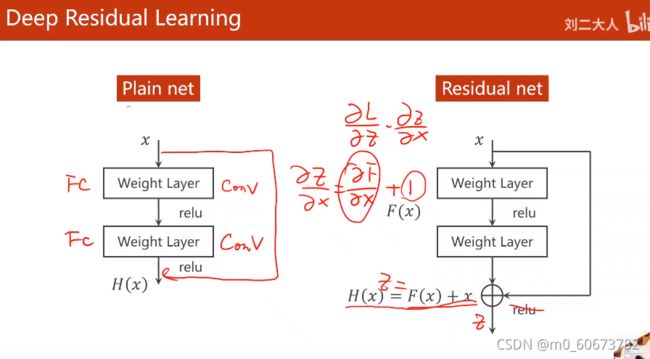 有人用CIFAR10数据集实验,结果20层性能比50层的卷积,这种情况有可能是因为 过拟合、梯度消失
有人用CIFAR10数据集实验,结果20层性能比50层的卷积,这种情况有可能是因为 过拟合、梯度消失 - 梯度消失是因为w在更新的过程中会变小,这样就导致离输入近的层的梯度没有得到很好的更新,resnet中将输入链接了,这样求导的话始终会+1,梯度就算很小也能保持在1附近
- 这两层的输出张量维度与输入一样
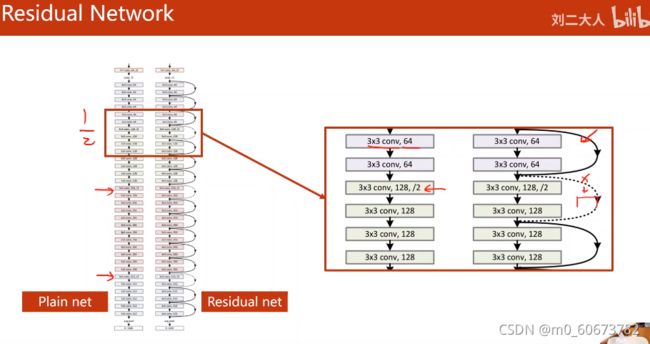
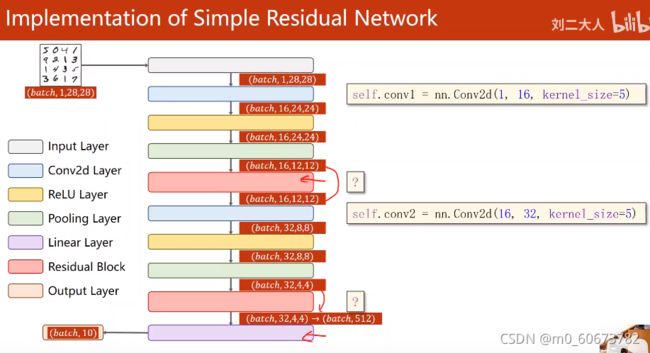
residual block
代码:
class ResidualBlock(nn.Module):
#需要保证输出和输入通道数x一样
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels=channels
#3*3卷积核,保证图像大小不变将padding设为1
#第一个卷积
self.conv1=nn.Conv2d(channels,channels,
kernel_size=3,padding=1)
#第二个卷积
self.conv2=nn.Conv2d(channels,channels,
kernel_size=3,padding=1)
def forward(self,x):
#激活
y=F.relu(self.conv1(x))
y=self.conv2(y)
#先求和 后激活
return F.relu(x+y) 
- 需要注意超参数~再写神经网络时可以将剩下的注释掉来检查超参数是否正确
-
完整代码:
-
import torch.nn as nn import torch import torch.nn.functional as F from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader import matplotlib.pyplot as plt batch_size = 64 transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,)) ]) train_dataset=datasets.MNIST(root="mnist", train=True, download=False, transform=transform) train_loader=DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_dataset=datasets.MNIST(root='mnist', train=False, download=False, transform=transform) test_loader=DataLoader(dataset=test_dataset, shuffle=False) class residual(nn.Module): def __init__(self,channels): super(residual,self).__init__() self.channels=channels self.conv1=nn.Conv2d(channels,channels,kernel_size=3,padding=1) self.conv2=nn.Conv2d(channels,channels,kernel_size=3,padding=1) def forward(self,x): y=F.relu(self.conv1(x)) y=self.conv2(y) return F.relu(x+y) class Net(nn.Module): def __init__(self): super(Net,self).__init__() self.conv1=nn.Conv2d(1,16,kernel_size=5) self.conv2 = nn.Conv2d(16, 32, kernel_size=5) self.mp=nn.MaxPool2d(2) self.residual1 = residual(16) self.residual2 = residual(32) self.fc=nn.Linear(512,10) def forward(self,x): batch_size=x.size(0) x=self.mp(F.relu(self.conv1(x))) x=self.residual1(x) x = self.mp(F.relu(self.conv2(x))) x = self.residual2(x) x=x.view(batch_size,-1) x=self.fc(x) return x net=Net() device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net.to(device) criterion=torch.nn.CrossEntropyLoss() optimizer=torch.optim.SGD(net.parameters(),lr=0.01) def train(epoch): running_loss=0.0 for batch_idx,data in enumerate(train_loader,0): inputs,targets=data inputs,targets=inputs.to(device),targets.to(device) optimizer.zero_grad() #forward y_pred=net(inputs) #backward loss=criterion(y_pred,targets) loss.backward() #update optimizer.step() running_loss+=loss.item() if(batch_idx%300==299): print("[%d,%d]loss:%.3f"%(epoch+1,batch_idx+1,running_loss/300)) running_loss=0.0 accuracy=[] def test(): correct=0 total=0 with torch.no_grad(): for data in test_loader: images,labels=data images,labels = images.to(device), labels.to(device) outputs=net(images) _,predicted=torch.max(outputs.data,dim=1) total+=labels.size(0) correct+=(labels==predicted).sum().item() print("accuracy on test set:%d %% [%d/%d]"%(100*correct/total,correct,total)) accuracy.append(100 * correct / total) if __name__=="__main__": for epoch in range(10): train(epoch) test() plt.plot(range(10),accuracy) plt.xlabel("epoch") plt.ylabel("accuracy") plt.grid() plt.show() print("done")
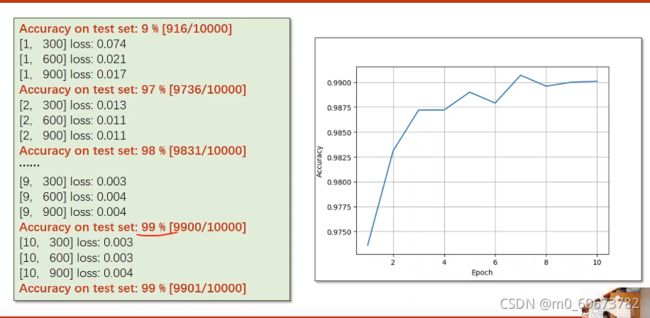
- 练习1:论文里的resnet实现以下 用mnist测试
- 练习2:DenseNet
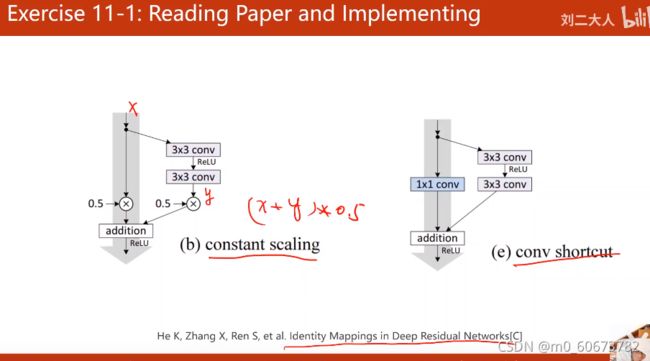
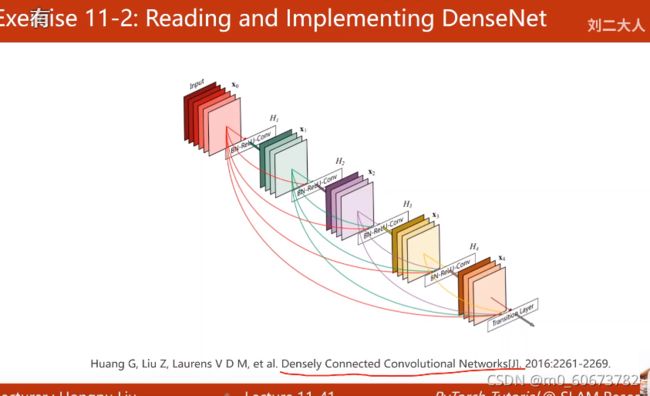
- 还需要理论角度深度理解模型
- 阅读pytorch文档(通读一遍)
- 复现经典工作 (不是代码下载 ,跑通,这只说明会配置环境... 应该读代码,尝试自己写代码
- 扩充视野(前三个基础),解决知识盲点,写代码的知识盲点,特定领域大量读论文,学会编程套路