tensorflow2.0 resnet18 CIFAR-10图像分类
基于ResNet18的CIFAR-10图像分类
- CIFAR-10数据分类
-
- CIFAR-10数据简介
- ResNet18网络
- ResNert18实验结果
CIFAR-10数据分类
CIFAR-10数据简介
Cifar-10 数据集是由Hinton教授的学生Alex Krizhevsky、Ilya Sutskever收集的一个用于普适物体识别的计算机视觉数据集,它包含 60000 张 32 * 32 的 RGB 彩色图片,总共 10 个分类,每一类包含6000张图片。其中,包括 50000 张用于训练集,10000 张用于测试集。在该数据集中,文件 data_batch_1.bin 、data_batch_2.bin 、… 、data_batch_5.bin 和test_ batch.bin中各有10000个样本。一个样本由3073个字节组成, 第一个字节为标签,剩下3072个字节为图像数据。整个数据集的10个类型分别为:飞机、小汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。
使用python版本的tensorflow框架,tensorflow框架提供了该数据集的自动下载和读取的方式。随机抽取展示20张图,如图所示,可以看出数据集上的图片为彩色图像。

ResNet18网络
深度残差网络(ResNet)模型诞生于2015年,是在针对于网络的退化问题,何凯明提出的残差学习方法,他提出的该模型获得了当年ImageNet竞赛的冠军。它的top5错误率为3.57%。该网络表明,卷积神经网络的层数存在着饱和度,并不是层数的堆叠就一定能够提高性能。其次,提出了层间残差跳连的思想,改善网络层数增加导致的退化,即梯度消失问题。
ResNet模型借鉴了Highway Network的思想,若网络的输入为x,并且希望得到的输出为H(x)。如果我们直接的进行这样的复杂映射,可能会比较困难。但是,如果把输入x直接作为初始结果,则输出为H(x)=F(x)+x,当F(x)=0时,该式转化为恒等映射,ResNet的学习目标变为残差,即H(x)-x,此时,训练的目标则是尽可能的使残差趋于0,这样训练的难度就大大的降低。
通过残差跨层连接结构,网络中某一层的输出可以跳过中间的某几层作为后面的其中一层的输入。ResNet的出现为加深网络层次而模型的性能提升提供了新的方向(如 DenseNet等),使得卷积神经网络的层数可以大大的加深。
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.python.keras.api._v2.keras import layers, Sequential, regularizers
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
from tensorflow.keras.utils import plot_model
from tensorflow import keras
import tensorflow.keras.preprocessing.image as image
np.set_printoptions(threshold=np.inf)#控制台输出所有的值,不需要省略号
#预处理
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
#数据集切分
x_valid,x_train=x_train[:3000],x_train[3000:]
y_valid,y_train=y_train[:3000],y_train[3000:]
#数据展示
labels = ['飞机','小汽车','鸟','猫','鹿','狗','青蛙','马','船','卡车']
plt.figure(figsize=(14,14))
#显示前10张图像,并在图像上显示类别
for i in range(20):
plt.subplot(4,5,i+1)
plt.grid(False)
plt.imshow(x_train[i,:,:,],cmap=plt.cm.binary)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
t = labels[y_train[i][0]]
plt.title(t)
plt.show()
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same',
kernel_regularizer=regularizers.l2(5e-5), use_bias=False, kernel_initializer='glorot_normal')
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same',
kernel_regularizer=regularizers.l2(5e-5), use_bias=False, kernel_initializer='glorot_normal')
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same',
kernel_regularizer=regularizers.l2(5e-5), use_bias=False, kernel_initializer='glorot_normal')
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())#加softmax
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
#模型训练
def model_train(x_train,y_train,x_valid,y_valid):
model = ResNet18([2, 2, 2, 2])
save_path = 'resnet18.h5'
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "ResNet18.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
tensorboard = tf.keras.callbacks.TensorBoard(log_dir='./model',histogram_freq =1,write_grads=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_valid, y_valid), validation_freq=1,
callbacks=[tensorboard])
#history = model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_valid, y_valid), validation_freq=1,
# callbacks=[cp_callback])
model.summary()
#权值保存
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
#模型保存
#model_path ='resnet18.h5'
#tf.saved_model.save(model,model_path)
#模型图保存
#plot_model(model, to_file='resnet18_model.jpg',show_shapes=True)
return history,model
############################################### show ###############################################
#数据可视化
def figshow(history):
'''
introductoin: 数据可视化,画出训练损失函数和验证集上的准确率
'''
# 显示训练集和验证集的acc和loss曲线
print('\n\n\n')
print('----------------------------------------------图像绘制-------------------------------------')
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplots(figsize=(8,6))
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
plt.subplots(figsize=(8,6))
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
#测试集测试
def data_test(x_test,y_test,model):
'''
@introduction :输出模型在测试集上的top1准确率和top2准确率
@parameter :
x_test 测试集数据
y_test 测试数据标签
model 训练好的模型
@return :
top1_acc top1标准下的准确率
top2_acc top2标准下的准确率
'''
print('****************************test******************************')
loss, acc = model.evaluate(x_test, y_test)
top1_acc = acc
#print("test_accuracy:{:5.2f}%".format(100 * acc))
y_pred = model.predict(x_test)
k_b = tf.math.top_k(y_pred,2).indices
idx=0
acc=0.0
for i in k_b:
if y_test[idx] in i.numpy():
acc=acc+1
idx=idx+1
top2_acc=acc/y_test.shape[0]
print('\n测试输出')
print('top1准确率:{0}\ntop2准确率:{1}'.format(top1_acc,top2_acc))
return top1_acc,top2_acc
if __name__ == '__main__':
#训练
history,model=model_train(x_train,y_train,x_test,y_test)
figshow(history)
#测试
data_test(x_test,y_test,model)
ResNert18实验结果
在实验时,将原始数据集分割为训练集,验证集和测试集。具体划分方法是:将50000张图片的2000张作为验证集,48000张作为训练集,10000张图片作为测试集。然后,对数据集的数据进行简单的归一化的预处理,能够让深度神经网络加速梯度下降求解出最优值。
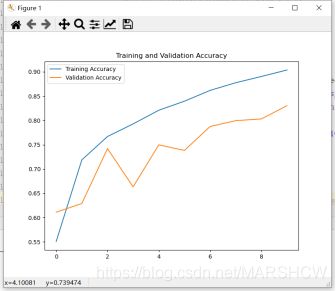
导出模型采用TensorBoard,TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。模型共有18层。考虑到设备的配置比较有限,所以训练之前将定义的ResNert18模型设置迭代次数为10次,学习率设置为默认的模式。经过10次的迭代之后,模型在训练集上的准确率为90.37%,在测试集上的准确率为83.03%。如下图3.6和3.7所示,两图像的横坐标都是迭代的次数,在迭代10次以后,训练集和测试集上的损失函数不断下降,说明模型没有过拟合。此外,也可以看出模型在训练集和测试集上的准确率在不断的提升。
1.部分模型展示
2.训练10次结果展示
由于采用CPU运行,运行时间较长。在完成模型简单训练之后,可以利用模型对测试集进行预测得到输出。首先,将训练保存得到的模型权重读出。读出之后调用temsorflow的函数model.evaluate()就可以得出Top1准确率,如下图所示,测试集上的top1准确率为83.03%, top2准确率为93.355。模型的准确率一般,可以在继续调整参数使之更加精准或者使用更加复杂的模型。
![]()
![]()