机器学习sklearn-特征过程及数据预处理
目录
1 基本概念
1.1 sklearn中的的数据预处理和特征工程
2 数据预处理 Preprocessing & Impute
2.1 数据无量纲化
2.1.1 数据归一化
2.1.2 数据标准化
2.2 缺失值
2.3 处理分类型数据:编码和哑变量
2.4 处理连续性特征:二值化与分段
3 特征选择
3.1 过滤法
3.1.1 方差过滤
3.1.2 相关性过滤
3.2 嵌入法
3.3 包装法
3.4 特征选择总结
1 基本概念
数据预处理的目的:让数据适应模型,匹配模型的需求。
特征工程是将原始数据转换为更能代表预测模型的潜在问题的特征的过程,可以通过挑选最相关的特征,提取特征以及创造特征来实现。其中创造特征又经常以降维算法的方式实现。
可能面对的问题有:特征之间有相关性,特征和标签无关,特征太多或太小,或者干脆就无法表现出应有的数据现象或无法展示数据的真实面貌
1.1 sklearn中的的数据预处理和特征工程
模块preprocessing:几乎包含数据预处理的所有内容
模块Impute:填补缺失值专用
2 数据预处理 Preprocessing & Impute
2.1 数据无量纲化
2.1.1 数据归一化
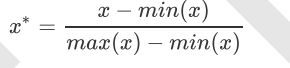
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
#实现归一化
scaler=MinMaxScaler() #实例化
scaler=scaler.fit(data) #训练
result=scaler.transform(data) #导出数据
print(result)
print(scaler.inverse_transform(result))#逆转 显示原来的数据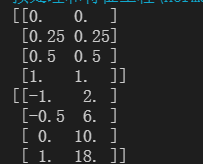
调整归一化的范围

scaler=MinMaxScaler(feature_range=[2,4]) #实例化
scaler=scaler.fit(data) #训练
result=scaler.transform(data) #导出数据
print(result)使用numpy实现归一化
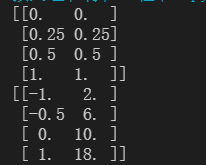
import numpy as np
#使用numpy实现归一化
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])#将数据类型改为ndarray
#归一化 是针对列做的操作 指定axis=0
X_normal=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
print(X_normal)
#逆转归一化
X_returned = X_normal* (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
print(X_returned)2.1.2 数据标准化
preprocessing.StandardScaler,当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:


from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler=StandardScaler()
scaler.fit(data)
x_std=scaler.transform(data)
print(x_std)
print(x_std.mean())
print(x_std.std())2.2 缺失值
读取本地的文件,并填充其缺失值。
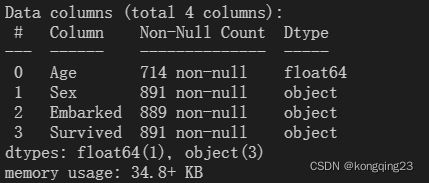
from numpy.core.arrayprint import printoptions
import pandas as pd
from sklearn.impute import SimpleImputer
data = pd.read_csv('Narrativedata.csv',index_col=0)#告知第0列是索引
# print(data.head())
# print(data.info())
#填补年龄
Age=data.loc[:,'Age'].values.reshape(-1,1)#-1,1将数据转换成一列 sklearn只接受二维以上
# print(Age.shape)
#实例化
imp_mean=SimpleImputer()
imp_median=SimpleImputer(strategy='median')
imp_0=SimpleImputer(strategy='constant',fill_value=0)
#训练并调出结果
imp_mean=imp_mean.fit_transform(Age)
imp_median=imp_median.fit_transform(Age)
imp_0=imp_0.fit_transform(Age)
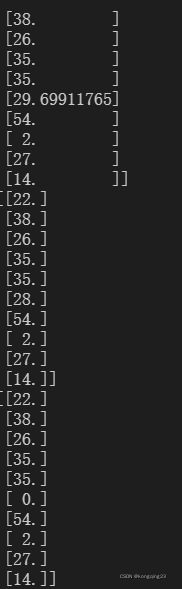
print(imp_mean[:10])
print(imp_median[:10])
print(imp_0[:10])
从上到下为均值填补,中值填补,0填补。
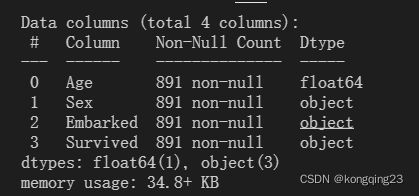
#使用众数填充embarked 众数可以包含文字型
Embarked = data.loc[:,"Embarked"].values.reshape(-1,1)
imp_most = SimpleImputer(strategy = "most_frequent")
data.loc[:,"Embarked"] = imp_most.fit_transform(Embarked)
print(data.info())也可以使用pandas的fillna和dropna对空值进行处理。
2.3 处理分类型数据:编码和哑变量
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fifit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。
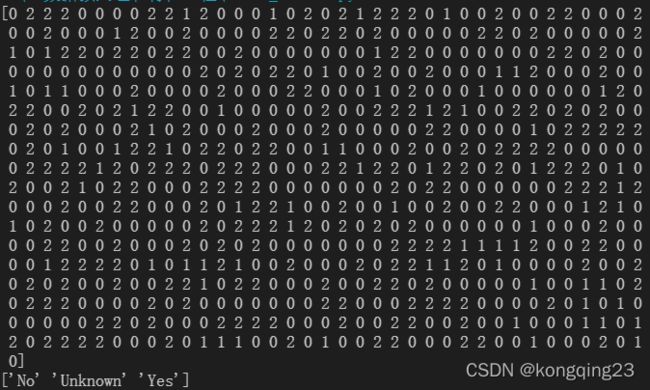
利用OrdinalEncoder将分类特征转换为分类数值。

preprocessing.OneHotEncoder:独热编码,创建哑变量

性别有两种类别,舱门有三种类别,所以转换出的哑变量有5列数据。
通过get_feature_names() 查看哑变量命名,并完成矩阵的合并。

from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OrdinalEncoder #特征专用,能够将分类特征转换为分类数值
from sklearn.preprocessing import OneHotEncoder #独热编码 创建哑变量
import numpy as np
import pandas as pd
data = pd.read_csv('Narrativedata.csv',index_col=0)#告知第0列是索引
#处理缺失值
data.loc[:,'Age']=data.loc[:,'Age'].fillna(data.loc[:,'Age'].mean())
data.dropna(axis=0,inplace=True)
data_=data.copy()
# print(data.info())
y=data.iloc[:,-1] #取出标签 labelencoder输入的是标签而不是特征矩阵 所以不需要升维 1维即可
le=LabelEncoder()#实例化
le=le.fit(y)
label=le.transform(y) #调取结果
# print(label)
# print(le.classes_)#查看标签中类别
data.iloc[:,-1]=label #把标签数值化
#一步完成
# data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
# print(data_.head(5))
#创建哑变量
X = data.iloc[:,1:-1] #取出要哑编码部分
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray() #将结果转为数组
# print(result)
#依然可以还原
# print(pd.DataFrame(enc.inverse_transform(result)))
#连接矩阵生成新数据
newdata = pd.concat([data,pd.DataFrame(result)],axis=1) #左右拼接
# print(newdata.head())
#性别和舱门信息已经被哑变量替代 删除
newdata.drop(['Sex','Embarked'],axis=1,inplace=True) #删列
# print(newdata.head())
#更改列索引
#print(enc.get_feature_names()) #查看哑变量
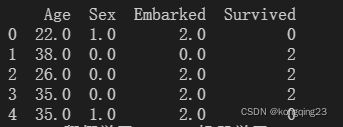
newdata.columns=["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"]
print(newdata.head())2.4 处理连续性特征:二值化与分段

3 特征选择

3.1 过滤法

3.1.1 方差过滤
import numpy as np
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
data = pd.read_csv('digit recognizor.csv')
# print(data.shape)
X = data.iloc[:,1:] #数据
y = data.iloc[:,0] #标签
#消除方差为0的特征
selector=VarianceThreshold()
X_var0=selector.fit_transform(X)
# print(X_var0.shape)
#消除一半的特征 以方差中位数为threshold
X_halfvar=VarianceThreshold(np.median(X.var().values)).fit_transform(X)
print(X_halfvar.shape)当特征是二分类时,特征的取值就是伯努利随机变量,这些变量的方差可以计算为:

#若特征是伯努利随机变量,假设p=0.8,即二分类特征中某种分类占到80%以上的时候删除特征
X_bvar = VarianceThreshold(.8 * (1 - .8)).fit_transform(X)
X_bvar.shape方差过滤对模型效果的影响,以随机森林为例,进行方差过滤以后准确率和速度都有非常细微的提升。
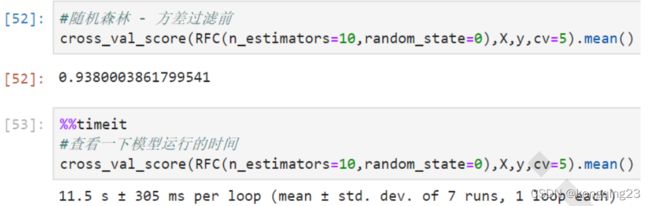


3.1.2 相关性过滤
![]()
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest#找出分数最高k个的特征的类
from sklearn.feature_selection import chi2#卡方检验
from sklearn.feature_selection import f_classif #f检验
import numpy as np
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
import matplotlib.pyplot as plt
data = pd.read_csv('digit recognizor.csv')
X = data.iloc[:,1:] #数据
y = data.iloc[:,0] #标签
X_halfvar=VarianceThreshold(np.median(X.var().values)).fit_transform(X)
#假设在这里我一直我需要300个特征
# X_fschi = SelectKBest(chi2, k=350).fit_transform(X_halfvar, y) #评估统计量使用卡方 选前300个
# print(X_fschi.shape)
#绘制学习曲线查看模型效果
# score=[]
# for i in range(390,120,-10):
# X_fschi = SelectKBest(chi2, k=i).fit_transform(X_halfvar, y)
# once=cross_val_score(RFC(n_estimators=10),X_halfvar,y,cv=10).mean()
# score.append(once)
# plt.plot(range(390,120,-10),score)
# plt.show()
#f检验
F,pvalues_f = f_classif(X_halfvar,y)#获取f检验两个参数
k=F.shape[0]-(pvalues_f>0.05).sum() #求出合适的k值
print(k)
X_fsF = SelectKBest(f_classif, k=392).fit_transform(X_halfvar, y)
score=cross_val_score(RFC(n_estimators=10),X_fsF,y,cv=5).mean()
print(score)互信息法
#互信息法
result=mutual_info_classif(X_halfvar,y)
k=result.shape[0]-sum(result<=0)
print(k)3.2 嵌入法

使用随机森林为例,则需要学习曲线来帮助我们寻找最佳特征值。
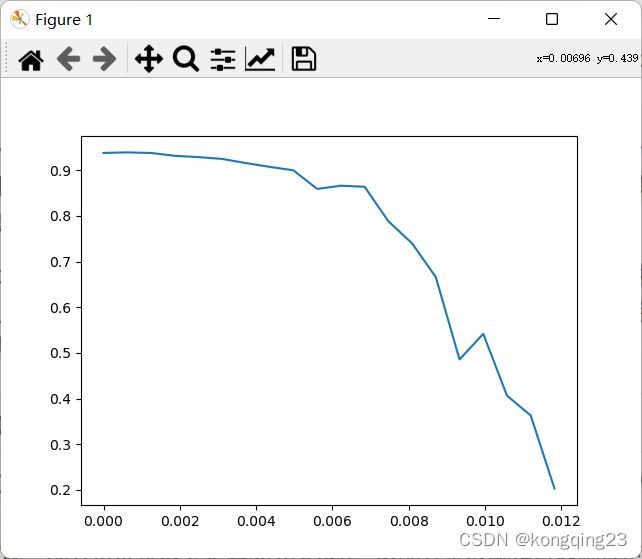
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#读取数据
data = pd.read_csv('digit recognizor.csv')
X = data.iloc[:,1:] #数据
y = data.iloc[:,0] #标签
RFC_=RFC(n_estimators=10)#随机森林实例化
feature_im=RFC_.fit(X,y).feature_importances_
# print(feature_im)
threshold=np.linspace(0,feature_im.max(),20)#从0开始生成20个threshold
# print(threshold)
#绘制学习曲线
score=[]
for i in threshold:
x_embeded=SelectFromModel(RFC_,threshold=i).fit_transform(X,y)#实例化嵌入法
once=cross_val_score(RFC_,x_embeded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
3.3 包装法
feature_selection.RFE
![]()