使用ResNet18处理cifar10数据集
目录
前言
1.数据集介绍
2.使用的工具介绍
3.搭建ResNet
3.1ResNet结构分析
3.2网络结构搭建与代码实现
3.3中间过程特征提取
总结
前言
在对CNN有了一定的了解后,尝试搭建ResNet18网络来处理CIFAR-10数据集,通过这此的模型搭建,来熟悉层数较少的ResNet的代码实现,以及测试ResNet网络在处理CIFAR-10数据集上的性能,但是由于ResNet网络结构比较复杂,并且设备的原因算力不行,可能这次模型的性能比较低,在可行的基础上对ResNet18网络进行一些简化,以及改造。
1.数据集介绍
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但一些训练批次可能包含来自一个类别的图像比另一个更多。总体来说,五个训练集之和包含来自每个类的正好5000张图像。里面类别包括飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船,卡车十个类别。
2.使用的工具介绍
主要是TensorboardX和Netron进行可视化,具体介绍参照我之前的cnn处理MNIST数据集文章https://blog.csdn.net/qq_41845951/article/details/118814447
3.搭建ResNet
3.1ResNet结构分析
当网络结构增加的时候,网络的 深度也会增加,随之也会产生梯度离散或者梯度爆炸的情况,深层次网络结构主要是梯度离散,简而言之就是,网络的深度达到某个临界值,网络的性能会降低。
因此,ResNet结构出现,用来解决这一问题,

上图就是ResNet的最基本的结构,在基本的CNN网络结构中加了shortcut结构,
之所以网络深度增加后网络的性能会降低,是因为反向传播中,梯度在某个地方小于1了,那么梯度是会越来越接近于0,导致梯度无法更新,再也学不到新的东西,对于shortcut结构,我们是在这个是用现在的梯度,加上求导之前的梯度,相当于增加了梯度,于是,梯度弥散的现象会减小。
从特征方面来看,对于卷积操作,每一次卷积,特征会更加的细致,当然也会丢掉一些有用的特征,从而导致深层次的网络性能会有所降低,shortcut操作,可以理解为当前的特征加上经过一个Bottleneck(上图的结构层)后的特征,保存了更多的特征信息。
因此,ResNet能够保证网络在加上了一个Bottleneck后,至少不比原来的网络层性能低。
3.2网络结构搭建与代码实现
数据集的导入以及预处理,
resize()调整图片尺寸
ToTensor()转换成tensor
Normalize()归一化预处理,可以看我之前的文章
batch_size用来测试或者训练的图片的数量,shuffle数据打乱
batchsz = 100
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
x, label = iter(cifar_train).next()
print('x:', x.shape, 'label:', label.shape)选取图片进行查看,为了方便,只显示了一个通道,因此是灰色的
# 查看部分数据
fig, axis = plt.subplots(4, 6, figsize=(15, 10))
images, labels = next(iter(cifar_train))
for i, ax in enumerate(axis.flat):
with torch.no_grad():
image, label = images[i][:1,:,:], labels[i]
ax.imshow(image.view(32,32), cmap='binary')
plt.show()
搭建模型,首先定义一个Bottleneck,也就是一个单位网络层
其中主要结构为池化-归一-池化-归一
当然还有一个维度的处理,如果输入的channel与输出的channel不同,那么F(x)与x不能相加,于是有个维度的处理,使[b,ch_in,h,w] 可以变换成[b,ch_out,h,w]
而后是shortcut操作out = self.extra(x)+out
class Bottleneck(nn.Module):
def __init__(self,ch_in,ch_out):
super(Bottleneck,self).__init__()
self.conv1 = nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out !=ch_in:
# [b,ch_in,h,w] ==>[b,ch_out,h,w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self,x):
#param x:[b,ch,h,w]
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
#short cut.
#element-wise add:[b,ch_in,h,w] with [b,ch_out,h,w]
out = self.extra(x)+out
return out接着搭建ResNet18网络,
结构为池化-归一-Bottleneck1-Bottleneck2-Bottleneck3-Bottleneck4,最后再摊平一维化
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,16,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(16)
)
#followed 4 blc
self.blk1 = Bottleneck(16,16)
self.blk2 = Bottleneck(16,32)
# self.blk3 = Bottleneck(128, 256)
# self.blk4 = Bottleneck(256, 512)
self.outlayer = nn.Linear(32*32*32,10)
def forward(self,x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
# x = self.blk3(x)
# x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0),-1)
x = self.outlayer(x)
return x初始化模型,loss,以及选择优化器,并将他们放入cuda中加速,并打印出网络结构
device = torch.device('cuda')
model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)打印出网络结构为
ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(blk1): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(extra): Sequential()
)
(blk2): ResBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(extra): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(blk3): ResBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(extra): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(blk4): ResBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(extra): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(outlayer): Linear(in_features=524288, out_features=10, bias=True)
)
由于cuda内存不足,为了更快的运行,就暂时只有两个block进行训练,缩减网络的复杂度,更快的得出结果。
class Bottleneck(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,16,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(16)
)
#followed 4 blc
self.blk1 = Bottleneck(16,16)
self.blk2 = Bottleneck(16,32)
self.outlayer = nn.Linear(32*32*32,10)
def forward(self,x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
# print(x.shape)
x = x.view(x.size(0),-1)
x = self.outlayer(x)
return x训练,并保存训练中的loss以及acc等,训练部分代码讲解可以参考我的文章
train_loss = []
Acc = []
for epoch in range(20):
model.train()
running_loss = 0
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss.append(running_loss / len(cifar_train))
print('epoch:',epoch+1, 'loss:', loss.item())
model.eval()
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
Acc.append(total_correct / total_num)
print(epoch, 'test acc:', acc)test acc: 0.6602
可视化loss和acc
plt.plot(train_loss, label='Loss')
plt.plot(Acc, label='Acc')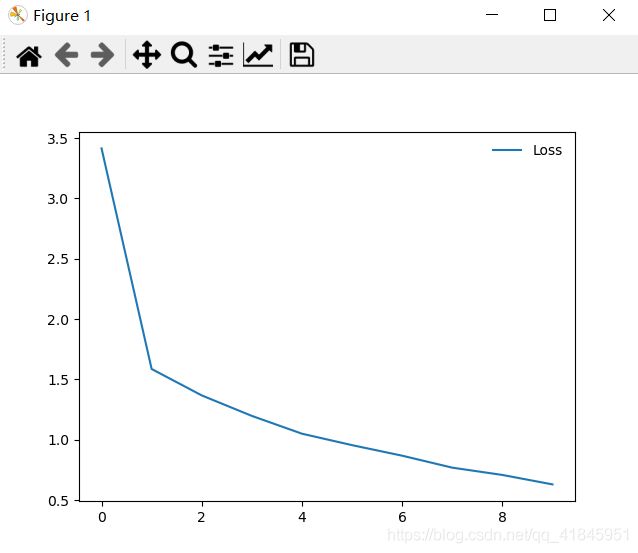

优化模型,加入非线性激活函数,使用3个Bottleneck,设置stride变量,用stride=2以及池化层降维,调整参数,使模型能够在cuda上运行。
class Bottleneck(nn.Module):
def __init__(self,ch_in,ch_out,stride):
super(Bottleneck,self).__init__()
self.conv1 = nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=stride,padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
nn.ReLU(inplace=True)
self.extra = nn.Sequential()
if ch_out !=ch_in:
# [b,ch_in,h,w] ==>[b,ch_out,h,w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride),
nn.BatchNorm2d(ch_out)
)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
#param x:[b,ch,h,w]
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
#short cut.
#element-wise add:[b,ch_in,h,w] with [b,ch_out,h,w]
out = self.extra(x)+out
return self.relu(out)
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,32,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1),
)
#followed 4 blc
self.blk1 = Bottleneck(32,32,1)
self.blk2 = Bottleneck(32,64,1)
self.blk3 = Bottleneck(64,128,2)
# self.blk4 = Bottleneck(256, 512)
self.outlayer = nn.Linear(128*8*8,10)
def forward(self,x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
# x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0),-1)
x = self.outlayer(x)
return xtest acc: 0.8018
可视化loss以及acc
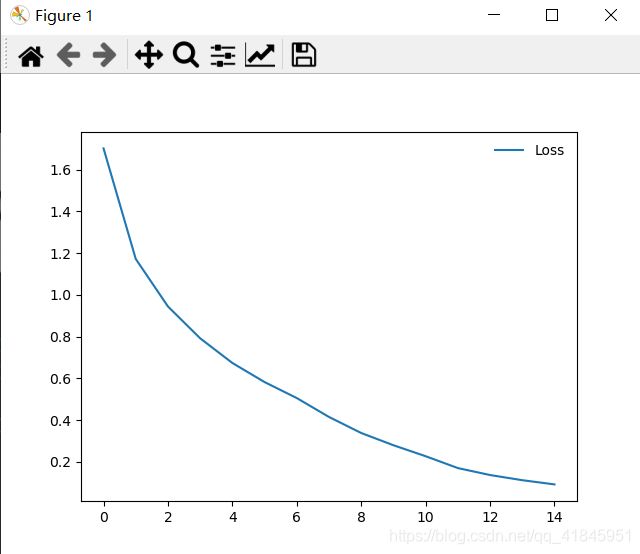
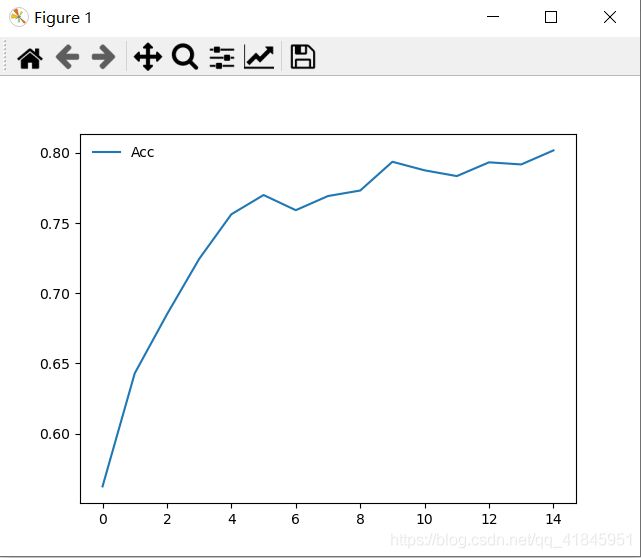
通过对模型的优化,正确率提升了15%左右,最终loss: 0.1143,acc:acc: 0.8018,可以看到还是存在过拟合现象
可能是因为cuda内存有限,没有使用标准的4个Bottleneck,以及很多地方进行了降维操作,并且train数据集偏少
3.3中间过程特征提取
conv1层,这一层输出有32个通道
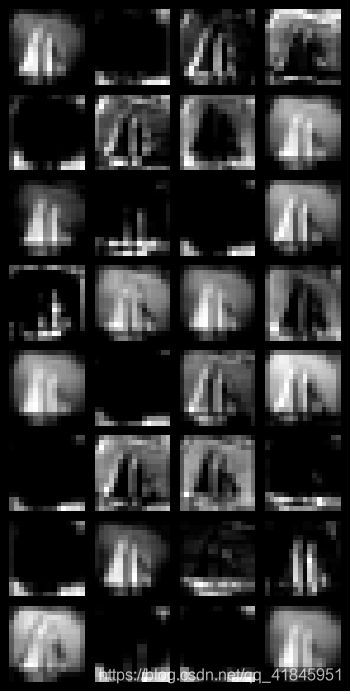
blk1层,输出有64个通道,截取部分特征

blk2层,有32个通道,截取部分特征

blk3层,有16个通道

可以看出每深一层,特征就更加细致,同时有不少特征都是相似的。
总结
本次搭建了最简单的ResNet18,熟悉了ResNet的原理以及结构,
但是由于设备原因,只用了3个Bottleneck,以及很多地方进行了降维操作,并且train数据集偏少,如果再设备允许的情况下,正确率还会再提升的
其次,由于是第一次接触这个网络,确实有很多方面可能没理解到,对于网络的优化可能没有做到位,过后会继续深入学习,争取改正这个模型。