MindSpore自定义算子:思考,挑战与实践
引言
陈天奇在《新一代深度学习编译技术变革和展望》一文中曾经提到,当前阻碍深度学习的全栈解决方案发展的主要是两个隔阂,包括:
-
竖向隔阂,也就是手工优化的方案和自动编译优化的方案的隔阂。当前的大部分深度学习框架面临以手工算子优化为主的算子库和以自动优化为主的编译方案二选一的困境,如何让手工优化,机器学习优化专家的知识和自动优化做有机整合,是目前行业面临一个大的问题。
-
横向隔阂,也就是图算软件分层引起的跨层隔阂。当前的大部分深度学习框架对不同层次的抽象分开设计导致,例如图层和算子层的分离,但是深度学习编译和优化本身不是一个一个层级可以全部完成优化的问题。解决相关问题需要各个层级抽象之间的联动。
在网络开发实践中,我们也深深的感受到了这两种隔阂对计算表达的严重限制。
一方面,我们注意到竖向隔阂不仅仅存在于手工优化的方案和自动编译优化的方案之间,同样存在于不同的手工优化的方案之间。深度学习框架在整合这些优化方案加速网络时面临比较大的阻碍:有的手工优化的算子以第三方算子库的形式呈现,全部加入框架会使框架过于厚重;有的手动优化方案只能针对某些特定场景有效,无法作为一个普遍的优化应用在全部场景。特别是在AI-HPC融合场景中,HPC的应用中的算子很多是针对特殊硬件做的专门优化,如何有机的整合这类算子,是深度学习框架面对AI-HPC融合场景的一个重要挑战。
另一方面,在业界的大部分深度学习框架中,算子的表达与注册独立于模型(也就是图层),图层视算子为黑盒。当用户在框架之外独立添加算子时,图层无法了解算子内部的具体计算逻辑,因此无法进行例如算子融合和算子拆分等图层上的优化。如何在图层上直接定义算子,让图层感知算子的具体逻辑,是打破图层和算子层的横向隔阂,实现各个层级抽象之间的联动的重要议题。
总的来说,一个深度学习的全栈解决方案总是会遇到不同算子优化方案的竖向隔阂和图算抽象分离的横向隔阂。为了解决如上隔阂引入的表达问题,MindSpore给出了自己的解决方案,即统一自定义算子表达。
1
新接口:MindSpore自定义算子统一接口Custom
随着MindSpone在科学计算等新型网络场景的大量使用,对算子的灵活性表达提出更高的要求,针对传统深度学习网络设计的算子库越来越无法满足需求。因此,MindSpore自1.6起推出自定义算子统一接口Custom,并在1.8版本迎来全新升级,有机的结合了手动优化和自动编译算子,并让图层感知算子的定义,助力用户方便高效的添加自定义算子,可以满足包括快速验证,实时编译和第三方算子接入等不同场景下的用户需求。
当前自定义算子支持的算子开发方式包括:ms_kernel、tbe、aicpu、aot、pyfunc、julia。不同的算子开发方式支持不同的场景和不同的平台。
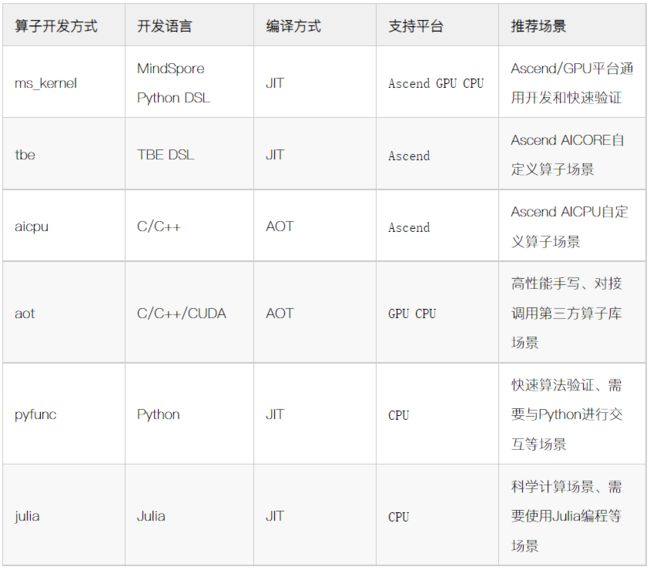

自定义算子模式和平台支持
在设计自定义算子的多种模式时,我们充分考虑到了阻碍深度学习的全栈解决方案发展的两个隔阂,并用统一的接口去实现框架对算子的多种需求。
1.1
手工优化算子的一键接入
在前面的讨论中我们曾经提到,深度学习全栈解决方案发展的纵向隔阂是手工优化的方案和自动编译优化的方案的隔阂。为了方便用户快捷的接入手工优化的算子,MindSpore自定义算子统一接口Custom提供aot模式,灵活封装手工算子。用户可以手工优化算子实现,并把算子以动态库的形式接入MindSpore加速网络。
特别的,当第三方库提供CPP或者CUDA函数的API时,我们可以自定义算子中调用第三方库的API,然后通过编译链接将第三方库接入MindSpore加速网络,从而实现手工优化算子的一键接入。以PyTorch的Aten库为例进行介绍,我们在网络迁移的时候会遇到基于PyTorch的网络中的部分算子尚未被MindSpore支持的情况。为了快速支持网络,我们可以利用Custom算子的 aot 开发方式调用PyTorch Aten的算子进行快速验证。我们可以直接使用Aten提供的算子接口去实现的计算逻辑。例如在下面的代码中,我们直接使用Aten提供的torch::leaky_relu_out算子接口去实现LeakyRelu的计算。
#include
#include // 头文件引用部分
int8_t GetDtype(const std::string &dtypes) {
int8_t type = 6;
std::unordered_map m {
{"uint8", 0}, {"int8", 1}, {"int16", 2}, {"int32", 3}, {"int64", 4}, {"float16", 5}, {"float32", 6}, {"float64", 7}};
if (m.count(dtypes)) {
type = m[dtypes];
}
return type;
}
extern "C" int LeakyRelu(
int nparam,
void** params,
int* ndims,
int64_t** shapes,
const char** dtypes,
void* stream,
void* extra) {
std::vector tensors;
for (int i = 0; i < nparam; i++) {
std::vector size;
for (int j = 0; j < ndims[i]; j++) {
size.push_back(shapes[i][j]);
}
int8_t type = GetDtype(dtypes[i]);
auto option = at::TensorOptions().dtype(static_cast(type)).device(device);
tensors.emplace_back(at::from_blob(params[i], size, option));
}
auto at_input = tensors[0];
auto at_output = tensors[1];
torch::leaky_relu_out(at_output, at_input);
return 0;
} import numpy as np
import mindspore as ms
from mindspore.nn import Cell
import mindspore.ops as ops
ms.set_context(device_target="CPU")
def LeakyRelu():
return ops.Custom("./leaky_relu_cpu.so:LeakyRelu", out_shape=lambda x : x, out_dtype=lambda x : x, func_type="aot")
class Net(Cell):
def __init__(self):
super(Net, self).__init__()
self.leaky_relu = LeakyRelu()
def construct(self, x):
return self.leaky_relu(x)
if __name__ == "__main__":
x0 = np.array([[0.0, -0.1], [-0.2, 1.0]]).astype(np.float32)
net = Net()
output = net(ms.Tensor(x0))
print(output)此外在昇腾平台上,我们已经拥有基于自动优化的TBE算子库,但是对于一些不规则的运算,需要基于手工优化的AICPU 算子。因此Custom特别提供了aicpu类型算子的支持,采用aot模式编译,可以把基于手工优化的AICPU算子快捷地部署到主流嵌入式平台上。AICPU算子相对于TBE算子,擅长逻辑类操作,对于难以向量化的算子,有较大的性能收益。如此我们可以在昇腾平台上同时使用基于自动优化的TBE算子库和基于手工优化的AICPU算子,把昇腾平台的加速能力应用到更多场景之中。
1.2
图层与算子的有机结合
MindSpore的图算融合特性中做到了图层和算子层的表达在后端的融合,但是在前端表达上,图层和算子层依然是相互独立的DSL。如何在图层中定义算子,让图算在前端就有机的结合在一起,是打破图算横向隔阂的重要议题。MindSpore自定义算子统一接口Custom充分考虑到了这一点的需求。在tbe模式中,用户可以直接使用算子编译器的DSL在图层中书写算子,通过Custom接口采用即时编译的方式加入网络进行计算。例如:
import numpy as np
import mindspore as ms
import mindspore.ops as ops
from mindspore.ops import DataType, CustomRegOp, custom_info_register
ms.set_context(device_target="Ascend")
# 算子实现,注册算子信息
@custom_info_register(CustomRegOp() \
.input(0, "a") \
.input(1, "b") \
.output(0, "output") \
.dtype_format(DataType.F16_Default, DataType.F16_Default, DataType.F16_Default) \
.dtype_format(DataType.F32_Default, DataType.F32_Default, DataType.F32_Default) \
.target("Ascend") \
.get_op_info())
def add(a, b, output, kernel_name="add"):
import te.lang.cce
from te import tvm
data0 = tvm.placeholder(a.get("shape"), name="data0", dtype=a.get("dtype").lower())
data1 = tvm.placeholder(b.get("shape"), name="data1", dtype=b.get("dtype").lower())
res = te.lang.cce.vadd(data0, data1)
with tvm.target.cce():
sch = te.lang.cce.auto_schedule(res)
config = {"print_ir": False, "name": kernel_name, "tensor_list": [data0, data1, res]}
te.lang.cce.cce_build_code(sch, config)
if __name__ == "__main__":
# 定义tbe类型的自定义算子
op = ops.Custom(add, out_shape=lambda x, _: x, out_dtype=lambda x, _: x, func_type="tbe")
x0 = np.array([[0.0, 0.0], [1.0, 1.0]]).astype(np.float32)
x1 = np.array([[2.0, 2.0], [3.0, 3.0]]).astype(np.float32)
output = op(ms.Tensor(x0), ms.Tensor(x1))
print(output)这里,我们直接在定义网络的脚本中用算子的TBE DSL定义算子,并且使用Custom的tbe模式加入网络进行计算,大大的提高了开发效率。
2
新特色:从AI到科学计算
在设计MindSpore自定义算子统一接口之初,我们从例如网络迁移、图算联合表达等实际问题出发,实现了Custom模式的基础模式和功能。在MindSpore版本的迭代过程中,我们同样面向未来进行展望,立足于MindSpore未来发展的方向,在自定义算子方面的寻求突破。其中,作为MindSpore未来的发展方向之一,AI和科学计算的融合越来越受到业界的重视。MindSpore自定义算子基于自身的优势,也在科学计算方面做出了探索。
2.1
业界首个支持Julia的AI框架
Julia是一种速度快且使用简单的高级通用编程语言,最初设计用于科学计算领域,而由于其高效而实用的特性,近些年来越来越受到用户的青睐,逐步迈向主流编程语言。Julia语言最大的特点是他的易用性,用户可以像书写数学公式一样写代码,给算子开发带来极大便利。因此,MindSpore自定义算子开发接口Custom从算子出发,提供julia模式,把基于Julia语言开发的算子和基于MindSpore开发的模型有机的结合在一起,让MindSpore成为业界首个支持Julia的AI框架。用户可以采用Julia书写算子加速运算,并享受Julia丰富的生态带来的便利。例如,用户可以用Julia实现一个加法函数如下:
# add.jl
module Add
# inputs: x, y, output: z, output should use .= to inplace assign
function add(x, y, z)
z .= x + y
end
end那么我们就可以在网络脚本中通过自定义算子方式的julia模式引用上面的函数作为算子,例如:
import numpy as np
from mindspore import context, Tensor
import mindspore.ops as ops
context.set_context(device_target="CPU")
class Net(Cell):
def __init__(self):
super(Net, self).__init__()
# 定义julia类型的自定义算子
self.add = ops.Custom("./add.jl:Add:add", out_shape=lambda x, _: x, out_dtype=lambda x, _: x, func_type="julia")
def construct(self, x, y):
return self.add(x, y)
if __name__ == "__main__":
net = Net()
x0 = np.array([[0.0, 0.0], [1.0, 1.0]]).astype(np.float32)
x1 = np.array([[2.0, 2.0], [3.0, 3.0]]).astype(np.float32)
output = net(Tensor(x0), Tensor(x1))
print(output)如此,用户在模型移植,快速验证以及模型加速等场景下使能Julia算子,在基于MindSpore开发的模型中享受Julia语言对计算带来的收益。特别是科学计算场景,我们可以利用Julia强大的表达能力,用Julia书写相关算子,助力MindSpore在AI+科学计算场景的应用。
2.2
跨平台统一的ms_kernel模式
上面我们提到,MindSpore自定义算子统一接口Custom实现了图算的表达在前端进行的融合,解决了图、算子跨层表达存在隔阂的问题。但是,由于基于这种方式开发的算子都是利用算子编译器自动调优后即时编译加入网络,在实际的算子开发工作中,特别是科学计算相关的算子开发时,我们依然发现了如下问题:
1、当前的算子编译器的自动调度功能,多是基于深度学习算子进行的调优,主要针对的是大规模可并行的规则计算场景。而科学计算面对的很对非规则计算场景,现有的基于深度学习的调度经验略显不足,在DSA架构上的调度缺陷更为明显;
2、科学计算相关的算子计算逻辑相对复杂,对调试的要求很高,需要对算子多次调试以确定算法的正确性。
为了解决这两个问题,MindSpore1.8版本提供跨平台统一的ms_kernel模式。ms_kernel模式的自定义算子一次开发便可以在所有后端使用。特别的,ms_kernel模式提供新的调度原语,帮助自定义算子在昇腾后端使能新的调度器模块,实现手自一体的算子调度协助代码生成,帮助用户使能昇腾后端加速科学计算任务。另外,ms_kernel模式的算子可以使能Python原生解释器运行以满足快速验证的需求。
2.2.1
新调度原语助力调度
为了解决算子的调度问题,ms_kernel模式提供调度原语以描述不同类型的循环。在Ascend后端,调度原语将协助昇腾后端的新调度器生成代码。此类调度原语包括:
1、serial: 提示调度器该循环在调度生成时应保持前后顺序,不要做会改变顺序的调度变换;
2、vectorize: 一般用于最内层循环,会提示调度器该循环有生成向量化指令的机会;
3、parallel: 一般用于最外层循环,会提示调度器该循环有并行执行机会,并提示调度器优先考虑这个并行执行;
4、reduce: 会提示调度器该循环为运算中的一个Reduction轴。
用户书写算子时候可以把自己的经验指导调度器在昇腾后端生成高效代码。例如我们可以看下面这个例子:
import numpy as np
from mindspore import context, Tensor, ops
from mindspore.ops import ms_kernel
context.set_context(device_target="Ascend")
@ms_kernel
def hybrid_dsl_test(a, b):
for i in parallel(a.shape[0]):
for j in serial(a.shape[1]):
for k in serial(j):
b[i, j] = b[i, j] - a[i, j, k] * b[i, j]
return b
class Net(Cell):
def __init__(self):
super(Net, self).__init__()
# 定义ms_kernel类型的自定义算子(Custom的默认模式)
self.cus_op =ops.Custom(hybrid_dsl_test)
def construct(self, x, y):
return self.cus_op(x, y)
if __name__ == "__main__":
net = Net()
x0 = np.random.randn(16, 16, 16).astype(np.float32)
x1 = np.random.randn(16, 16).astype(np.float32)
output = net(Tensor(x0), Tensor(x1))
print(output)这里最外层循环使用的原语parallel提示最外层 i 轴循环无依赖关系,调度时可以并行加速;而内层循环中使用的serial提示 j 和 k 的计算有依赖关系,调度时应保 j 和 k 从小的大的顺序。当我们把device_target设置为"Ascend"时,上面提示会送达调度器,实现手自一体的算子调度协助代码生成,有效的扩展了MindSpore在使用昇腾后端时的算子表达能力,助力昇腾后端应用于科学计算场景。未来,我们会把调度器进一步拓展到全后端,助力MindSpore扩展科学计算领域的生态。
2.2.2
支持pyfunc无缝切换,兼顾易调试和高性能
此外,基于ms_kernel开发的算子可以使能Python原生解释器运行,从而通过Custom提供pyfunc模式进行快速验证,实现性能与易用性的兼顾和平衡。例如上面的算子我们可以如下修改:
class Net(Cell):
def __init__(self):
super(Net, self).__init__()
# 使用Python解释器进行快速验证
self.cus_op =ops.Custom(hybrid_dsl_test, func_type="pyfunc")
def construct(self, x, y):
return self.cus_op(x, y)
即只用Custom内的模式改为pyfunc,便可以让用以上算子当做原生Python函数运行。如此,我们可以通过Python快速验证算法逻辑,也可以通过插入打印语句确认中间结果的正确性。
3
新起点
在MindSpore 1.8版本的全新升级之后,MindSpore统一自定义算子接口初步的完成适用场景的全覆盖的同时,发展出了自己的特色,特别是跨平台统一的ms_kernel模式和支持Julia语言接入。同时,这也是我们的一个新的起点。
一方面,回望我们出发的起点,基于深度学习场景的自定义算子开发中还有问题有待我们解决,包括:
-
基于自定义算子和MindSpore的图算融合特性的图算联合优化,让图层与算子进一步结合,从而实现图算软件分层带来的横向隔阂的彻底突破;
-
基于Custom自定义算子能力扩展更多领域的算子包,从而实现竖向隔阂的彻底突破。
另一方面,远眺我们的前进的方向,在面对AI+科学计算场景的挑战时,我们还需要进一步增强ms_kernel模式表达能力,特别是添加调度原语的同时完善调度器的全平台代码生成能力,助力MindSpore扩展科学计算领域的生态。我们也热切的希望希望更多的生态伙伴进行扩展和参与,从自定义算子出发,把MindSpore推向更多领域,为MindSpore生态添砖加瓦。