【论文笔记】张航和李沐等提出:ResNeSt: Split-Attention Networks(ResNet改进版本)
github地址:https://github.com/zhanghang1989/ResNeSt
论文地址:https://hangzhang.org/files/resnest.pdf
核心就是:Split-attention blocks
先看一组图:

ResNeSt在图像分类上中ImageNet数据集上超越了其前辈ResNet、ResNeXt、SENet以及EfficientNet。使用ResNeSt-50为基本骨架的Faster-RCNN比使用ResNet-50的mAP要高出3.08%。使用ResNeSt-50为基本骨架的DeeplabV3比使用ResNet-50的mIOU要高出3.02%。涨点效果非常明显。
1、提出的动机
他们认为像ResNet等一些基础卷积神经网络是针对于图像分类而设计的。由于有限的感受野大小以及缺乏跨通道之间的相互作用,这些网络可能不适合于其它的一些领域像目标检测、图像分割等。这意味着要提高给定计算机视觉任务的性能,需要“网络手术”来修改ResNet,以使其对特定任务更加有效。 例如,某些方法添加了金字塔模块[8,69]或引入了远程连接[56]或使用跨通道特征图注意力[15,65]。 虽然这些方法确实可以提高某些任务的学习性能,但由此而提出了一个问题:我们是否可以创建具有通用改进功能表示的通用骨干网,从而同时提高跨多个任务的性能?跨通道信息在下游应用中已被成功使用 [56,64,65],而最近的图像分类网络更多地关注组或深度卷积[27,28,54,60]。 尽管它们在分类任务中具有出色的计算能力和准确性,但是这些模型无法很好地转移到其他任务,因为它们的孤立表示无法捕获跨通道之间的关系[27、28]。因此,具有跨通道表示的网络是值得做的。
2、本文的贡献点
第一个贡献点:提出了split-attention blocks构造的ResNeSt,与现有的ResNet变体相比,不需要增加额外的计算量。而且ResNeSt可以作为其它任务的骨架。
第二个贡献点:图像分类和迁移学习应用的大规模基准。 利用ResNeSt主干的模型能够在几个任务上达到最先进的性能,即:图像分类,对象检测,实例分割和语义分割。 与通过神经架构搜索生成的最新CNN模型[55]相比,所提出的ResNeSt性能优于所有现有ResNet变体,并且具有相同的计算效率,甚至可以实现更好的速度精度折衷。单个Cascade-RCNN [3]使用ResNeSt-101主干的模型在MS-COCO实例分割上实现了48.3%的box mAP和41.56%的mask mAP。 单个DeepLabV3 [7]模型同样使用ResNeSt-101主干,在ADE20K场景分析验证集上的mIoU达到46.9%,比以前的最佳结果高出1%mIoU以上。
3、相关工作就不介绍了
4、Split-Attention网络
直接看ResNeSt block:

首先是借鉴了ResNeXt网络的思想,将输入分为K个,每一个记为Cardinal1-k ,然后又将每个Cardinal拆分成R个,每一个记为Split1-r,所以总共有G=KR个组。
然后是对于每一个Cardinal中具体是什么样的:
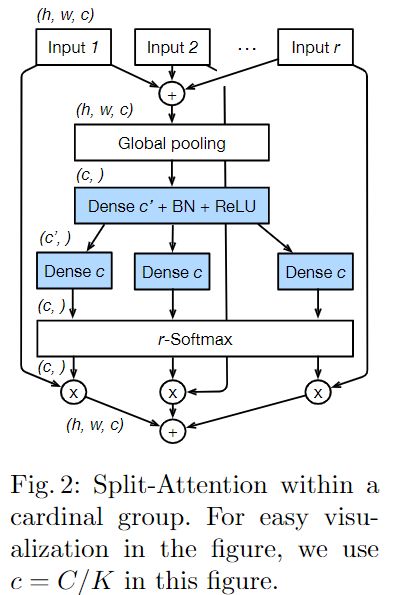
这里借鉴了squeeze-and-excitation network(SENet) 中的思想,也就是基于通道的注意力机制,对通道赋予不同的权重以建模通道的重要程度。
对于每一个Cardinal输入是:
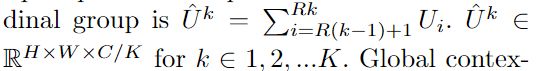
通道权重统计量可以通过全局平均池化获得:
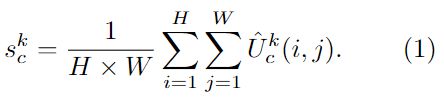
用Vk表示携带了通道权重后的Cardinal输出:![]()
那么最终每个Cardinal的输出就是:
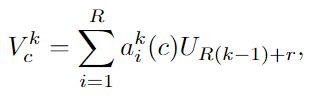
而其中的![]() 是经过了softmax之后计算所得的权重:
是经过了softmax之后计算所得的权重:
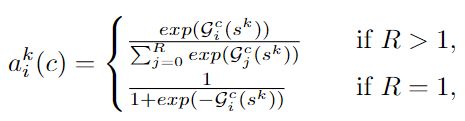
如果R=1的话就是对该Cardinal中的所有通道视为一个整体。
接着将每一个Cardinal的输出拼接起来:
![]()
假设每个ResNeSt block的输出是Y,那么就有:
![]()
其中T表示的是跳跃连接映射。这样的形式就和ResNet中的残差块输出计算就一致了。
5、残差网络存在的问题
(1)残差网络使用带步长的卷积,比如3×3卷积来减少图像的空间维度,这样会损失掉很多空间信息。对于像目标检测和分割领域,空间信息是至关重要的。而且卷积层一般使用0来填充图像边界,这在迁移到密集预测的其它问题时也不是最佳选择。因此本文使用的是核大小为3×3的平均池化来减少空间维度。
(2)
- 将残差网络中的7×7卷积用3个3×3的卷积代替,拥有同样的感受野。
- 将跳跃连接中的步长为2的1×1卷积用2×2的平均池化代替。
6、训练策略
这里就简单地列下,相关细节可以去看论文。
(1)大的min batch,使用cosine学习率衰减策略。warm up。BN层参数设置。
(2)标签平滑
(3)自动增强
(4)mixup训练
(5)大的切割设置
(6)正则化

6、相关结果
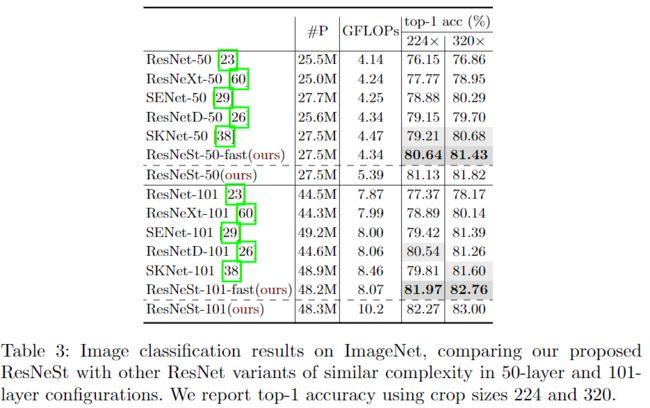

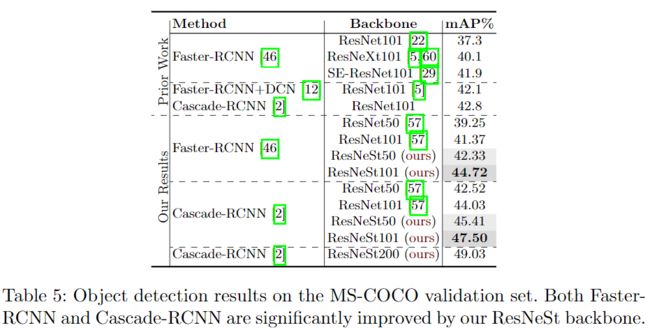

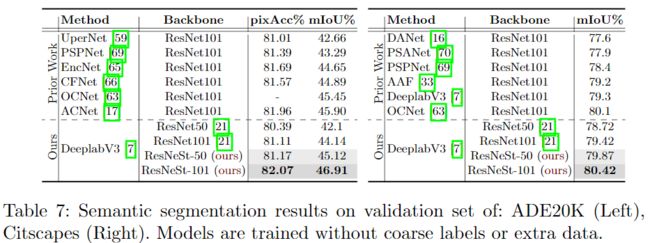
附录中还有一些结果,就不再贴了。
最后是split attention block的实现代码,可以结合看一看:
import torch from torch import nn import torch.nn.functional as F from torch.nn import Conv2d, Module, Linear, BatchNorm2d, ReLU from torch.nn.modules.utils import _pair __all__ = ['SKConv2d'] class DropBlock2D(object): def __init__(self, *args, **kwargs): raise NotImplementedError class SplAtConv2d(Module): """Split-Attention Conv2d """ def __init__(self, in_channels, channels, kernel_size, stride=(1, 1), padding=(0, 0), dilation=(1, 1), groups=1, bias=True, radix=2, reduction_factor=4, rectify=False, rectify_avg=False, norm_layer=None, dropblock_prob=0.0, **kwargs): super(SplAtConv2d, self).__init__() padding = _pair(padding) self.rectify = rectify and (padding[0] > 0 or padding[1] > 0) self.rectify_avg = rectify_avg inter_channels = max(in_channels*radix//reduction_factor, 32) self.radix = radix self.cardinality = groups self.channels = channels self.dropblock_prob = dropblock_prob if self.rectify: from rfconv import RFConv2d self.conv = RFConv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation, groups=groups*radix, bias=bias, average_mode=rectify_avg, **kwargs) else: self.conv = Conv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation, groups=groups*radix, bias=bias, **kwargs) self.use_bn = norm_layer is not None self.bn0 = norm_layer(channels*radix) self.relu = ReLU(inplace=True) self.fc1 = Conv2d(channels, inter_channels, 1, groups=self.cardinality) self.bn1 = norm_layer(inter_channels) self.fc2 = Conv2d(inter_channels, channels*radix, 1, groups=self.cardinality) if dropblock_prob > 0.0: self.dropblock = DropBlock2D(dropblock_prob, 3) def forward(self, x): x = self.conv(x) if self.use_bn: x = self.bn0(x) if self.dropblock_prob > 0.0: x = self.dropblock(x) x = self.relu(x) batch, channel = x.shape[:2] if self.radix > 1: splited = torch.split(x, channel//self.radix, dim=1) gap = sum(splited) else: gap = x gap = F.adaptive_avg_pool2d(gap, 1) gap = self.fc1(gap) if self.use_bn: gap = self.bn1(gap) gap = self.relu(gap) atten = self.fc2(gap).view((batch, self.radix, self.channels)) if self.radix > 1: atten = F.softmax(atten, dim=1).view(batch, -1, 1, 1) else: atten = F.sigmoid(atten, dim=1).view(batch, -1, 1, 1) if self.radix > 1: atten = torch.split(atten, channel//self.radix, dim=1) out = sum([att*split for (att, split) in zip(atten, splited)]) else: out = atten * x return out.contiguous()
如有错误,欢迎指出。