CNN卷积神经网络之AlexNet
CNN卷积神经网络之AlexNet
- 前言
- 网络结构
- 运用的方法
-
-
-
-
- 1.ReLU非线性单元激活函数
- 2.在多个GPU上训练
- 3.局部响应归一化
- 4.重叠池化
- 5.数据增强(防止过拟合)
- 6.Dropout(防止过拟合)
-
-
- 7.训练策略
- 8.初始化
-
- 代码
前言
《ImageNet Classification with Deep Convolutional Neural Networks》
作者:Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
地址:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
网络结构
ImageNet由可变分辨率的图像组成,而系统需要固定的输入尺寸。因此,将图像下采样到固定分辨率。给定一个矩形图像,首先重新缩放图像,使得短边长度为256,然后从结果中裁剪出中心的256×256的图片。除了将每个像素中减去训练集的像素均值之外,没有以任何其他方式对图像进行预处理。
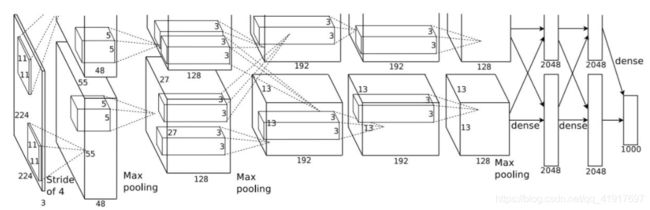
AlexNet结构:文中提出的CNN结构的插图,明确展示了两个GPU的职责。一个GPU执行图像上面部分层,另一个执行下面的分层。GPU只在部分层交互,网络输入为150528的空间,网络中剩余层的神经元数量为:253440, 186624, 64896, 64896, 43264,4096, 4096, 1000。
它包含八个层——五个卷积层和三个全连接层。
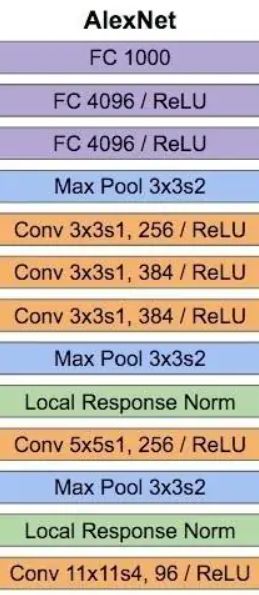
主要思路就是卷积+最大池化,最后全连接,全连接层中使用了Dropout,激活函数为ReLU(LRN层后来被证实没有什么作用)
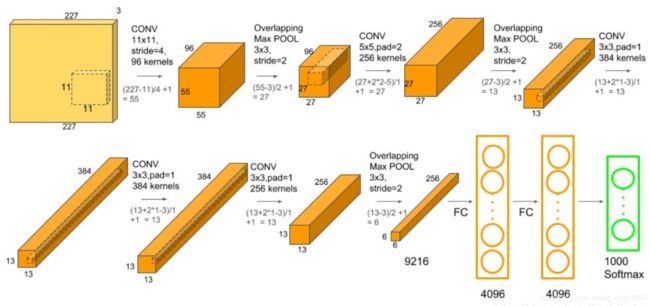
参数量:
C1: 96个11×11×3的卷积核,96×11×11×3+96=34848
C2: 256个5×5×48的卷积核,256×5×5×48+256=307456
C3: 384个3×3×256的卷积核,3×3×256×384+384=885120
C4: 384个3×3×192的卷积核,3×3×284×192+384=663936
C5: 256个3×3×192的卷积核,3×3×192×256+256=442624
FC6: 4096个6×6×256的卷积核,6×6×256×4096+4096=37752832
FC7: 4096∗4096+4096=16781312
output(FC8): 4096∗1000=4096000
合计:60965128个参数量
运用的方法
1.ReLU非线性单元激活函数
2.在多个GPU上训练
3.局部响应归一化
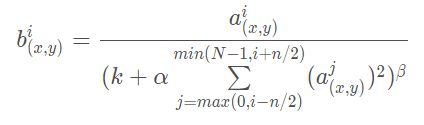
由于后来证实没有作用,故不深究了。
4.重叠池化
在传统方法中,相邻池化单元之间互不重叠。CNN中常用的传统的局部池化。
CNN中的重叠池化汇集了相同内核映射中相邻神经元组的输出,也就是说,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合。
5.数据增强(防止过拟合)
1)平移图像和水平映射:
从256×256图像中随机提取224×224的图像块(及其水平映射)。在测试时,网络通过提取5个224×224的图像块(四个角块和中心块)以及它们的水平映射(因此总共包括10个块)来进行预测,并求网络的softmax层的上的十个预测结果的均值。
2)改变训练图像中RGB通道的灰度:
在整个ImageNet训练集的图像的RGB像素值上使用PCA。对于每个训练图像,添加多个通过PCA找到的主成分,大小与相应的特征值成比例,乘以一个随机值,该随机值属于均值为0、标准差为0.1的高斯分布。这个方案近似地捕捉原始图像的一些重要属性,对象的身份不受光照的强度和颜色变化影响。
6.Dropout(防止过拟合)
前两个全连接层上使用了dropout,会以50%的概率将隐含层的神经元输出置为0。以这种方法被置0的神经元不参与网络的前馈和反向传播。
链接: Dropout.
7.训练策略
“我们使用随机梯度下降法来训练我们的模型,每个batch有128个样本,动量为0.9,权重衰减为0.0005。我们发现这种较小的权重衰减对于模型的训练很重要。换句话说,权重衰减在这里不仅仅是一个正则化方法:它减少了模型的训练误差。”即:
1)单样本—>mini-batch
2)SGD—>SGD + momentum
3)引入学习率下降的方法:
验证集上的错误率停止降低时,将学习速率除以10,并且在终止前减少3次
8.初始化
使用标准差为0.01、均值为0的高斯分布来初始化各层的权重。我们使用常数1来初始化了网络中的第2-5个卷积层以及全连接层中的隐含层中的所有偏置参数。这种初始化权重的方法通过向ReLU提供了正的输入,来加速前期的训练。我们使用常数0来初始化剩余层的偏置参数。
代码
由于最近事情较多,就不自己写了,以后有空自己再重写一份。实际上Pytorch使用的AlexNet模型相较于论文来说十分简单,并且dropout的位置以及一些池化方法也和论文本身的描述并不相同,但是作为参考来说是非常够用了,可以打开源码瞅一眼。
链接: 复现的pytorch代码来自这里.
网络结构:
import torch
import torch.nn as nn
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu") #指定运行设备,因为这个模型还是挺大的,所以CPU上会非——常——慢,建议放在GPU上跑
class LRN(nn.Module):
def __init__(self, in_channels: int, k=2, n=5, alpha=1.0e-4, beta=0.75):
#把所有用的到的参数进行赋值,参数名和论文里面是基本一致的
super(LRN, self).__init__()
self.in_channels = in_channels #特征图的通道数,就是论文里面的N,这里是为了让参数含义比较易读所以写的这个
self.k = k
self.n = n
self.alpha = alpha
self.beta = beta
def forward(self, x):
tmp = x.pow(2)
div = torch.zeros(tmp.size()).to(device) #这里必须要放到指定的device上,这是因为其他的tensor都是在device上,如果放到device上的话,会导致div和其他的tensor在不同的device上,无法运算,程序会在下面计算out = x / ...的位置报错
for batch in range(tmp.size(0)):
for channel in range(tmp.size(1)):
st = max(0, channel - self.n // 2) #这里必须要用‘//’而不是‘int(a/b)’的形式,这是因为在Pytorch中即使使用了int进行强转,也会发生实际类型是float而不是int的问题
ed = min(channel + self.n // 2, tmp.size(1)-1)+1
div[batch, channel] = tmp[batch, st:ed].sum(dim=0) #切片操作
out = x / (self.k + self.alpha * div).pow(self.beta)
return out
class AlexNet(nn.Module):
def __init__(self, nclass): #nclass:用于确定最终的分类问题的分类数
super(AlexNet, self).__init__()
#为了不写那么多的ReLU、MaxPool2d以及Dropout,就在这里复用一下代码好了
self.act = nn.ReLU(True)
self.pool = nn.MaxPool2d(kernel_size=3, stride=2)
self.dropout = nn.Dropout(0.5)
self.C1 = nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2)
self.C1.bias.data = torch.zeros(self.C1.bias.data.size()) #对偏置的初始化,已经在上面说得很清楚了
self.N1 = LRN(96)
self.C2 = nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2)
self.C2.bias.data = torch.ones(self.C2.bias.data.size())
self.N2 = LRN(256)
self.C3 = nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1)
self.C3.bias.data = torch.zeros(self.C3.bias.data.size())
self.C4 = nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1)
self.C4.bias.data = torch.ones(self.C4.bias.data.size())
self.C5 = nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1)
self.C5.bias.data = torch.ones(self.C5.bias.data.size())
self.F1 = nn.Linear(256*6*6, 4096)
self.F2 = nn.Linear(4096, 4096)
self.F3 = nn.Linear(4096, nclass)
for m in self.modules(): #权重以及线性层偏置初始化
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
m.weight.data = torch.normal(torch.zeros(m.weight.data.size()), torch.ones(m.weight.data.size()) * 0.01) #N(0, 0.01^2), 具体函数说明在C1层中已经说明
if isinstance(m, nn.Linear):
m.bias.data = torch.ones(m.bias.data.size())
def forward(self, x):
x = self.pool(self.N1(self.act(self.C1(x))))
x = self.pool(self.N2(self.act(self.C2(x))))
x = self.act(self.C3(x))
x = self.act(self.C4(x))
x = self.pool(self.act(self.C5(x)))
x = x.view(-1, 256*6*6)
x = self.dropout(self.act(self.F1(x)))
x = self.dropout(self.act(self.F2(x)))
x = self.act(self.F3(x))
return x
训练部分:
import torch
import torch.nn as nn
from torchvision import transforms as T
from torchvision import datasets
import torch.optim as optim
from torch.utils.data import DataLoader
from AlexNet import AlexNet, device
picProcessor = T.Compose([
T.Resize(224),
T.ToTensor(),
T.Normalize(
mean = [0.4915, 0.4823, 0.4468], #这个是cifar-10的均值均值可以google或者看一下《Deep Learning with Pytorch》这本书,实在不行自己算也行。ImageNet的均值也是可以google一下找到的
std=[1.0, 1.0, 1.0] #论文提到不用对标准差进行处理,所以这里就写1.0就行啦
)
])
def train(epochs, model, optimizer, loss_fn, scheduler, trainSet, testSet):
lossList = []
testAcc = []
for epoch in range(epochs):
lossSum = 0.0
print("epoch:{:d}/{:d}".format(epoch, epochs)) #老规矩,看一下模型是不是在跑
model.train()
for idx, (img, label) in enumerate(trainSet):
img = img.to(device)
label = label.to(device)
optimizer.zero_grad()
out = model(img)
loss = loss_fn(out, label)
loss.backward()
optimizer.step()
lossSum += loss.item()
if (idx+1) % 10 == 0: print("batch:{:d}/{:d} --> loss:{:.4f}".format(idx+1, len(trainSet), loss.item()))
#print("batch:{:d}/{:d} --> loss:{:.6f}".format(idx+1, len(trainSet), loss.item())) #如果10个batch显示一次有一点慢,就用这个句子,每个batch都显示一下
model.eval() #这里必须有这个句子,由于把dropout中的一些参数锁死
accNum = 0
testNum = 0
with torch.no_grad():
for idx, (img, label) in enumerate(testSet):
testNum += label.shape[0]
img = img.to(device)
label = label.to(device)
out = model(img)
preds = out.argmax(dim=1)
accNum += int((preds == label).sum())
testAcc.append(accNum / testNum)
if scheduler is not None:
scheduler.step(accNum / testNum) #这个就是之前提到的step啦
torch.save(model.state_dict(), 'F:\\Code_Set\\Python\\PaperExp\\AlexNet\\Models\\epoch-{:d}_loss-{:.6f}_acc-{:.2%}.pth'.format(epochs, lossList[-1], testAcc[-1])) #所有对应路径上的文件夹必须存在,否则会报错,torch.save是不会给你自动创建文件夹的。你也不希望训练了半天结果保存不成功报错了吧
if __name__ == "__main__":
model = AlexNet(10).to(device) #cifar-10就只有10个分类,所以这里nclass给的是10
#将整个数据集进行读取和预处理
path = "F:\\Code_Set\\Python\\DLLearing\\cifar10-dataset\\" #根据自己的实际数据集进行定位
cifar10_train = datasets.CIFAR10(path, train=True, download=False, transform=picProcessor) #第一次使用记得把download设置为True
cifar10_test = datasets.CIFAR10(path, train = False, download = False, transform=picProcessor)
trainSet = DataLoader(cifar10_train, batch_size=128, shuffle=True) #如果电脑的显卡不是太好,最好把batch_size调整为64或者32,实在不行就调成16
testSet = DataLoader(cifar10_test, batch_size=128, shuffle=True)
epochs = 10 #ImageNet是训练了90多个epoch,但是cifar-10没必要
optimizer = optim.SGD(model.parameters(), lr=1.0e-2, momentum=0.9, weight_decay=5.0e-4) #实际运行cifar-10的时候,lr=1.0e-4, 否则会发生梯度爆炸以及全部神经元死亡的问题,导致loss下降到2.3附近的时候停止下降,这个参数记得调啊
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.1, patience=1)
loss_fn = nn.CrossEntropyLoss()
train(epochs, model, optimizer, loss_fn, scheduler, trainSet, testSet)
以上内容,仅代表个人学习到的,希望有不同观点的朋友可以交流,如有错误,请指正。
下一篇:CNN卷积神经网络之ZFNet与OverFeat.