UNet语义分割网络
1、本文参考
[炼丹术]UNet图像分割模型相关总结_animalslin的技术博客_51CTO博客
https://cuijiahua.com/blog/2019/11/dl-14.html
Pytorch 深度学习实战教程(二):UNet语义分割网络 - 腾讯云开发者社区-腾讯云
2、UNet网络介绍
UNet网络用于语义分割。
语义就是给图像上目标类别中的每一点打一个标签,使得不同种类的东西在图像上被区分开来。可以理解成像素级别的分类任务,即对每个像素点进行分类。
假如存在五类:Person(人)、Purse(包)、Plants/Grass(植物/草)、Sidewalk(人行道)、Building/Structures(建筑物)。需要创建一个one-hot编码的目标类别标注,即为每个类别创建一个输出通道。因为有5个类别,所以网络输出的通道数也为5,如下图所示:
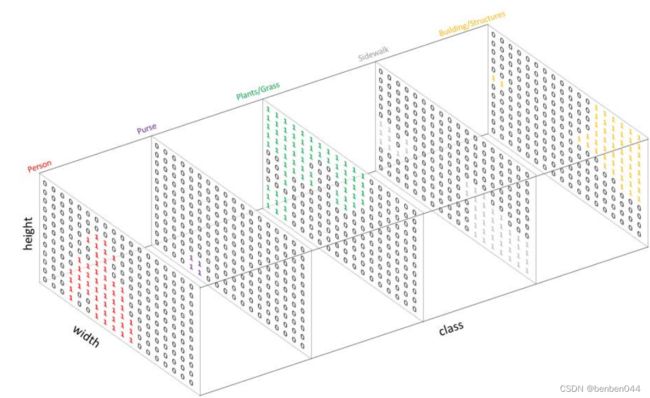
因为不存在同一个像素点在两个以上的通道均为1的情况(存疑),所以预测的结果可以通过对每个像素在深度上求argmax的方式被整合到一张分割图中,进而可以通过重叠的方式观察到每个目标。
UNet网络的架构如下(实际实施时思想不变,但是略有调整):
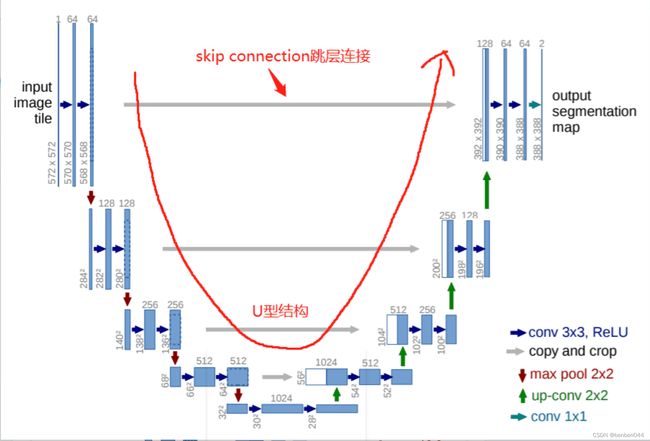
3、UNet训练整体方案
(1)通过labelme进行语义标注,产出结果json文件
(2)编写代码,根据json文件的points信息,从原图中获取mask图片
(3)在UNet网络中,输入3通道图片,输出预测的1通道mask(假定只有一个识别类别),将预测的mask和实际的mask计算BCELoss从而进行拟合操作,并且输出准确率和dice score的监控指标
4、UNet网络实施分析
(1)labelme进行多边形标注
标注完成后,会在图片所在目录下生成json文件。
(2)根据json文件生成mask图片
文件名:json2mask.py
import os
import cv2
import numpy as np
from PIL import Image, ImageDraw
import json
CLASS_NAMES = ['dog', 'cat']
def make_mask(image_dir, save_dir):
data = os.listdir(image_dir)
temp_data = []
for i in data:
if i.split('.')[1] == 'json':
temp_data.append(i)
else:
continue
for js in temp_data:
json_data = json.load(open(os.path.join(image_dir, js), 'r'))
shapes_ = json_data['shapes']
mask = Image.new('P', Image.open(os.path.join(image_dir, js.replace('json', 'jpg'))).size)
for shape_ in shapes_:
label = shape_['label']
points = shape_['points']
points = tuple(tuple(i) for i in points)
mask_draw = ImageDraw.Draw(mask) # 类似于函数声明
mask_draw.polygon(points, fill=CLASS_NAMES.index(label) + 1)
mask = np.array(mask) * 255
cv2.imshow('mask', mask)
cv2.waitKey(0)
cv2.imwrite(os.path.join(save_dir, js.replace('json', 'jpg')), mask)
def vis_label(img):
img = Image.open(img)
img = np.array(img)
print(set(img.reshape(-1).tolist()))
if __name__ == '__main__':
make_mask('D:\\ai_data\\cat\\val', 'D:\\ai_data\\cat\\val_mask')
说明:
- Image.new中mode='P',代表生成的图片为8-bit pixels,适合用于生成mask图片
- 像素值=255表示白色,也就是说mask图片中mask部分为白色,非mask部分为黑色。实际得到的mask图片中mask会存在(249,255)的值,使用时需要再处理下。
(3)UNet网络构造
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=0),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=0),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is NCHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512, bilinear)
self.up2 = Up(512, 256, bilinear)
self.up3 = Up(256, 128, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
if __name__ == '__main__':
net = UNet(n_channels=3, n_classes=1)
print(net)
x = torch.randn([1, 3, 572, 572])
out = net(x)
print(out.shape)说明:
- 本代码为按照UNet论文构造的网络,实际中并未使用该代码,需要稍作修改
- 本代码适合阅读UNet网络,不明白之处可参考:Pytorch 深度学习实战教程(二):UNet语义分割网络 - 腾讯云开发者社区-腾讯云
- 下采样通过卷积核最大池化完成
- 上采样通过转置卷积以及和下采样的特征concat完成。
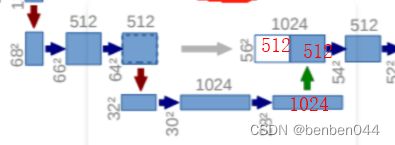 上采样是会将通道维度减少一半,比如1024到512,因为和下采样的特征(同样也是512)在dim=1(channel维度)进行了concat,所以channel维度的值又变为了1024.
上采样是会将通道维度减少一半,比如1024到512,因为和下采样的特征(同样也是512)在dim=1(channel维度)进行了concat,所以channel维度的值又变为了1024.- 论文的输入w、h和输出的w‘、h’大小不一样,在mask图片比对时会有问题,所以我们希望输入和输出的wh保持一致。此时会设置padding=1,这样double_conv时候w、h会保持不变,只有池化时变为原来的一半,上采样时候又会变为原来的两倍。
- 以上代码只作为了解UNet网络使用,不作为整个工程的代码。
(4)主函数train.py
import torch
import albumentations as A
from albumentations.pytorch import ToTensorV2
from tqdm import tqdm
import torch.nn as nn
import torch.optim as optim
from model import UNET
# from unet_model_new import UNet
from utils import (
load_checkpoint,
save_checkpoint,
get_loaders,
check_accuracy,
save_predictions_as_imgs,
)
# 超参
learning_rate = 1e-4
device = 'cpu'
batch_size = 1
num_epochs = 30
num_workers = 0
image_height = 160
image_width = 240
pin_memory = False
load_model = False
train_img_dir = "D:\\ai_data\\cat\\train2"
train_mask_dir = "D:\\ai_data\\cat\\train2_mask"
val_img_dir = "D:\\ai_data\\cat\\val2"
val_mask_dir = "D:\\ai_data\\cat\\val2_mask"
def train_fn(loader, model, optimizer, loss_fn):
for batch_idx, (data, targets) in enumerate(tqdm(loader)):
data = data.to(device=device)
targets = targets.float().unsqueeze(1).to(device=device)
predictions = model(data)
loss = loss_fn(predictions, targets)
optimizer.zero_grad()
loss.backward()
def main():
train_transform = A.Compose(
[
A.Resize(height=image_height, width=image_width),
A.Rotate(limit=35, p=1.0),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.1),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0
),
ToTensorV2(),
],
)
val_transform = A.Compose(
[
A.Resize(height=image_height, width=image_width),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0
),
ToTensorV2(),
],
)
model = UNET(in_channels=3, out_channels=1).to(device)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
train_loader, val_loader = get_loaders(
train_img_dir,
train_mask_dir,
val_img_dir,
val_mask_dir,
batch_size,
train_transform,
val_transform,
num_workers,
pin_memory
)
if load_model:
load_checkpoint(torch.load("my_checkpoint.pth.tar"), model)
check_accuracy(-1, "val", val_loader, model, device=device)
for epoch in range(num_epochs):
train_fn(train_loader, model, optimizer, loss_fn)
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
save_checkpoint(checkpoint)
check_accuracy(epoch, "train", train_loader, model, device=device)
check_accuracy(epoch, "val", val_loader, model, device=device)
save_predictions_as_imgs(val_loader, model, folder="saved_images/", device=device)
if __name__ == "__main__":
main()
(5)数据加载dataset.py
import os
from PIL import Image
from torch.utils.data import Dataset
import numpy as np
class CarvanaDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.images[index])
mask_path = os.path.join(self.mask_dir, self.images[index].replace(".jpg", "_mask.jpg"))
image = np.array(Image.open(img_path).convert("RGB"))
mask = np.array(Image.open(mask_path).convert("L"), dtype=np.float32)
mask[mask > 200.0] = 1.0 # 转换为灰度图后并非全是255白色
if self.transform is not None:
augmentations = self.transform(image=image, mask=mask)
image = augmentations["image"]
mask = augmentations["mask"]
return image, mask(6)模型model.py
import torch
import torch.nn as nn
import torch.functional as F
import torchvision.transforms.functional as TF
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1, bias=False), # padding=1,保证conv2d的输出hw保持不变
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False), # padding=1,保证conv2d的输出hw保持不变
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.conv(x)
class UNET(nn.Module):
def __init__(
self, in_channels=3, out_channels=1, features=[64, 128, 256, 512],
):
super(UNET, self).__init__()
self.ups = nn.ModuleList()
self.downs = nn.ModuleList()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# Down part of UNET
for feature in features:
self.downs.append(DoubleConv(in_channels, feature))
in_channels = feature
# Up part of UNET
for feature in reversed(features):
self.ups.append(
nn.ConvTranspose2d(
feature*2, feature, kernel_size=2, stride=2,
)
)
self.ups.append(DoubleConv(feature*2, feature))
self.bottleneck = DoubleConv(features[-1], features[-1]*2)
self.final_conv = nn.Conv2d(features[0], out_channels, kernel_size=1)
def forward(self, x):
skip_connections = []
for down in self.downs:
x = down(x)
skip_connections.append(x)
x = self.pool(x)
x = self.bottleneck(x)
skip_connections = skip_connections[::-1]
for idx in range(0, len(self.ups), 2):
x = self.ups[idx](x)
skip_connection = skip_connections[idx//2]
if x.shape != skip_connection.shape:
x = TF.resize(x, size=skip_connection.shape[2:]) # 因为有padding=1,所以到不了这一步
# diffY = torch.tensor([skip_connection.size()[2] - x.size()[2]])
# diffX = torch.tensor([skip_connection.size()[3] - x.size()[3]])
# x = F.pad(x, [diffX // 2, diffX - diffX // 2,
# diffY // 2, diffY - diffY // 2])
concat_skip = torch.cat((skip_connection, x), dim=1)
x = self.ups[idx+1](concat_skip)
return self.final_conv(x)
def test():
x = torch.randn((3, 1, 572, 572))
model = UNET(in_channels=1, out_channels=1)
preds = model(x)
assert preds.shape == x.shape
if __name__ == "__main__":
test()(7)工具utils.py
import torch
import torchvision
from dataset import CarvanaDataset
from torch.utils.data import DataLoader
def save_checkpoint(state, filename="my_checkpoint.pth.tar"):
print("=> Saving checkpoint")
torch.save(state, filename)
def load_checkpoint(checkpoint, model):
print("=> Loading checkpoint")
model.load_state_dict(checkpoint["state_dict"])
def get_loaders(
train_dir,
train_maskdir,
val_dir,
val_maskdir,
batch_size,
train_transform,
val_transform,
num_workers=4,
pin_memory=True,
):
train_ds = CarvanaDataset(
image_dir=train_dir,
mask_dir=train_maskdir,
transform=train_transform,
)
train_loader = DataLoader(
train_ds,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=pin_memory,
shuffle=True,
)
val_ds = CarvanaDataset(
image_dir=val_dir,
mask_dir=val_maskdir,
transform=val_transform,
)
val_loader = DataLoader(
val_ds,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=pin_memory,
shuffle=False,
)
return train_loader, val_loader
def check_accuracy(epoch, attr, loader, model, device="cuda"):
num_correct = 0
num_pixels = 0
dice_score = 0
model.eval()
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device).unsqueeze(1)
preds = torch.sigmoid(model(x))
preds = (preds > 0.5).float()
num_correct += (preds == y).sum()
num_pixels += torch.numel(preds)
dice_score += (2 * (preds * y).sum()) / (
(preds + y).sum() + 1e-8
)
print(f"{attr}_{epoch+1}: Got {num_correct}/{num_pixels} with acc {num_correct/num_pixels*100:.2f}")
print(f"{attr}_{epoch+1}: Dice score: {dice_score/len(loader)}")
model.train()
def save_predictions_as_imgs(
loader, model, folder="saved_images/", device="cuda"
):
model.eval()
for idx, (x, y) in enumerate(loader):
x = x.to(device=device)
with torch.no_grad():
preds = torch.sigmoid(model(x))
preds = (preds > 0.5).float()
torchvision.utils.save_image(
preds, f"{folder}/pred_{idx}.png"
)
torchvision.utils.save_image(y.unsqueeze(1), f"{folder}{idx}.png")
model.train()(8)监控指标dice score说明
参考文档:关于图像分割的评价指标dice_Pierce_KK的博客-CSDN博客_dice评价指标
dice指标也用在机器学习中,它的表达式为:

这与机器学习中的评价指标F1是相同的。
准确率指标:
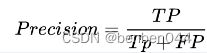
召回率指标:

F1则是基于准确率和召回率的调和平均值,即:
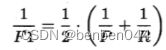
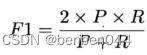
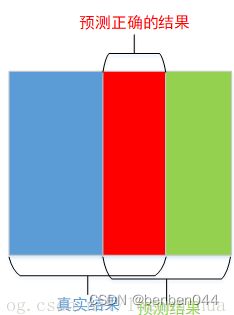
dice指标是医学图像中的常见指标,常用于评价图像分割算法的好坏。从公式上来做直观的理解,如下图所示,其代表的是两个体相交的面积占总面积的比值,完美分割该值为1.
本试验中,准确率能够达到60%+,disc score只有0.4+,整体效果不佳。


5、 UNet后续发展
(1)UNet网络的思想:
- 下采样+上采样作为整体的网络结构(Encoder-Decoder)
- 多尺度的特征融合
- 信息流通的方式
- 获得像素级别的segment map
(2)对于改进UNet的见解,参考:谈一谈UNet图像分割_3D视觉工坊的博客-CSDN博客
很多人都喜欢在UNet进行改进,换个优秀的编码器,然后自己在手动把解码器对应实现一下。执御为什么选择UNet上进行改进,可能是因为UNet网络的结构比较简单,而且UNet的效果在很多场景下的表现可能都是差强人意的。
UNet最原始的设计思路,相对于后面系列的一个劣势就是:信息融合、位置不偏移。