常见损失函数的比较
转载:https://blog.csdn.net/lwc5411117/article/details/84885427
1. 综述
损失函数(Loss Function)是用来评估模型好坏程度,即预测值f(x)与真实值的不一致程度,通常表示为L(Y, f(x))的一个非负的浮点数。比如你要做一个线性回归,你拟合出来的曲线不会和原始的数据分布是完全吻合(完全吻合的话,很可能会出现过拟合的情况),这个差距就是用损失函数来衡量。那么损失函数的值越小,模型的鲁棒性也就越好,对新数据的预测能力也就越强。
通常提到损失函数,我们不得不提到代价函数(Cost Function)及目标函数(Object Function)。
损失函数(Loss Function) 直接作用于单个样本,用来表达样本的误差
代价函数(Cost Function)作用于整个训练集,是整个样本集的平均误差,对所有损失函数值的平均
目标函数(Object Function)是我们最终要优化的函数,也就是代价函数+正则化函数(经验风险+结构风险)
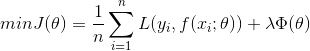
其中,第一部分是代价函数,L代表损失函数;第二部分是正则化函数(也可以称为惩罚项),可以试L1,也可以试L2或者其他正则函数。整个表达式是要找到是目标函数最好的值。
2. 损失函数
0-1损失函数(0-1 Loss Function)主要用于感知机
平方损失函数(Quadratic Loss Function)主要用于最小二乘法(OLS)
绝对值损失函数(Absolute Loss Function)
对数损失函数(Logarithmic Loss Function,Cross Entropy Loss Function, Softmax Loss Loss Function)主要用于Logistic回归与Softmax分类
指数损失函数(Exponential Loss Function)主要用于Adaboost集成学习算法
铰链损失函数(Hinge Loss Function)主要用于支持向量机(SVM)
2.1 0-1损失函数(0-1 Loss Function)
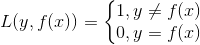
当预测错误时,损失函数结果为1;当预测正确时,损失函数为0。该预测并不考虑具体的误差程度,直接进行二值化。
优点:稳定的分类面,不连续,所以不可导,但是次梯度可导
缺点:二阶不可导,有时候不存在唯一解
2.2 平方损失函数(Quadratic Loss Function)
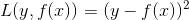
预测值与实际值的差的平方。
优点:容易优化(一阶导数连续)
缺点:对outlier点敏感,得不到最优的分类面
2.3 绝对值损失函数(Absolute Loss Function)
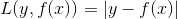
与平方损失函数类似,去实际值与测试值的差值的绝对值,但是不会被放大。
2.4 对数损失函数(Logarithmic Loss Function)
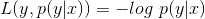
对数损失函数用到了极大似然估计的思想。P(Y|X)表示在当前模型上,样本X的预测值为Y的概率,也就是说对于样本X预测正确的概率。由于统计极大似然估计用到概率乘法,为了将其转为假发,对其取对数即可方便展开为加法;由于是损失函数,预测正确的概率应该与损失值成反比,这里对概率取反得到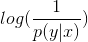 ,转化一下可以得到
,转化一下可以得到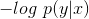 。
。
优点:稳定的分类面,严格凸,且二阶导数连续。
2.5 指数损失函数(Exponential Loss Function)
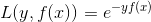
学过Adaboost的知道它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。
2.6 铰链损失函数(Hinge Loss Function)
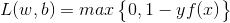 ,其中
,其中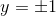 ,
,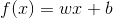
Hinge Loss function 一般在分类算法使用的分类函数,尤其使用于SVM。
优点:稳定的分类面,凸函数。可以极大化分类间隔。
3. 代价函数
3.1 均方误差(Mean Square Error)
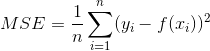
均方误差是指参数估计值与参数真值之差平方的期望值,MSE用来评估模型的好坏程度,MSE越小说明预测模型精确度越高。
通常用来做回归问题的代价函数。
3.2 均方根误差(Root Mean Square Error)
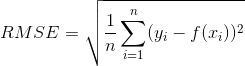
均方根误差是均方的算术平方根,能够直观的观察预测值与真实值直接的差距。
通常用来作为回归算法的性能指标。
3.3 平均绝对误差(Mean Absolute Error)
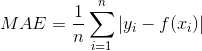
平均误差是绝对误差的平均值,平均绝对误差能更好的反应预测值与实际值的实际误差情况。
通常用来作为回归算法的性能指标。
3.4 交叉熵代价函数(Cross Entry)
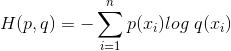
其中p(x)是真实分布的概率,q(x)是模型通过数据计算出来的概率估计。
交叉熵是用来评估当前训练得到的概率分布于真实分布的差异情况,减少交叉熵损失就是在提高模型的预测的准确率。
通常用来作为分类问题的代价函数。
4. 正则化
4.1 L1正则化
L1正则化假设模型的先验概率分布服从拉普拉斯分布;
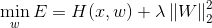
--求解略复杂;
--能够得到稀疏解
4.2 L2正则化
L2正则化假设模型的先验概率分布服从高斯分布;
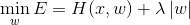
--简单有效
--便于求解
-- 最常用
5. 选择好的损失函数
什么样的损失函数时好的损失函数,那么多的损失函数,有没有一定的选择准则?
还是需要考虑你的具体要解决的问题及样本情况。可以简单遵循几个准则:
- L梯度需要有界,鲁棒性要有保障
- 将L1作为L的渐近线,稳定的分类边界
- 大分类间隔,保证泛化能力
- 选择正确的正则化方法(一般选择L2)
6. 参考文献
[1] https://www.cnblogs.com/lliuye/p/9549881.html
[2] https://blog.csdn.net/leo_xu06/article/details/79010218
[3] https://blog.csdn.net/weixin_37136725/article/details/79291818