Datawhale组队学习21期_学术前沿趋势分析Task1_论文数据统计
Task1_论文数据统计
前期准备:
.ipynb与.py
ipynb,即ipython notebook,需要用ipython notebook(现又称:Jupyter Notebook,是一个交互式笔记本,支持运行 40 多种编程语言 )打开,IPython Notebook是web based IPython封装,但是可以展现富文本,使得整个工作可以以笔记的形式展现、存储,对于交互编程、学习非常方便,在jupyter下的File—>Download as —>python(.py)可以将.ipynb转化为.py文件。
遇到的问题:pip install报错 ModuleNotFoundError: No module named ‘pip’(本应是在cmd窗口直接pip就行)

百度解决方案: 首先执行python -m ensurepip
然后执行 python -m pip install --upgrade pip 即可更新完毕
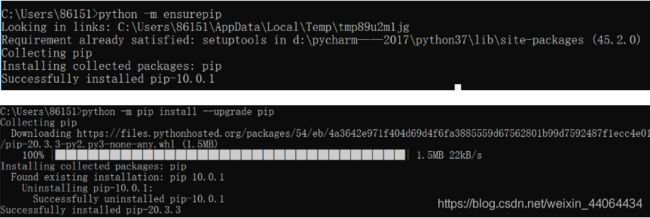
pip常用命令
python -m pip install --upgrade pip 将pip升级到最新版
pip list --outdated 查看有新版本的第三方库
pip install --upgrade 要升级的包名
pip uninstall 要卸载的包名
安装package:
画图:seaborn和matplotlib
爬虫:BeautifualSoup4和requests(注意,包名是beautifulsoup4,如果不加上 4,会是老版本也就是 bs3,它是为了兼容性而存在,目前已不推荐)
数据处理,读取数据:json和pandas
字符串匹配:re
建立模型:sklearn
复杂网络数据分析:networkx
安装方法: cmd 命令窗口 pip install 【packagename】
小白新知:json是python标准库不用安装
json: JSON(Java Script Object Notation):一种轻量级数据交互格式,相对于XML而言更简单,也易于阅读和编写,机器也方便解析和生成,Json是JavaScript中的一个子集。
相关概念: 序列化(Serialization):将对象的状态信息转换为可以存储或可以通过网络传输的过程,传输的格式可以是JSON,XML等。反序列化就是从存储区域(JSON,XML)读取反序列化对象的状态,重新创建该对象。python2.6版本开始加入了JSON模块,python的json模块序列化与反序列化的过程分别是encoding和decoding。
encoding:把一个python对象编码转换成Json字符串。
decoding:把json格式字符串编码转换成python对象。
json小览
site-package下查看引入的包

导入package并读取原始数据
# 导入所需的package
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #用于爬取arxiv的数据
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应信息
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import matplotlib.pyplot as plt #画图工具# 读入数据
data = [] #初始化
#使用with语句优势:1.自动关闭文件句柄;2.自动显示(处理)文件读取数据异常
with open("D:\\arxiv-metadata-oai-2019.json\\arxiv-metadata-oai-2019.json", 'r') as f:
for line in f:
data.append(json.loads(line))
data = pd.DataFrame(data) #将list变为dataframe格式,方便使用pandas进行分析
data.shape #显示数据大小(170618, 14)
data.head() #显示数据的前五行| id | submitter | authors | title | comments | journal-ref | doi | report-no | categories | license | abstract | versions | update_date | authors_parsed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0704.0297 | Sung-Chul Yoon | Sung-Chul Yoon, Philipp Podsiadlowski and Step... | Remnant evolution after a carbon-oxygen white ... | 15 pages, 15 figures, 3 tables, submitted to M... | None | 10.1111/j.1365-2966.2007.12161.x | None | astro-ph | None | We systematically explore the evolution of t... | [{'version': 'v1', 'created': 'Tue, 3 Apr 2007... | 2019-08-19 | [[Yoon, Sung-Chul, ], [Podsiadlowski, Philipp,... |
| 1 | 0704.0342 | Patrice Ntumba Pungu | B. Dugmore and PP. Ntumba | Cofibrations in the Category of Frolicher Spac... | 27 pages | None | None | None | math.AT | None | Cofibrations are defined in the category of ... | [{'version': 'v1', 'created': 'Tue, 3 Apr 2007... | 2019-08-19 | [[Dugmore, B., ], [Ntumba, PP., ]] |
| 2 | 0704.0360 | Zaqarashvili | T.V. Zaqarashvili and K Murawski | Torsional oscillations of longitudinally inhom... | 6 pages, 3 figures, accepted in A&A | None | 10.1051/0004-6361:20077246 | None | astro-ph | None | We explore the effect of an inhomogeneous ma... | [{'version': 'v1', 'created': 'Tue, 3 Apr 2007... | 2019-08-19 | [[Zaqarashvili, T. V., ], [Murawski, K, ]] |
| 3 | 0704.0525 | Sezgin Ayg\"un | Sezgin Aygun, Ismail Tarhan, Husnu Baysal | On the Energy-Momentum Problem in Static Einst... | This submission has been withdrawn by arXiv ad... | Chin.Phys.Lett.24:355-358,2007 | 10.1088/0256-307X/24/2/015 | None | gr-qc | None | This paper has been removed by arXiv adminis... | [{'version': 'v1', 'created': 'Wed, 4 Apr 2007... | 2019-10-21 | [[Aygun, Sezgin, ], [Tarhan, Ismail, ], [Baysa... |
| 4 | 0704.0535 | Antonio Pipino | Antonio Pipino (1,3), Thomas H. Puzia (2,4), a... | The Formation of Globular Cluster Systems in M... | 32 pages (referee format), 9 figures, ApJ acce... | Astrophys.J.665:295-305,2007 | 10.1086/519546 | None | astro-ph | None | The most massive elliptical galaxies show a ... | [{'version': 'v1', 'created': 'Wed, 4 Apr 2007... | 2019-08-19 | [[Pipino, Antonio, ], [Puzia, Thomas H., ], [M... |
1.4.2 数据预处理
data["categories"].describe()count 170618
unique 15592
top cs.CV
freq 5559
Name: categories, dtype: object
data["categories"].head()0 astro-ph
1 math.AT
2 astro-ph
3 gr-qc
4 astro-ph
Name: categories, dtype: object
以上的结果表明:共有170618个数据,有15592个子类(因为有论文的类别是多个,例如一篇paper的类别是CS.AI & CS.MM和一篇paper的类别是CS.AI & CS.OS属于不同的子类别,这里仅仅是粗略统计),其中最多的种类是cs.CV,共出现了 5559次。
由于部分论文的类别不止一种,所以下面我们判断在本数据集中共出现了多少种独立的数据集。
# 所有的种类(独立的)
unique_categories = set([i for l in [x.split(' ') for x in data["categories"]] for i in l])
len(unique_categories)172
unique_categories{'acc-phys',
'adap-org',
'alg-geom',
'astro-ph',
'astro-ph.CO',
'astro-ph.EP',
'astro-ph.GA',
'astro-ph.HE',
'astro-ph.IM',
'astro-ph.SR',
'chao-dyn',
'chem-ph',
'cmp-lg',
'comp-gas',
'cond-mat',
'cond-mat.dis-nn',
'cond-mat.mes-hall',
'cond-mat.mtrl-sci',
'cond-mat.other',
'cond-mat.quant-gas',
'cond-mat.soft',
'cond-mat.stat-mech',
'cond-mat.str-el',
'cond-mat.supr-con',
'cs.AI',
'cs.AR',
'cs.CC',
'cs.CE',
'cs.CG',
'cs.CL',
'cs.CR',
'cs.CV',
'cs.CY',
'cs.DB',
'cs.DC',
'cs.DL',
'cs.DM',
'cs.DS',
'cs.ET',
'cs.FL',
'cs.GL',
'cs.GR',
'cs.GT',
'cs.HC',
'cs.IR',
'cs.IT',
'cs.LG',
'cs.LO',
'cs.MA',
'cs.MM',
'cs.MS',
'cs.NA',
'cs.NE',
'cs.NI',
'cs.OH',
'cs.OS',
'cs.PF',
'cs.PL',
'cs.RO',
'cs.SC',
'cs.SD',
'cs.SE',
'cs.SI',
'cs.SY',
'dg-ga',
'econ.EM',
'econ.GN',
'econ.TH',
'eess.AS',
'eess.IV',
'eess.SP',
'eess.SY',
'funct-an',
'gr-qc',
'hep-ex',
'hep-lat',
'hep-ph',
'hep-th',
'math-ph',
'math.AC',
'math.AG',
'math.AP',
'math.AT',
'math.CA',
'math.CO',
'math.CT',
'math.CV',
'math.DG',
'math.DS',
'math.FA',
'math.GM',
'math.GN',
'math.GR',
'math.GT',
'math.HO',
'math.IT',
'math.KT',
'math.LO',
'math.MG',
'math.MP',
'math.NA',
'math.NT',
'math.OA',
'math.OC',
'math.PR',
'math.QA',
'math.RA',
'math.RT',
'math.SG',
'math.SP',
'math.ST',
'mtrl-th',
'nlin.AO',
'nlin.CD',
'nlin.CG',
'nlin.PS',
'nlin.SI',
'nucl-ex',
'nucl-th',
'patt-sol',
'physics.acc-ph',
'physics.ao-ph',
'physics.app-ph',
'physics.atm-clus',
'physics.atom-ph',
'physics.bio-ph',
'physics.chem-ph',
'physics.class-ph',
'physics.comp-ph',
'physics.data-an',
'physics.ed-ph',
'physics.flu-dyn',
'physics.gen-ph',
'physics.geo-ph',
'physics.hist-ph',
'physics.ins-det',
'physics.med-ph',
'physics.optics',
'physics.plasm-ph',
'physics.pop-ph',
'physics.soc-ph',
'physics.space-ph',
'q-alg',
'q-bio',
'q-bio.BM',
'q-bio.CB',
'q-bio.GN',
'q-bio.MN',
'q-bio.NC',
'q-bio.OT',
'q-bio.PE',
'q-bio.QM',
'q-bio.SC',
'q-bio.TO',
'q-fin.CP',
'q-fin.EC',
'q-fin.GN',
'q-fin.MF',
'q-fin.PM',
'q-fin.PR',
'q-fin.RM',
'q-fin.ST',
'q-fin.TR',
'quant-ph',
'solv-int',
'stat.AP',
'stat.CO',
'stat.ME',
'stat.ML',
'stat.OT',
'stat.TH',
'supr-con'}
这里使用了 split 函数将多类别使用 “ ”(空格)分开,组成list,并使用 for 循环将独立出现的类别找出来,并使用 set 类别,将重复项去除得到最终所有的独立paper种类,从以上结果发现,共有172种论文种类
具体的结果是:
首先是temp = [x.split(’ ') for x in data[“categories”]]就是对于每一个data[“categories”]中的元素按照空格进行split,这对应一个paper的多个类别,是一个list[list[]],外层的list是每一个paper,内层是每一个paper的类别。
然后 for l in temp 是将每一个paper分开
for i in l 是对于一个分离得到一个paper的多个种类
再使用set去除重复的str
我们的任务要求对于2019年以后的paper进行分析,所以首先对于时间特征进行预处理,从而得到2019年以后的所有种类的论文:
#爬取所有的类别
website_url = requests.get('https://arxiv.org/category_taxonomy').text #获取网页的文本数据
soup = BeautifulSoup(website_url,'lxml') #爬取数据,这里使用lxml的解析器,加速
root = soup.find('div',{'id':'category_taxonomy_list'}) #找出 BeautifulSoup 对应的标签入口
tags = root.find_all(["h2","h3","h4","p"], recursive=True) #读取 tags
#初始化 str 和 list 变量
level_1_name = ""
level_2_name = ""
level_2_code = ""
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []#进行
for t in tags:
if t.name == "h2":
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)",r"\2",raw) #正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r"(.*)\((.*)\)",r"\1",raw)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)",r"\1",raw)
level_3_name = re.sub(r"(.*) \((.*)\)",r"\2",raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
#根据以上信息生成dataframe格式的数据
df_taxonomy = pd.DataFrame({
'group_name' : level_1_names,
'archive_name' : level_2_names,
'archive_id' : level_2_codes,
'category_name' : level_3_names,
'categories' : level_3_codes,
'category_description': level_3_notes
})
#按照 "group_name" 进行分组,在组内使用 "archive_name" 进行排序
df_taxonomy.groupby(["group_name","archive_name"])
df_taxonomy| group_name | archive_name | archive_id | category_name | categories | category_description | |
|---|---|---|---|---|---|---|
| 0 | Computer Science | Computer Science | Computer Science | Artificial Intelligence | cs.AI | Covers all areas of AI except Vision, Robotics... |
| 1 | Computer Science | Computer Science | Computer Science | Hardware Architecture | cs.AR | Covers systems organization and hardware archi... |
| 2 | Computer Science | Computer Science | Computer Science | Computational Complexity | cs.CC | Covers models of computation, complexity class... |
| 3 | Computer Science | Computer Science | Computer Science | Computational Engineering, Finance, and Science | cs.CE | Covers applications of computer science to the... |
| 4 | Computer Science | Computer Science | Computer Science | Computational Geometry | cs.CG | Roughly includes material in ACM Subject Class... |
| ... | ... | ... | ... | ... | ... | ... |
| 150 | Statistics | Statistics | Statistics | Computation | stat.CO | Algorithms, Simulation, Visualization |
| 151 | Statistics | Statistics | Statistics | Methodology | stat.ME | Design, Surveys, Model Selection, Multiple Tes... |
| 152 | Statistics | Statistics | Statistics | Machine Learning | stat.ML | Covers machine learning papers (supervised, un... |
| 153 | Statistics | Statistics | Statistics | Other Statistics | stat.OT | Work in statistics that does not fit into the ... |
| 154 | Statistics | Statistics | Statistics | Statistics Theory | stat.TH | stat.TH is an alias for math.ST. Asymptotics, ... |
155 rows × 6 columns
1.4.3 数据分析及可视化
接下来我们首先看一下所有大类的paper数量分布,我们使用merge函数,以两个dataframe共同的属性 “categories” 进行合并,并以 “group_name” 作为类别进行统计,统计结果放入 “id” 列中并排序。
_df = data.merge(df_taxonomy, on="categories", how="left").drop_duplicates(["id","group_name"]).groupby("group_name").agg({"id":"count"}).sort_values(by="id",ascending=False).reset_index()
_df=_df.rename(columns={'id':'count'})
_df| group_name | count | |
|---|---|---|
| 0 | Physics | 38379 |
| 1 | Mathematics | 24495 |
| 2 | Computer Science | 18087 |
| 3 | Statistics | 1802 |
| 4 | Electrical Engineering and Systems Science | 1371 |
| 5 | Quantitative Biology | 886 |
| 6 | Quantitative Finance | 352 |
| 7 | Economics | 173 |
下面我们使用饼图进行上图结果的可视化
fig = plt.figure(figsize=(15,12))
explode = (0, 0, 0, 0.2, 0.3, 0.3, 0.2, 0.1)
plt.pie(_df["count"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160, explode=explode)
plt.tight_layout()
plt.show()
下面统计在计算机各个子领域2019年后的paper数量:
group_name="Computer Science"
cats = data.merge(df_taxonomy, on="categories").query("group_name == @group_name")
cats.groupby(["year","category_name"]).count().reset_index().pivot(index="category_name", columns="year",values="id") 
数据包获取:https://download.csdn.net/download/weixin_44064434/14503617