三维特征描述子:PFH、FPFH、VFH、PPF
参考:
- https://segmentfault.com/a/1190000021430941
- http://www.pclcn.org/study/shownews.php?id=101
- https://blog.csdn.net/xinxiangwangzhi_/article/details/90023207
- https://blog.csdn.net/u011736771/article/details/85103293
- http://www.pclcn.org/study/shownews.php?id=95
引言
- 一堆离散的样点,只包含相对于某个坐标系下的位置参数,虽然能在空间中比较好的显示出物体的样子来,但对于视觉来说,这是远远不够的。之所以在文章的题目中提到特征,就是希望能用特征的方法,达到视觉识别的功能。
- 离散点云,除了坐标信息外,最为直观的特征就是点、法向、曲率,这是最简单的特征,也是最忠实于原始点云的,这些特征包含了点云的最为详细的数据,虽然很少直接的使用,但在这个特征的基础上,可以实现更高层次的识别。计算简单,速度快是这些基础特征的特点之一,但是在进行物体识别的时候,在大场景中,拥有相似法向或曲率的区域太多了,这就从一定程度上削弱了它的作用。
- 下面将会逐步介绍下PFH、 FPHF、VFH等特征的原理与PCL的实现方式。
1. PFH
1.1 PFH原理
正如点特征表示法所示,表面法线和曲率估计是某个点周围的几何特征基本表示法。虽然计算非常快速容易,但是无法获得太多信息,因为它们只使用很少的几个参数值来近似表示一个点的k邻域的几何特征。然而大部分场景中包含许多特征点,这些特征点有相同的或者非常相近的特征值,因此采用点特征表示法,其直接结果就减少了全局的特征信息。本小节介绍三维特征描述子中的一位成员:点特征直方图(Point Feature Histograms),我们简称为PFH,本小节将介绍它的理论优势,从PCL实现的角度讨论其实施细节。PFH特征不仅与坐标轴三维数据有关,同时还与表面法线有关。
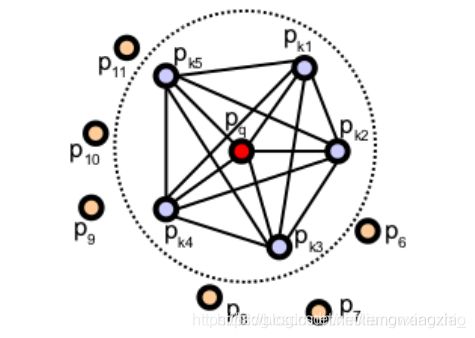
PFH计算方式通过参数化查询点与邻域点之间的空间差异,并形成一个多维直方图对点的k邻域几何属性进行描述。直方图所在的高维超空间为特征表示提供了一个可度量的信息空间,对点云对应曲面的6维姿态来说它具有不变性,并且在不同的采样密度或邻域的噪音等级下具有鲁棒性。点特征直方图(PFH)表示法是基于点与其k邻域之间的关系以及它们的估计法线,简言之,它考虑估计法线方向之间所有的相互作用,试图捕获最好的样本表面变化情况,以描述样本的几何特征。因此,合成特征超空间取决于每个点的表面法线估计的质量。如图1所示,表示的是一个查询点(Pq) 的PFH计算的影响区域,Pq 用红色标注并放在圆球的中间位置,半径为r, (Pq)的所有k邻元素(即与点Pq的距离小于半径r的所有点)全部互相连接在一个网络中。最终的PFH描述子通过计算邻域内所有两点之间关系而得到的直方图,因此存在一个O(k) 的计算复杂性。

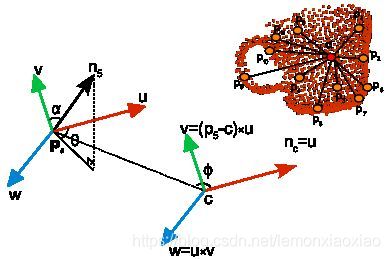
为了计算两点Pi和Pj及与它们对应的法线Ni和Nj之间的相对偏差,在其中的一个点上定义一个固定的局部坐标系,如图2所示。

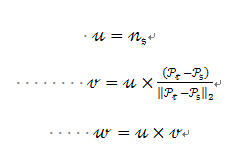
使用上图中uvw坐标系,法线Ni和Nj之间的偏差可以用一组角度来表示,如下所示:
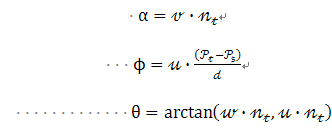
d是两点Ps和Pt之间的欧氏距离
![]()
计算k邻域内的每一对点的
![]()
四组值,这样就把两点和它们法线相关的12个参数(xyz坐标值和法线信息)减少到4个。
为每一对点估计PFH四元组,可以使用:
computePairFeatures (const Eigen::Vector4f &p1, const Eigen::Vector4f &n1,
const Eigen::Vector4f &p2, const Eigen::Vector4f &n2,
float &f1, float &f2, float &f3, float &f4);
有关其他详细信息,请见API文件。为查询点创建最终的PFH表示,所有的四元组将会以某种统计的方式放进直方图中,这个过程首先把每个特征值范围划分为b个子区间,并统计落在每个子区间的点数目,因为四分之三的特征在上述中为法线之间的角度计量,在三角化圆上可以将它们的参数值非常容易地归一到相同的区间内。一个统计的例子是:把每个特征区间划分成等分的相同数目,为此在一个完全关联的空间内创建有b个区间的直方图。在这个空间中,一个直方图中某一区间统计个数的增一对应一个点的四个特征值。如图3所示,就是点云中不同点的点特征直方图表示法的一个例子,在某些情况下,第四个特征量d在通常由机器人捕获的2.5维数据集中并不重要,因为临近点间的距离从视点开始是递增的,而并非不变的,在扫描局部点密度影响特征时,实践证明省略d是有益的。
1.2 PCL实现
点特征直方图(PFH)在PCL中的实现是pcl_features模块的一部分。默认PFH的实现使用5个区间分类(例如:四个特征值中的每个都使用5个区间来统计),其中不包括距离(在上文中已经解释过了——但是如果有需要的话,也可以通过用户调用computePairFeatures方法来获得距离值),这样就组成了一个125浮点数元素的特征向量(3^5),其保存在一个pcl::PFHSignature125的点类型中。以下代码段将对输入数据集中的所有点估计其对应的PFH特征。
#include PFHEstimation类的实际计算程序内部只执行以下:
对点云P中的每个点p:
- 得到p点的最近邻元素
- 对于邻域内的每对点,计算其三个角度特征参数值
- 将所有结果统计到一个输出直方图中
使用下列代码,从一个k-邻域计算单一的PFH描述子:
computePointPFHSignature (const pcl::PointCloud<PointInT> &cloud,
const pcl::PointCloud<PointNT> &normals,
const std::vector<int > &indices,
int nr_split,
Eigen::VectorXf &pfh_histogram);
此处,cloud变量是包含点的输入点云,normals变量是包含对应cloud的法线的输入点云,indices代表输入点云(点与法线对应)中查询点的k-近邻元素集,nr_split是所分区间的数目,用于每个特征区间的统计过程,pfh_histogram是浮点数向量来存储输出的合成直方图。
1.3 PFH的总结
点特征的描述子一般是基于点坐标、法向量、曲率来描述某个点周围的几何特征。用点特征描述子不能提供特征之间的关系,减少了全局特征信息。因此诞生了一直基于直方图的特征描述子:PFH–point feature histogram(点特征直方图)。
PFH通过参数化查询点和紧邻点之间的空间差异,形成了一个多维直方图对点的近邻进行几何描述,直方图提供的信息对于点云具有平移旋转不变性,对采样密度和噪声点具有稳健性。PFH是基于点与其邻近之间的关系以及它们的估计法线,也即是它考虑估计法线之间的相互关系,来描述几何特征。
PFH的缺点:
- 计算复杂度高。已知点云P中有n个点,假设点云均匀密度,每点在邻域半径r内平均可以选到k个近邻,该算法对每个点来说计算PFH的时间复杂度为O(k^2),那么它的点特征直方图(PFH)的理论计算复杂度就是 O(nk²)。对于实时应用或接近实时应用中,密集点云的点特征直方图(PFH)的计算,O(nk²)的计算复杂度实在不敢恭维,是一个主要的性能瓶颈。
- 存在大量的重复计算。在PFH的三个特征元素的计算过程中,邻域内任意两点都需要计算一次三个特征元素值。这对于相邻的点来说,尽管他们的邻域不一定完全相同,但有很大的概率会同时包含某些近邻点(邻域半径的值越大,重复的近邻就越多)。这些被同时包含的近邻点之间的会被重复地配对在一起并计算特征元素值。虽然论文及PCL了中都引入了高速缓存机制,把重复的计算的花销改成查找的花销,但其效率依然没有太大的改观。
2. FPFH
2.1 FPFH原理
快速点特征直方图(Fast Point Feature Histograms, FPFH)是PFH计算方式的简化形式。它的思想在于分别计算查询点的k邻域中每一个点的简化点特征直方图(Simplified Point Feature Histogram,SPFH),再通过一个公式将所有的SPFH加权成最后的快速点特征直方图。FPFH把算法的计算复杂度降低到了O(nk) ,但是任然保留了PFH大部分的识别特性。
FPFH计算过程:
- 只计算每个查询点Pq和它邻域点之间的三个特征元素(参考PFH),在这里不同于PFH:PFH是计算邻域点所有组合的特征元素,而这一步只计算查询点和近邻点之间的特征元素。如下图,第一个图是PFH计算特征过程,即邻域点所有组合的特征值(图中所有连线,包括但不限于Pq和Pk之间的连线),第二个图是FPFH的计算内容,只需要计算Pq(查询点)和紧邻点(图2中红线部分)之间的特征元素。可以看出降低了复杂度我们称之为SPFH(simple point feature histograms)。
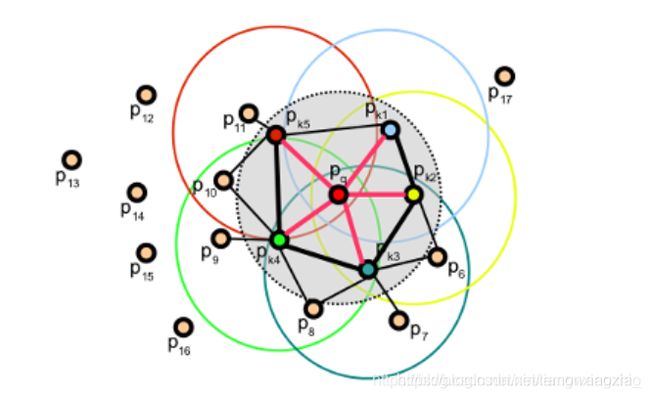
- 重新确定k近邻域,为了确定查询点Pq的近邻点Pk的SPFH值、查询点Pq和近邻的距离以及k的数值(一般使用半径kdtree搜索,只能确定某半径范围内的近邻点,不能确定具体的查询点与近邻的距离、k数值----PS:应该是这样,不过重新确定k近邻主要还是计算查询点Pq的近邻点Pk的SPFH值),则:
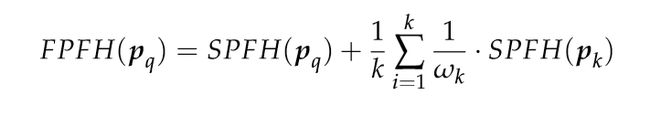
其中Wk为权重,一般为距离,表示查询点p与给定度量空间中的近邻点pk之间的距离。
2.2 FPFH与PFH的主要区别
- FPFH没有对全互连点的所有邻近点的计算参数进行统计,因此可能漏掉了一些重要的点对,而这些漏掉的对点可能对捕获查询点周围的几何特征有贡献。
- PFH特征模型是对查询点周围的一个精确的邻域半径内,而FPFH还包括半径r范围以外的额外点对(但不超过2r的范围);
- 因为采用权重计算的方式,所以FPFH结合SPFH值,重新捕获邻近重要点对的几何信息;
- 由于大大地降低了FPFH的整体复杂性,因此FPFH有可能使用在实时应用中;
- 在FPFH中,通过分解三元组(三个角特征)简化了合成的直方图,即简单地创建b个相关的的特征直方图,每个特征维数(dimension)对应一个直方图(bin),并将它们连接在一起。pcl默认,in PFH assume the number of quantum bins (i.e. subdivision intervals in a feature’s value range),bins(b)=5即子区间数量,三个角特征元素,3^5=125,也就是一个查询点就有125个子区间,PFHSignature125的由来。这样有一个问题:对于点云特别是稀疏点云来说,很多区间存在0值,即直方图上存在冗余空间。因此,在FPFH中,通过分解三元组(三个角特征)简化了合成的直方图,即简单地创建b个不相关的的特征直方图,每个特征维数(dimension)对应一个直方图(bin),并将它们连接在一起。pcl默认FPFH的b=11,3*11=33,也就是FPFHSignature33的由来。
2.3 PCL实现
/** \brief 根据(f1, f2, f3)三个特征值计算单个SPFH
* \param[in] cloud 输入点云
* \param[in] normals 法线信息
* \param[in] p_idx 查询点(source)
* \param[in] row 在特征直方图里对应的行号
* \param[in] indices k近邻索引
* \param[out] hist_f1 f1特征矩阵
* \param[out] hist_f2 f2特征矩阵
* \param[out] hist_f3 f3特征矩阵
*/
template <typename PointInT, typename PointNT, typename PointOutT> void
pcl::FPFHEstimation<PointInT, PointNT, PointOutT>::computePointSPFHSignature (
const pcl::PointCloud<PointInT> &cloud, const pcl::PointCloud<PointNT> &normals,
int p_idx, int row, const std::vector<int> &indices,
Eigen::MatrixXf &hist_f1, Eigen::MatrixXf &hist_f2, Eigen::MatrixXf &hist_f3)
{
Eigen::Vector4f pfh_tuple;
// 从直方图矩阵中获取特征的分隔数bins
int nr_bins_f1 = static_cast<int> (hist_f1.cols ());
int nr_bins_f2 = static_cast<int> (hist_f2.cols ());
int nr_bins_f3 = static_cast<int> (hist_f3.cols ());
// Factorization constant
float hist_incr = 100.0f / static_cast<float>(indices.size () - 1);
// 对近邻点进行迭代计算
for (size_t idx = 0; idx < indices.size (); ++idx)
{
// 对自身不计算
if (p_idx == indices[idx])
continue;
// 对查询点p_idx以及它的某一近邻这对点计算三个特征值
if (!computePairFeatures (cloud, normals, p_idx, indices[idx], pfh_tuple[0], pfh_tuple[1], pfh_tuple[2], pfh_tuple[3]))
continue;
// 归一化f1, f2, f3 并存入直方图中
int h_index = static_cast<int> (floor (nr_bins_f1 * ((pfh_tuple[0] + M_PI) * d_pi_)));
if (h_index < 0) h_index = 0;
if (h_index >= nr_bins_f1) h_index = nr_bins_f1 - 1;
hist_f1 (row, h_index) += hist_incr; // 对应的区间中落了值,统计的直方图数量+100/k
h_index = static_cast<int> (floor (nr_bins_f2 * ((pfh_tuple[1] + 1.0) * 0.5)));
if (h_index < 0) h_index = 0;
if (h_index >= nr_bins_f2) h_index = nr_bins_f2 - 1;
hist_f2 (row, h_index) += hist_incr;
h_index = static_cast<int> (floor (nr_bins_f3 * ((pfh_tuple[2] + 1.0) * 0.5)));
if (h_index < 0) h_index = 0;
if (h_index >= nr_bins_f3) h_index = nr_bins_f3 - 1;
hist_f3 (row, h_index) += hist_incr;
}
}
/** \brief 加权SPFH以计算最终的FPFH
* \param[in] hist_f1 f1特征向量
* \param[in] hist_f2 f2特征向量
* \param[in] hist_f3 f3特征向量
* \param[in] indices 查询点p_idx的k近邻索引
* \param[in] dists 查询点p_idx到其k近邻的距离
* \param[out] fpfh_histogram 最后的FPFH
*/
template <typename PointInT, typename PointNT, typename PointOutT> void
pcl::FPFHEstimation<PointInT, PointNT, PointOutT>::weightPointSPFHSignature (
const Eigen::MatrixXf &hist_f1, const Eigen::MatrixXf &hist_f2, const Eigen::MatrixXf &hist_f3,
const std::vector<int> &indices, const std::vector<float> &dists, Eigen::VectorXf &fpfh_histogram)
{
assert (indices.size () == dists.size ());
double sum_f1 = 0.0, sum_f2 = 0.0, sum_f3 = 0.0; // 各特征值的总和
float weight = 0.0, val_f1, val_f2, val_f3; // 权值和
// 获取特征分隔数bins
int nr_bins_f1 = static_cast<int> (hist_f1.cols ());
int nr_bins_f2 = static_cast<int> (hist_f2.cols ());
int nr_bins_f3 = static_cast<int> (hist_f3.cols ());
int nr_bins_f12 = nr_bins_f1 + nr_bins_f2;
// 清空直方图,这里共33个
fpfh_histogram.setZero (nr_bins_f1 + nr_bins_f2 + nr_bins_f3);
// Use the entire patch
for (size_t idx = 0, data_size = indices.size (); idx < data_size; ++idx)
{
// 查询点本身不做计算
if (dists[idx] == 0)
continue;
// 标准权值为查询点到此近邻的距离的倒数
weight = 1.0f / dists[idx];
// 对查询点及其近邻的SPFH进行加权
for (int f1_i = 0; f1_i < nr_bins_f1; ++f1_i)
{
val_f1 = hist_f1 (indices[idx], f1_i) * weight;
sum_f1 += val_f1;
fpfh_histogram[f1_i] += val_f1;
}
for (int f2_i = 0; f2_i < nr_bins_f2; ++f2_i)
{
val_f2 = hist_f2 (indices[idx], f2_i) * weight;
sum_f2 += val_f2;
fpfh_histogram[f2_i + nr_bins_f1] += val_f2;
}
for (int f3_i = 0; f3_i < nr_bins_f3; ++f3_i)
{
val_f3 = hist_f3 (indices[idx], f3_i) * weight;
sum_f3 += val_f3;
fpfh_histogram[f3_i + nr_bins_f12] += val_f3;
}
}
if (sum_f1 != 0)
sum_f1 = 100.0 / sum_f1; // histogram values sum up to 100
if (sum_f2 != 0)
sum_f2 = 100.0 / sum_f2; // histogram values sum up to 100
if (sum_f3 != 0)
sum_f3 = 100.0 / sum_f3; // histogram values sum up to 100
// 调整最终的FPFH值,乘了100
for (int f1_i = 0; f1_i < nr_bins_f1; ++f1_i)
fpfh_histogram[f1_i] *= static_cast<float> (sum_f1);
for (int f2_i = 0; f2_i < nr_bins_f2; ++f2_i)
fpfh_histogram[f2_i + nr_bins_f1] *= static_cast<float> (sum_f2);
for (int f3_i = 0; f3_i < nr_bins_f3; ++f3_i)
fpfh_histogram[f3_i + nr_bins_f12] *= static_cast<float> (sum_f3);
}
/** \brief 计算FPFH描述子,最终公式 */
template <typename PointInT, typename PointNT, typename PointOutT> void
pcl::FPFHEstimation<PointInT, PointNT, PointOutT>::computeFeature (PointCloudOut &output)
{
std::vector<int> nn_indices (k_); // 存储某点的k个近邻的索引
std::vector<float> nn_dists (k_); // 存储某点到其k个近邻的距离
std::vector<int> spfh_hist_lookup; // 存储SPFH特征查询表
// 计算查询点的SPFH特征,得到SPFH特征查询表
computeSPFHSignatures (spfh_hist_lookup, hist_f1_, hist_f2_, hist_f3_);
output.is_dense = true;
// 如果输入点云是dense的,就不用对每个点坐标的有效性进行判断(针对无效值NaN/和无限值Inf)
if (input_->is_dense)
{
// 对每个近邻进行迭代计算
for (size_t idx = 0; idx < indices_->size (); ++idx)
{
// 找到每个近邻的k近邻
if (this->searchForNeighbors((*indices_)[idx], search_parameter_, nn_indices, nn_dists) == 0)
{
// 如果某一近邻的近邻查找失败,则输出点云非dense,FPFH置为NaN
for (int d = 0; d < fpfh_histogram_.size (); ++d)
output.points[idx].histogram[d] = std::numeric_limits<float>::quiet_NaN ();
output.is_dense = false;
continue;
}
// 某一近邻的近邻查找成功, 将近近邻索引值映射到SPFH矩阵里的行号
// instead of indices into surface_->points
for (size_t i = 0; i < nn_indices.size (); ++i)
nn_indices[i] = spfh_hist_lookup[nn_indices[i]];
// 加权计算FPFH特征
weightPointSPFHSignature (hist_f1_, hist_f2_, hist_f3_, nn_indices, nn_dists, fpfh_histogram_);
// 将FPFH特征输出
for (int d = 0; d < fpfh_histogram_.size (); ++d)
output.points[idx].histogram[d] = fpfh_histogram_[d];
}
}
else // 输入点云非dense,加了一个坐标值有效性判断,其他一样
{
// Iterate over the entire index vector
for (size_t idx = 0; idx < indices_->size (); ++idx)
{
if (!isFinite ((*input_)[(*indices_)[idx]]) ||
this->searchForNeighbors ((*indices_)[idx], search_parameter_, nn_indices, nn_dists) == 0)
{
for (int d = 0; d < fpfh_histogram_.size (); ++d)
output.points[idx].histogram[d] = std::numeric_limits<float>::quiet_NaN ();
output.is_dense = false;
continue;
}
// ... and remap the nn_indices values so that they represent row indices in the spfh_hist_* matrices
// instead of indices into surface_->points
for (size_t i = 0; i < nn_indices.size (); ++i)
nn_indices[i] = spfh_hist_lookup[nn_indices[i]];
// Compute the FPFH signature (i.e. compute a weighted combination of local SPFH signatures) ...
weightPointSPFHSignature (hist_f1_, hist_f2_, hist_f3_, nn_indices, nn_dists, fpfh_histogram_);
// ...and copy it into the output cloud
for (int d = 0; d < fpfh_histogram_.size (); ++d)
output.points[idx].histogram[d] = fpfh_histogram_[d];
}
}
}
3. VFH
3.1 VFH原理
视点特征直方图VFH(Viewpoint Feature Histogram)描述子,它是一种新的特征表示形式,应用在点云聚类识别和六自由度位姿估计问题。图1展示了VFH识别和位姿估计的一个例子。已知一组训练样本数据(除最左端的点云之外的首行,底行),学习了一个模型,然后使用一个点云(左下方)来查询/测试这个模型。从左下方开始,匹配结果从左到右是按照最好到最坏的顺序排列的。
视点特征直方图(或VFH)是源于FPFH描述子(见Fast Point Feature Histograms (PFH) 描述子)。由于它的获取速度和识别力,我们决定利用FPFH强大的识别力,但是为了使构造的特征保持缩放不变性的性质同时,还要区分不同的位姿,计算时需要考虑加入视点变量。我们做了以下两种计算来构造特征,以应用于目标识别问题和位姿估计:
- 扩展FPFH,使其利用整个点云对象来进行计算估计(如图2所示),在计算FPFH时以物体中心点与物体表面其他所有点之间的点对作为计算单元。2. 添加视点方向与每个点估计法线之间额外的统计信息,为了达到这个目的,我们的关键想法是在FPFH计算中将视点方向变量直接融入到相对法线角计算当中。
通过统计视点方向与每个法线之间角度的直方图来计算视点相关的特征分量。注意:并不是每条法线的视角,因为法线的视角在尺度变换下具有可变性,我们指的是平移视点到查询点后的视点方向和每条法线间的角度。第二组特征分量就是前面PFH中讲述的三个角度,如PFH小节所述,只是现在测量的是在中心点的视点方向和每条表面法线之间的角度,如图3所示。

因此新组合的特征被称为视点特征直方图(VFH)。下图表体现的就是新特征的想法,包含了以下两部分:
- 一个视点方向相关的分量
- 一个包含扩展FPFH的描述表面形状的分量
3.2 PCL实现
视点特征直方图在PCL中的实现属于pcl_features模块库的一部分。对扩展的FPFH分量来说,默认的VFH的实现使用45个子区间进行统计,而对于视点分量要使用128个子区间进行统计,这样VFH就由一共308个浮点数组成阵列。在PCL中利用pcl::VFHSignature308的点类型来存储表示。PFH/FPFH描述子和VFH之间的主要区别是:对于一个已知的点云数据集,只一个单一的VFH描述子,而合成的PFH/FPFH特征的数目和点云中的点数目相同。以下代码段将对输入数据集中的所有点估计一组VFH特征值。
#include libpcl_visualization包含一个特殊的PCLHistogramVisualization类,它也被pcd_viewer用来自动显示一个浮点值的直方图VFH描述子,对于从点云估计得到的VFH文件与pcd文件一样,也是点云文件,可视化可以同样利用pcd_viewer点云查看工具查看,查看结果如图5所示,对于更多关于VFH可视化细节可以参考API文档。
4. PPF
4.1 PPF原理
PPF全称Point Pair Feature,翻译出来,就是点对特征,通俗来讲,就是将一堆散乱点看成两两之间的某种关系,与其用文字描述,不如用一张图带过:
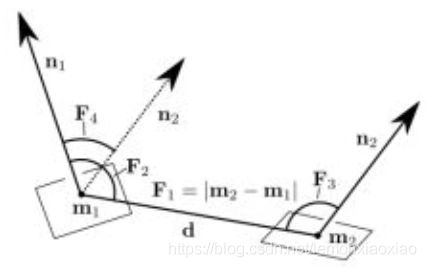
因此,构成m1与m2之间的点对关系为:
![]()
其中,d表示点与点之间的距离。
总结
VFH与FPFH(Fast Point Feature Histograms)有着千丝万缕的关系,可以说是站在FPFH的肩膀上发展的,高效率与高识别力是FPFH的特点,但这些在实际应用中是远远不够的,因此,又追加上了保持尺寸不变性的视角方差,最终得到VFH。
VFH存在的主要意义就是要解决目标识别与姿态估计的问题,为更好的解决此问题,在实现目标簇的FPFH的估计值上,增加了视点方向与法向之间的统计数据,这就是VFH的主要思想。视点分量是通过视点与法向夹角的统计计算出来的:需要注意的是,计算的是每个法线的中心视点方向之间的夹角,而不是计算每个法向的视角,因为如果是这样的话,那就不能保证旋转不变性了。第二个分量就是欧拉角了,是指中心点与法向之间的夹角。两种的组合就时VFH了,主要特点有两个部分:
- 视角方向相关的分量
- 扩展FPFH的描述表面特征的分量
