Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
扩散自编码器:面向有意义和可解码的表示
code:https://github.com/phizaz/diffae
A CVPR 2022 (ORAL) paper (paper, site, 5-min video)
贡献:
本文的重点就是构建了一个与 Vanilla Autoencoder 不同的框架,Vanilla Autoencoder 无法重建出清晰的图像,因为它重建的图像很模糊,所以本文提出了一种新颖的Autoencoder 可以重建出清晰的图像,并且提取了它的高级语义【semantics】以及低级的随机变化【stochastic variations / stochastic subcode】,可以应用于很多的下游任务。
- renders good images with near-perfect reconstuction(提出了一个Autoencoder ,它可以近乎完美的重建图像)
- learns meaningful and linear representation useful for downstream tasks(学习到了有意义的线性表示可以用于下游任务)
- allows straightforward solutions to many image applications without GAN’s inversion to operate on real images(是许多图像应用的直接解决方案,而无需GAN inversion 来操作真实图像)
Video 介绍:
1)Vanilla Autoencoder

我们的目标是学习一种具有两种关键属性的 latent code ,
1)可以捕获 high-level schematics,例如“年龄、性别、头发的样式”,
2)代码应该是完全可解码的,可以重建为清晰的图像
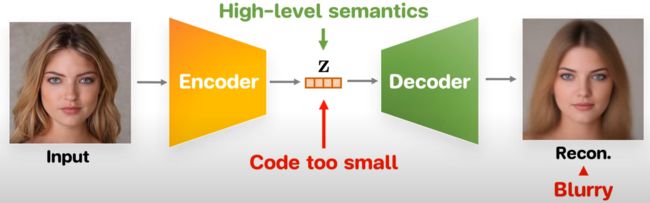
Vanilla Autoencoder 有一个比较小的bottleneck 可以捕获 high-level schematics,但是由于这个bottleneck 产生的latent code太小,所以无法捕获所有的细节并重建高质量的图像
技术使用代码的层次结构但是这些代码是稀疏的(sparse)并且失去了捕获全局示意图(global schematics)如年龄或性别的能力
2)Diffusion autoencoder DiffAE
但是使用diffusion模型(DDIM)可以将图像Recon为高质量的图像,然而它缺少有意义的latent code,而这里就是我们要解决的问题。
我们的key想法就是利用一个CNN Encoder将input image 提取Semantic code 来增强整个diffusion 过程,那么现在diffusion 的each step 都会以Semantic code 为条件(condition)。
所以如果AE可以将任何图像编码为随机噪声图和semantic,那么它们就可以近乎完美的重建,
3)What is Semantic code VS Noise map?
这里如果将DDIM inverse得到的noise图替换成随机噪声,但是还是用原来的semantic code,那么Recon得到的图像和原始输入的图像会有一些区别,但是差别不大
这里他们也做了实验,固定semantic code,然后varying noise,发现会变化重建的图像的一些细节,但是大体的形象不变
4)Semantic code is a Linearly Discriminative

find semantic code 可以作为一种性别分类器
5)Attribute Manipulation
训练自动编码器训练与这些分类器还为我们提供了与图像中的语义变化相对应的权重向量V,我们可以在semantic code添加预测波浪发的分类器的权重向量 v从而波浪长发,
6)Fast Denosing
比DDIM更快的去噪
Figure 1. Attribute manipulation and interpolation on real images.
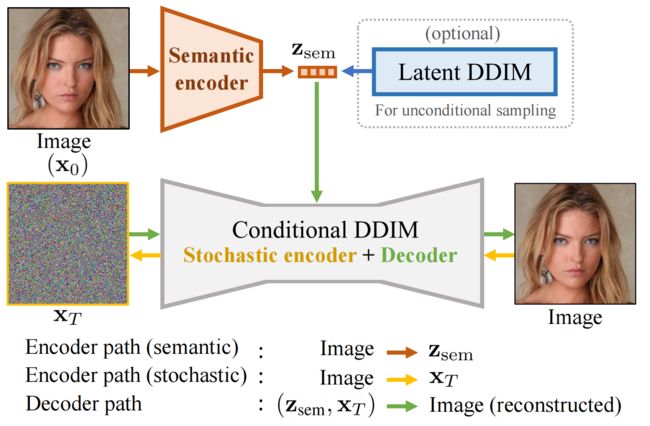
Figure 2: Overview of our diffusion autoencoder.
Autoencoder由4部分组成, Z s e m Z_{sem} Zsem 捕获了高级语义【semantics】, while X T X_T XT 捕获了低级的随机变化【stochastic variations / stochastic subcode】, 它俩一起可以精准的decoder回原始图像。
- a “semantic” encoder that maps the input image to the semantic subcode ( X 0 → Z s e m X_0 \to Z_{sem} X0→Zsem),
- a conditional DDIM that acts both as a “stochastic” encoder ( X 0 → X T X_0 \to X_{T} X0→XT )
- a decoder ( ( ( z s e m , x T ) → X 0 ) \left(\left(\mathbf{z}_{\mathrm{sem}}, \mathbf{x}_{T}\right) \rightarrow X_{0}\right) ((zsem,xT)→X0)).
- 为了从autoencoder采样(为了无条件图像生成), we fit a latent DDIM to the distribution of Z s e m Z_{sem} Zsemand sample ( z s e m , x T ∼ N ( 0 , I ) ) \left(\mathbf{z}_{\mathrm{sem}}, \mathbf{x}_{T} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\right) (zsem,xT∼N(0,I)) for decoding.
Figure 3. 由改变随机子码 X T X_T XT 引起的变化和重建结果. 每一行对应一个不同的 Z s e m Z_{sem} Zsem, 它完全改变了人,而改变随机子码 X T X_T XT 只影响次要的细节。
Figure 5. 通过移动被线性分类器发现的 Z s e m Z_{sem} Zsem 的正向或逆向 Z s e m Z_{sem} Zsem 改变人脸的属性。
Figure 6. 逆向生成 x 0 x_0 x0 at t 9 , 8 , 7 , 5 , 2 , 0 ( T = 10 ) t_{9,8,7,5,2,0} (T=10) t9,8,7,5,2,0(T=10). 通过以 Z s e m Z_{sem} Zsem 为条件, 我们的方法生成与 x 0 x_0 x0相似的图像更快。
写在最后: 其实这种通过改变latent的方式改变外观/一些属性的方法并不好,因为真实的效果很差,他们只展示效果比较好的,并且你在训练的时候需要标注大量的数据集,比如眼睛的位置、嘴巴的位置、…
Some question on github
1、Q: Latent DDIM 和 Autoencoder是同时训练的吗?
【https://github.com/phizaz/diffae/issues/9】
A:
他们不是同时训练的,先训练autoencoder,再训练DDIM。
你可以单独训练autoencoder,但是这样你只得到了一个autoencoder架构,它没有办法生成变化很大的图像,而是只能得到通过改变xT而变化一些细节的图像。
所以为了得到变化很大的图像,你需要从"semantic code"中采样,而为了得到很多"semantic code",你需要一个生成模型(本文中叫做“ latent DPM”),它是在一个"semantic code pool " 中训练得到的,而为了得到这个"semantic code pool " 你需要先训练一个autoencoder.