基于Python的淘宝用户行为分析
项目源码:Github
项目简介
随着移动互联网技术的飞速发展和大众人均收入的增长,电商行业也随着技术的发展迅速崛起又快速分化。在当下大众消费需求日趋多样化的时代背景下,移动互联网行业特别是电商行业不再依靠用户红利实现业务增长,开始从粗放型的经营模式转向精细化管理,需要结合市场、渠道、用户行为等数据分析,对用户展开有针对性的运营活动,提供个性化、差异化的经营策略,从而实现运营目的。
本项目使用Python分析淘宝平台2017年11月25日至2017年12月3日的用户行为数据,通过对网站流量、用户活跃率、用户行为转化漏斗、用户行为偏好等特征的分析,提供有针对性的运营策略。
数据来源
本项目数据来源于阿里天池User Behavior Data,为了快速分析项目模型,项目仅截取完整数据集UserBehavior(3.41GB)的迷你数据集UB_split_10.csv(171.7MB)作为本项目的数据集。
数据属性
|
|||||||||||||||||||||
|
评估指标

提出问题
- Q1. 网站流量情况:访问量PV、独立访客数UV、人均访问数PV/UV、跳出率(只存在浏览行为的访问量/PV)、DAU、活跃率等指标情况;
- Q2. 探索用户从浏览到购买整个过程的转化或者流失情况,从而确定关键夹点位置,为后续的改进提出意见;
- Q3. 探索用户的行为模式,从日期、时间、商品种类销量、具体商品销量等维度探索用户的行为偏好和模式;
- Q4. 挖掘用户价值,发现高价值用户
导入数据
考虑到本项目使用的数据量较大,如果将整个分析过程放到同一个脚本下运行,项目会因为Memory Error强制中断,所以为了保证项目的流畅运行,编写另外一个脚本UserBehavior_Taobao_wragledata.ipynb来执行数据导入、数据评估和清理,并导出供本项目分析的数据集updated_valid_df.csv
import pandas as pd
import os
from datetime import datetime,timedelta,timezone
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
np.set_printoptions(suppress=True,threshold=1000000)
valid_df = pd.read_csv('.\\updated_valid_df.csv',)
valid_df.head()
| UserID | ItemID | CategoryID | BehaviorType | Timestamp | Date | Hour | DayofWeek | |
|---|---|---|---|---|---|---|---|---|
| 0 | 314276 | 3657454 | 3738615 | pv | 2017-11-25 09:07:51 | 2017-11-25 | 9 | 6 |
| 1 | 314276 | 98571 | 3738615 | pv | 2017-11-25 09:09:12 | 2017-11-25 | 9 | 6 |
| 2 | 314276 | 76385 | 3108044 | pv | 2017-11-25 09:09:49 | 2017-11-25 | 9 | 6 |
| 3 | 314276 | 1281342 | 3108044 | pv | 2017-11-25 09:10:36 | 2017-11-25 | 9 | 6 |
| 4 | 314276 | 3893085 | 3607361 | pv | 2017-11-25 09:11:38 | 2017-11-25 | 9 | 6 |
探索性分析
通过可视化的方式,探索11月25日-12月3日期间淘宝用户在访问网站、行为转化率、用户行为偏好、商品销量等现状探索
网站流量情况
PV、UV、人均访问数
P V = 浏 览 商 品 的 累 计 次 数 PV = 浏览商品的累计次数 PV=浏览商品的累计次数
U V = 访 问 网 站 的 不 重 复 用 户 个 数 UV = 访问网站的不重复用户个数 UV=访问网站的不重复用户个数
人 均 访 问 数 = P V U V 人均访问数 = \frac{PV}{UV} 人均访问数=UVPV
web_traffic = pd.DataFrame(data= {'PV':(valid_df.BehaviorType == 'pv').sum(), \
'UV':valid_df.UserID.nunique()}, \
index=[1])
web_traffic['人均页面访问数'] = web_traffic.PV/web_traffic.UV
web_traffic
| PV | UV | 人均页面访问数 | |
|---|---|---|---|
| 1 | 4469991 | 48503 | 92.159062 |
本周期内,有48,503位用户登录了淘宝,并产生了4,469,991条浏览记录,人均访问量约为92条
跳出率、日均活跃用户数、活跃率
$跳出率 = \frac{只有点击行为的用户数}{总用户数} $
日 均 活 跃 用 户 数 ( D A U ) = ∑ 日 U V 天 数 日均活跃用户数(DAU) = \frac{\sum{日UV}}{天数} 日均活跃用户数(DAU)=天数∑日UV
日 活 率 ( D A U R a t e ) = D A U U V 日活率(DAU Rate) =\frac{DAU}{UV} 日活率(DAURate)=UVDAU
# 存在cart,fav,buy行为的用户
notonly_pv_user = valid_df[~(valid_df.BehaviorType == 'pv')].UserID.unique()
# 计算跳出率
bounce_rate = 1- ((notonly_pv_user.size)/web_traffic['UV'].values[0])
bounce_rate
0.059790116075294275
# 按照日期分组,计算每一天的活跃用户数
grp_day_dau = valid_df.groupby('Date')['UserID'].nunique()
# 计算日均活跃用户数
dau = grp_day_dau.mean()
round(dau,0)
38047.0
# 计算日活跃率
dau_rate = dau/web_traffic['UV'].values[0]
dau_rate
0.7844234148174111
user_quality = pd.DataFrame(data={'跳出率':bounce_rate,'日均活跃数':round(dau,0),'日活率':dau_rate},index=[1])
user_quality
| 跳出率 | 日均活跃数 | 日活率 | |
|---|---|---|---|
| 1 | 0.05979 | 38047.0 | 0.784423 |
本周期内,淘宝跳出率约为6%,日均活跃用户数为38,047个用户,约占该期间内总用户数的78%
小结
2017年11月25日至2017年12月3日期间内,有48,503位用户访问了淘宝,产生了4,469,991条浏览记录,人均访问量约为92条。在这48,503位用户中,平均每天的日活量为38,047,占总用户量78%,即每天平均有78%的用户会访问淘宝进行商品选购,跳出率约为6%,即约有6%的用户只浏览了商品没有发出任何有意购买的行为。由此可见,淘宝网具有较大的流量规模和用户基数,高日活量和低跳出率说明淘宝具有较好的用户体验和较强的用户粘性,人们能在淘宝上解决其购物需求,其俨然成为人们的主要购物平台。
用户行为路径转化漏斗
探索用户从进入网站、浏览、选择加购到完成购买整个过程的转化情况,从而确定关键夹点位置,为后续的运营策略提出较有针对性的建议。
行为次数转化率
探索商品的整个选购过程中,每一个环节到下一个环节的行为次数转化率
# 统计各个行为的总次数
grp_bh_count = valid_df.groupby('BehaviorType')['UserID'].count()
grp_bh_count
BehaviorType
buy 98863
cart 279393
fav 149147
pv 4469991
Name: UserID, dtype: int64
- 因为加入购物车和收藏在购买商品的步骤上没有先后顺序,而且两种行为都能表现用户对产品可能存在购买意向,同属于购买意向确认阶段,所以可以将这两种行为合并作为购买意向确认阶段的行为总次数;
- 加入购买车或收藏也并非进入购买页面的必要行为,因为部分用户也可以从浏览商品页面直接进入购买页面,但这并不影响计算最后的整体转化率
# 合并加入购物车和收藏的行为数,并删除两者的数据记录
grp_bh_count.loc['cart&fav'] = grp_bh_count.loc['cart'] + grp_bh_count.loc['fav']
grp_bh_count.drop(labels=['cart','fav'],axis=0,inplace=True)
grp_bh_count = grp_bh_count.reset_index(name='count')
grp_bh_count.BehaviorType = grp_bh_count.BehaviorType.astype('category')
grp_bh_count.BehaviorType.cat.reorder_categories(['pv','cart&fav','buy'],inplace=True)
grp_bh_count.sort_values('BehaviorType',inplace=True)
grp_bh_count.reset_index(drop=True,inplace=True)
grp_bh_count
| BehaviorType | count | |
|---|---|---|
| 0 | pv | 4469991 |
| 1 | cart&fav | 428540 |
| 2 | buy | 98863 |
# 可视化行为次数的转化率漏斗
grp_bh_count['last_step_cr'] = grp_bh_count['count']/grp_bh_count['count'].shift(1)
grp_bh_count['total_cr'] = grp_bh_count['count']/grp_bh_count.query('BehaviorType == "pv"')['count'].values[0]
grp_bh_count.fillna({'last_step_cr':1},inplace=True)
from plotly import graph_objects as go
trace = go.Funnel(y=grp_bh_count['BehaviorType'],
x=grp_bh_count['count'],
textinfo="value+percent initial",
marker=dict(color=["deepskyblue", "lightsalmon", "tan"]),
connector={'line': {"color": "royalblue", "dash": "solid", "width": 3}})
layout = go.Layout(title = 'total conversion rate for user behavior'.title(),
yaxis=dict(title='BehaviorType'))
data = [trace]
fig2 = go.Figure(data=data,layout=layout)
fig2.show();
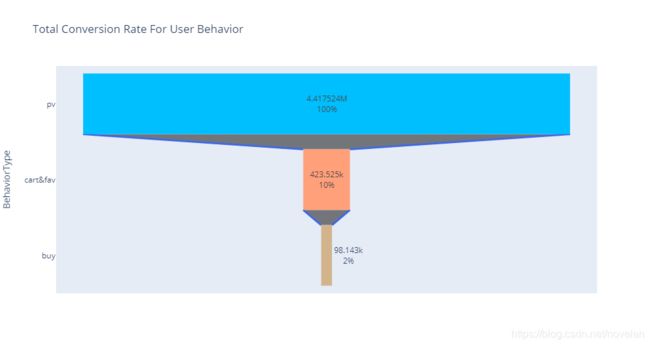
从上图可知,仅有10%的浏览行为转化为加入购物车或收藏,从加入购物车和收藏商品到发生购买的转化率为23%,总体的购买转化率为2%。从整个选购过程的转化率来看,由浏览转化为加入购物车或收藏行为是整个过程中行为流失量最多的环节,所以该阶段应为整个过程的关键夹点,需要在此环节提高转化率。
不同行为的独立用户人数转化率
pv_uv = valid_df[['UserID','BehaviorType']].query("BehaviorType == 'pv'").UserID.nunique()
(web_traffic['UV'].values[0] - pv_uv)/web_traffic['UV'].values[0]
0.004535801909160258
本数据集其实还包含着部分用户在上一个周期商品浏览之后,而在本周期内继续完成下一步加购,收藏和购买行为的用户数,但是该问题值只存在极少量的用户(0.4%)上,所以可以忽略不计:
# 统计不同行为的独立用户人数
cart_fav_user_num = valid_df[(valid_df.BehaviorType == 'cart') | (valid_df.BehaviorType == 'fav')]['UserID'].nunique()
grp_bh_user_num = valid_df.groupby('BehaviorType')['UserID'].nunique()
# 合并加购和收藏的独立用户人数
grp_bh_user_num.loc['cart&fav'] = cart_fav_user_num
grp_bh_user_num
BehaviorType
buy 33032
cart 36585
fav 19383
pv 48283
cart&fav 42396
Name: UserID, dtype: int64
grp_bh_user_num.drop(labels=['cart','fav'],axis=0,inplace=True)
grp_bh_user_num = grp_bh_user_num.reset_index(name='nuique_num')
grp_bh_user_num.BehaviorType = grp_bh_user_num.BehaviorType.astype('category')
grp_bh_user_num.BehaviorType.cat.reorder_categories(['pv','cart&fav','buy'],inplace=True)
grp_bh_user_num.sort_values('BehaviorType',inplace=True)
grp_bh_user_num.reset_index(drop=True,inplace=True)
# 可视化用户人数在不同行为的转化漏斗
trace2 = go.Funnel(y=grp_bh_user_num['BehaviorType'],
x=grp_bh_user_num['nuique_num'],
textinfo="value+percent initial",
marker=dict(color=["deepskyblue", "lightsalmon", "tan"]),
connector={'line': {"color": "royalblue", "dash": "solid", "width": 3}})
layout2 = go.Layout(title = 'conversion rate of number of user in different behavior'.title(),
yaxis=dict(title='BehaviorType'))
data2 = [trace2]
fig3 = go.Figure(data=data2,layout=layout2)
fig3.show();
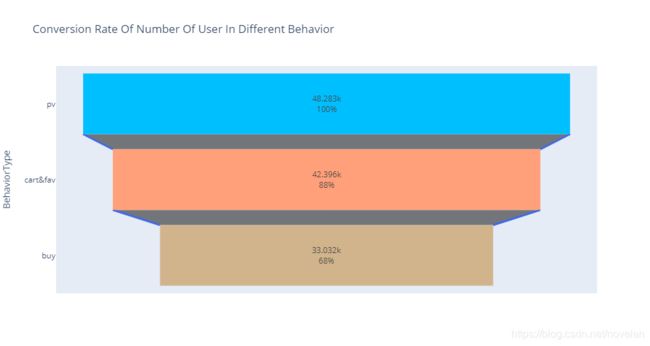
由上图可知,在所有参与商品选购的用户中,有68%的活跃用户都存在完成购买行为,用户付费成交率较高,说明用户存在较强的购买意向;
- 所有浏览过商品的用户,**88%**的用户有加购到购物车或收藏商品的行为,说明多数用户能在平台上找到需要的商品;
- 所有有加购或收藏商品的用户中,有**78%**的用户会完成购买,说明购物车或收藏夹里的商品的购买确定性较高。
# 探索用户的复购率
user_buy_count = valid_df.query('BehaviorType == "buy"').groupby('UserID')['ItemID'].count()
rebuy_rate = (user_buy_count >= 2).mean()
rebuy_rate
0.6533967062242674
小结
- 从行为总数转化率来看,总体行为转化率为2%,其中由浏览转化为加入购物车或收藏行为是整个选购中行为流失量最多、转化最困难的环节,所以该阶段应为整个过程的关键夹点,需要在此环制定针对性的运营策略从而提高转化率。
- 88%的用户能在淘宝上浏览到需要的商品,而且68%的用户都完成了购买,说明淘宝能够满足大部分用户的购物需求和解决其购物痛点。
用户行为偏好探索
探索用户的行为模式,从时间日期、商品种类等因素探索用户的行为偏好和模式
日期时间维度
pv_log = valid_df[['UserID','BehaviorType','Date','DayofWeek','Hour']].query('BehaviorType == "pv"')
日期维度
total_pv_day = pv_log.groupby(['Date','DayofWeek'])['UserID'].count()
total_uv_day = pv_log.query('BehaviorType == "pv"').groupby(['Date','DayofWeek'])['UserID'].nunique()
ticklabels = [(str(date)+' '+str(dayofweek)) for date,dayofweek in total_pv_day.index]
fig,ax1 = plt.subplots(figsize=(9,7))
ax1.plot(total_pv_day.values,c='blue',ls='--',lw=1.5,markersize=6,label='pv in diff_day')
ax1.set_xticks(np.arange(len(ticklabels)))
ax1.set_xticklabels(ticklabels)
ax2 = ax1.twinx()
ax2.plot(total_uv_day.values,c='orangered',ls='--',lw=1.5,markersize=6,label='uv of pv in diff_day')
ax1.set_xlabel('Day DayofWeek',size=14)
ax1.set_ylabel('PV',size=14)
ax2.set_ylabel('UV In PV',size=14)
ax1.set_title('Distribution Of PV & UV In Different Day',size=16)
ax1.legend(loc=2)
ax2.legend(loc=9)
fig.autofmt_xdate();

- 相比工作日,用户在非工作日的活跃度更高
- 从2017-12-1起,用户活跃数和浏览量呈大幅增长趋势,特别是在2017-12-2两个指标骤增
- 从12月开始呈现大幅增长趋势的现象的原因:
- 双12的预热活动开启,参考信息来源
- 12月2日较12月1日有明显增长,是因为非工作日人们有更多的时间和精力参与双12的选购活动
- 从12月开始呈现大幅增长趋势的现象的原因:
时间维度
# 时间维度
avg_pv_in_hour = pv_log.groupby(['Hour','Date'])['UserID'].count().reset_index().groupby('Hour')['UserID'].mean()
avg_uv_in_hour = pv_log.groupby(['Hour','Date'])['UserID'].nunique().reset_index().groupby('Hour')['UserID'].mean()
fig,ax1 = plt.subplots(figsize=(9,7))
plt.grid(True,ls='-.')
ax1.plot(avg_pv_in_hour,c='blue',ls='-',lw=1.5,markersize=6,label='avg pv in diff_hour')
ax2 = ax1.twinx()
ax2.plot(avg_uv_in_hour,c='orangered',ls='-',lw=1.5,markersize=6,label='avg uv of pv in diff_hour')
ax1.set_xticks(np.arange(0,24))
ax1.set_xticklabels(np.arange(0,24),rotation=90)
ax1.set_xlabel('Hour',size=14)
ax1.set_ylabel('Avg Of PV',size=14)
ax2.set_ylabel('Avg of UV In PV',size=14)
ax1.set_title('Distribution Of Avg Of PV & UV In Different Hour',size=16)
ax1.legend(loc=2)
ax2.legend(loc=9);
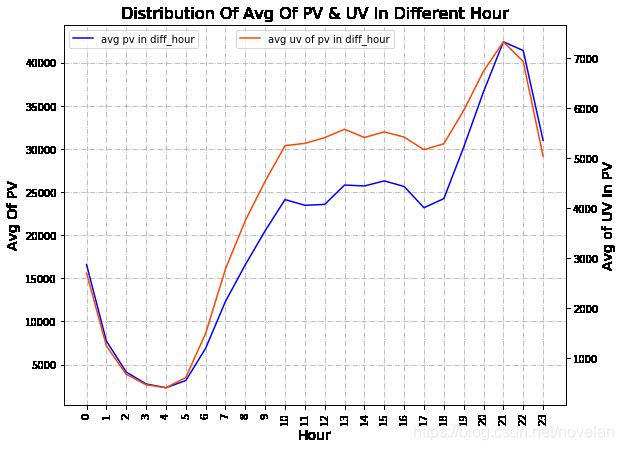
平均用户数量和平均用户浏览量在一天内各个时段的分布存在如下特征:
- 10:00-18:00,UV基本稳定在5000-5500,PV基本稳定在25000上下,两个指标在该时间段内的数值差异不大;
- 18:00后,UV和PV有明显增速的趋势,直到21:00达到一天内的最大值,UV达到7500左右,PV达到45000,UV增长率高达44%,PV增长率高达80%;
- 22:00后,虽然UV和PV仍维持在较高位,但是均已呈现快速下降趋势,直至4:00达到最低值,UV低至500左右,PV低至2500左右,降速均达到90%
小结
不管是平台运营人员还是网站入驻的商家,应该充分把握黄金时段,如每周非工作日、每天的18:00-22:00和特殊的购物节,开展促销、上新或其他运营活动
商品种类维度
- 不同的商品种类之间是否存在较大的购买量差异?如果存在较大差异,继续探索下面三个问题。
- 哪些种类的商品兼具高浏览量和高购买量?
- 哪些种类的商品虽然没有较高的活跃度但是付费成功率较高,购买率较高?
- 哪些种类的商品虽然有较高的活跃度,但是付费成功率较低,购买率较低?
item_cat_bh_counts = pd.pivot_table(valid_df \
.groupby(['CategoryID','BehaviorType'])['UserID'] \
.count().reset_index(name='count'),
values='count',
index='CategoryID',
columns='BehaviorType')
item_cat_bh_counts.fillna(0,inplace=True)
item_cat_bh_counts['cart&fav'] = item_cat_bh_counts.cart + item_cat_bh_counts.fav
item_cat_bh_counts.drop(['cart','fav'],axis=1,inplace=True)
item_cat_bh_counts.head()
| BehaviorType | buy | pv | cart&fav |
|---|---|---|---|
| CategoryID | |||
| 2171 | 5.0 | 130.0 | 11.0 |
| 2410 | 0.0 | 18.0 | 1.0 |
| 3579 | 0.0 | 1.0 | 0.0 |
| 4907 | 0.0 | 14.0 | 3.0 |
| 5064 | 18.0 | 1254.0 | 158.0 |
探索不同商品种类的购买量是否较大的差异
buycounts_cat = item_cat_bh_counts['buy'].sort_values(ascending=False)
buycounts_cat_df= buycounts_cat.reset_index(name='Purchases')
buycounts_cat_df['cumsum_purchases'] = buycounts_cat_df['Purchases'].cumsum(axis=0)
buycounts_cat_df['cumsum_purchases_pct'] = buycounts_cat_df.cumsum_purchases/buycounts_cat_df.Purchases.sum()
cat_counts_pct = np.around(np.linspace(0,len(buycounts_cat.index),num=10)/len(buycounts_cat.index),2)
fig,ax = plt.subplots(figsize=(14,7))
ax.plot('cumsum_purchases_pct',data=buycounts_cat_df)
ax.set_xticks(np.linspace(0,len(buycounts_cat.index),num=10))
ax.set_xticklabels(cat_counts_pct)
ax.set_xlabel('percent of category counts'.title(),size=12)
ax.set_ylabel('purchases'.title(),size=12)
ax.set_title('category vs purchases'.title(),size=14)
ax.hlines(0.8,0,8000,'r',ls='--')
ax.vlines(653,0,1,'r',ls='--');

不同商品种类的购买量存在严重的二八差异,不足10%的商品种类贡献了80%的购买量,超过90%的商品种类的购买量仅占10%
# 哪些商品种类的购买量较多
top10_buycounts_cat = buycounts_cat_df[['CategoryID','Purchases']].head(10)
# 可视化购买量在Top10的商品种类
labels = top10_buycounts_cat['CategoryID'].values
values = top10_buycounts_cat.Purchases.values
colors = ['darkorange','orange','gold','yellow','khaki','green','forestgreen','limegreen','lightgreen','mediumspringgreen']
fig = go.Figure(data=[go.Pie(labels=labels,values=values)],
layout=go.Layout(title = 'Top10 Purchases in different category'.title()))
fig.update_traces(hoverinfo='label', textinfo='value', textfont_size=20,
marker=dict(colors=colors,line=dict(color='white', width=1)))
fig.show()
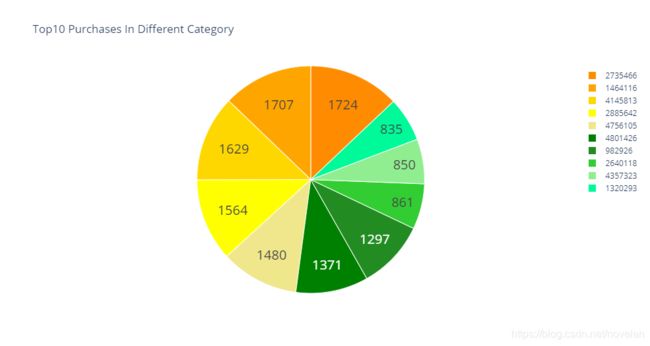
探索购买总次数在top20的商品种类在浏览次数的分布
top20_buycounts = item_cat_bh_counts.sort_values(['buy'],ascending=False)[:20]
top20_buycounts_catid = [str(x) for x in top20_buycounts.index.tolist()]
fig,ax = plt.subplots(figsize=(14,7))
ax.bar(top20_buycounts_catid,top20_buycounts['buy'],color='blue',alpha=0.5,edgecolor='black',label='buy',lw=1.75)
plt.grid(axis='y')
ax2 = ax.twinx()
ax2.bar(top20_buycounts_catid,top20_buycounts['pv'],color='red',alpha=0.5,label='pv')
ax.set_xticks(np.arange(len(top20_buycounts_catid)))
ax.set_xticklabels(top20_buycounts_catid)
ax.set_xlabel('Category ID',size=12)
ax.set_ylabel('total amount of buy'.title(),size=12)
ax2.set_ylabel('toal amount of page view'.title(),size=12)
ax2.set_ylim(0,250000)
ax.set_title('chart1: Top 20 purchases vs PV in category'.title(),size=16)
ax.legend(loc=2)
ax2.legend(loc=4)
fig.autofmt_xdate();
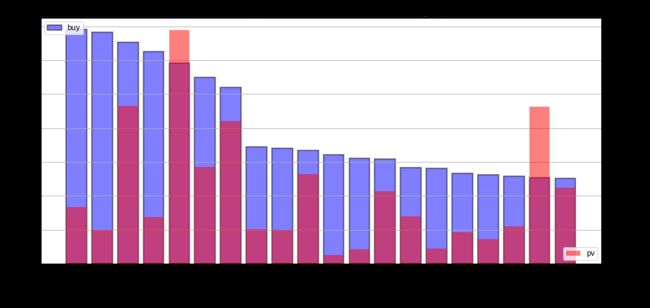
探索浏览总次数在top20的商品种类在购买次数的分布
top20_pvcounts = item_cat_bh_counts.sort_values(['pv'],ascending=False)[:20]
top20_pvcounts_catid = [str(x) for x in top20_pvcounts.index.tolist()]
fig,ax = plt.subplots(figsize=(14,7))
ax.bar(top20_pvcounts_catid,top20_pvcounts['pv'],color='red',alpha=0.5,label='pv',edgecolor='black',lw=2)
ax2 = ax.twinx()
ax2.bar(top20_pvcounts_catid,top20_pvcounts['buy'],color='blue',alpha=0.5,label='buy')
ax.set_xticks(np.arange(len(top20_pvcounts_catid)))
ax.set_xticklabels(top20_pvcounts_catid)
ax.set_xlabel('Category ID',size=12)
ax.set_ylabel('total amount of page view'.title(),size=12)
ax2.set_ylabel('toal amount of buy'.title(),size=12)
ax.set_ylim(0,250000)
ax.legend(loc=2)
ax2.legend(loc=4)
ax.set_title('chart2: Top 20 page views vs purchases category'.title(),size=16)
fig.autofmt_xdate()
plt.grid(True);

小结
从上图分析可知,用户是否购买一件商品受到多方面因素的影响,如商品属性(刚需、可选消费、特殊)、平台图片展示、口碑、质量
- 哪些种类的商品兼具高浏览量和高购买量?
- 4756105、4145813、982826
- 哪些种类的商品虽然没有较高的活跃度但是付费成功率较高,购买率较高?
- 1464116、2735466、2885642
- 哪些种类的商品虽然有较高的活跃度,但是付费成功率较低,购买率较低?
- 2355072、3607361
具体商品销量的排名
探索不同商品的销量是否存在较大差异,如有,哪些商品的购买次数较多
item_buycounts = valid_df.query('BehaviorType == "buy"').groupby('ItemID')['UserID'].count()
buycounts_item_df = item_buycounts.sort_values(ascending=False).reset_index(name='Purchases')
buycounts_item_df['cumsum_purchases'] = buycounts_item_df['Purchases'].cumsum(axis=0)
buycounts_item_df['cumsum_purchases_pct'] = buycounts_item_df.cumsum_purchases/buycounts_item_df['Purchases'].sum()
item_counts_pct = np.around(np.linspace(0,len(item_buycounts.index),num=10)/len(item_buycounts.index),2)
fig,ax = plt.subplots(figsize=(14,7))
ax.plot('cumsum_purchases_pct',data=buycounts_item_df)
ax.set_xticks(np.linspace(0,len(item_buycounts.index),num=10))
ax.set_xticklabels(item_counts_pct)
ax.set_xlabel('percent of item counts'.title(),size=12)
ax.set_ylabel('purchases'.title(),size=12)
ax.set_title('items vs purchases'.title(),size=14);
ax.hlines(0.8,0,len(item_buycounts.index)+10,'r',ls='--')
ax.vlines(buycounts_item_df[buycounts_item_df.cumsum_purchases_pct >= 0.8].head(1).index.values[0],0,1,'r',ls='--');
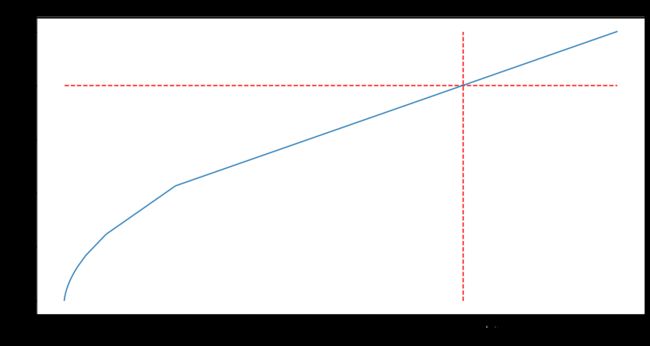
不同商品的销量没有存在较大的差异,其中75%的商品贡献了80%的销量,其依靠的是长尾理论累计销售,而不是制造爆款商品来带动销量。
挖掘用户价值,发掘高价值用户
分析哪些用户购买次数较多,哪些用户复购率较高,探索此类用户对哪些种类的商品购买次数较多,根据用户行为偏好为其推荐个性化的商品
# 按照user分组统计每个用户购买次数
user_buycounts = valid_df.query('BehaviorType == "buy"').groupby('UserID')['UserID'].count()
# 计算购买次数超过1次的用户数量占购买总用户数的百分比
repay_rate = (user_buycounts >= 2).mean()
repay_rate
0.6533967062242674
在购买用户中,有65%的用户有复购行为,即在所有活跃用户中有超过44%的用户在该平台购买次数超过1次。
# 按照每个用户的购买次数从大到小降序排序,获取复购率最高的用户
user_buycounts.sort_values(ascending=False).iloc[:10]
UserID
537150 109
524735 82
508672 69
526437 60
523342 60
315769 60
529478 52
486585 50
395683 43
508743 43
Name: UserID, dtype: int64
从上面执行结果可以看出,UserID为537150的用户的购买次数最多,其购买次数达到109次。以复购次数最多用户为例,探索该用户在不同商品类别的购买次数分布
user_537150_log = valid_df.query('UserID == "537150" and BehaviorType == "buy"')
top10_cats_of_user537150 = user_537150_log.groupby(['CategoryID'])['ItemID'].count().sort_values(ascending=False).iloc[:10]
top10_cats_of_user537150
CategoryID
1879194 14
4242717 11
982926 7
384755 5
4915680 4
4148053 4
2520771 3
1859277 3
2885642 3
903809 3
Name: ItemID, dtype: int64
fig,ax = plt.subplots(figsize=(10,6))
ax.bar([str(catid) for catid in top10_cats_of_user537150.index.tolist()],
top10_cats_of_user537150.values)
ax.set_xlabel('CategoryID',size=12)
ax.set_ylabel('BuyCounts',size=12)
ax.set_title('Top10 BuyCounts Of Category Of UserID:537150 ',size=14);
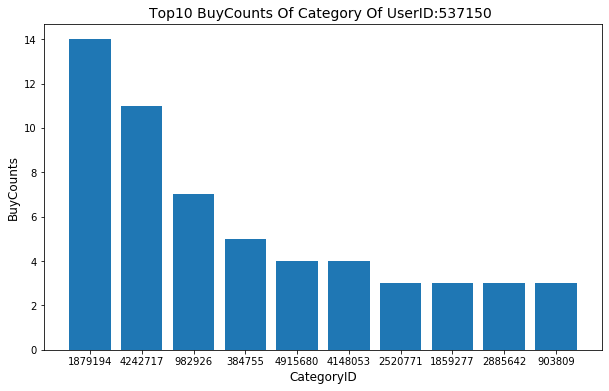
如上面结果所示,UserID为537150的用户,其购买的商品类别主要集中在前三类,如要推荐其他商品给该用户,可以将这三类的所有产品按照产品销量进行排序,选择销量高,复购率高,口碑好的,该用户没有浏览过的产品进行推荐,从而挖掘更多的用户价值。
结论
通过以上四个方面的探索性分析,并结合以上业务指标,从AARRR用户生命周期的五个方面进行总结和建议:
用户获取(Acquisition)
实现产品与渠道的匹配
- 淘宝网具有较大的流量规模和用户基数,高日活量和低跳出率说明淘宝同时也存在较好的用户体验和较强的用户粘性,人们能在淘宝上解决其大部分的购物需求,所以淘宝俨然已成为人们目前的主要购物平台。在这一现状下,淘宝继续获取用户的较好方式应为用户推荐,淘宝可以充分利用现有的用户规模,采用多种推荐方式来吸取更多的用户。
- 通过用户行为偏好的探索发现,非工作日和每天的18:00-22:00是用户使用平台的高峰期,所以平台应尽可能在选择这些时间段开展运营活动,比如建议各大商家的促销上新时间定在这个时间段内,并在这个时间段内设置多种邀请触发机制,如增加弹窗、开展需要邀请好友的互动小游戏、开展好友拼单拼团活动。为了进一步激发用户推荐的动力,最好设置一些有偿型的补贴推荐方式,如成功邀请好友能够获取购物代金券等。
用户激活(Activation)
理解产品的“Aha时刻”,通过多种渠道推动用户到达“Aha时刻”。根据到达“Aha时刻”的路径转化问题,确定关键夹点位置,提供针对性的运营策略。
- 作为购物平台,将用户完成一次购物行为的用户体验作为“Aha”时刻,但本项目整个选购行为的总体转化率仅为2%,其中由浏览转化为加入购物车或收藏行为是整个选购中行为流失量最多(流失90%的行为数)、转化最困难的环节,所以将该阶段确定为整个过程的关键夹点。
- 浏览行为流失严重,说明用户在选择、搜索商品时花费了大量的时间和精力,也可能是用户在确定购买意向的过程中,需要通过大量的商品比对、查看商品详情和评价才能确定购买意向,针对这种情况提出以下建议:
- 优化用户个性化推荐机制,根据用户近期的消费记录、搜索记录和平台现有的商品数据,精准地推荐用户可能喜欢的高质量产品。
- 设置优选商品机制,对平台上每一个商品设置打分机制,结合推荐机制推荐评分较高的商品。
- 优化平台搜索引擎机制,增加关键词的准确率
- 增加同类商品比较的功能,如采用卡片式图片展示,下滑沉浸式体验让用户能够快速地一览无遗地进行商品比对
用户留存(Retention)
让用户养成习惯,对平台产生依赖感,增强用户粘性是提升用户留存率的关键,针对让用户到达“习惯时刻”,提出以下建议:
- 制定高频率个性化的移动推送方案,比如及时推送关注店铺的上新促销活动、推送大型的促销活动等消息
- 定期/不定期开展秒杀、1元抢购和大型促销的活动,并结合第一点及时推送提醒用户
- 实行积分制,如可以根据活跃频率、活跃时间、购买次数和购买金额领取一定的积分,积分可以在购买商品时当做现金券使用
- 设置等级会员制,根据购买频率和购买金额满足一定的条件可以成为某一等级的会员,不同等级的会员设置享有不同的优惠程度
用户变现(Revenue)
提高用户的付费成交转化率、复购率及对各大产品类目的购买率
- 从独立用户在各个行为上的人数转化漏斗分析可知,在所有活跃用户中,有68%的用户有购买行为,而在所有购买用户中,有65%的用户有复购行为,即在所有活跃用户中有超过44%的用户在该平台购买次数超过1次,所以淘宝的用户付费成交率相对较高,用户存在着较强的购买意向,所以在本平台上关键还是优化解决第二部分“用户激活”关键位置的转化率问题。
- 在商品种类的购买量分布上,不同种类之间存在着较大的购买量差异,不足10%的商品种类贡献了80%的购买量,超过90%的商品种类的购买量仅占10%,这更多的取决于不同种类商品的消费属性和消费周期。但具体到单个商品的销量分布上,平台上75%的商品贡献了80%的销量,区别于线下零售行业的“二八”模式,其依靠的是长尾理论累计销售,而不是制造爆款商品来带动销量。据我们所知,电商平台天生具有时空限制小的优势,能够利用互联网技术,大范围大面积地曝光商品,平台上商品种类和类目非常地丰富多样,能够满足人们各种多样化需求。所以应继续保持这一优势,优化平台推荐机制,更加精准个性化针对用户推荐其可能喜欢的产品。
- 针对复购率高的价值用户,需要进一步加大对其的奖励程度,个性化推荐和推送,保持其高频的购买行为。
用户推荐(Recommend)
如上,淘宝可以利用庞大的用户基础,通过用户之间的互相推荐达到整体增长的良性循环。可采取的推荐方式如下:
- 开启好友拼单拼团活动;
- 补贴推荐,如成功邀请好友可获取购物代金券
- 与大型社交直播平台合作,利用短视频或者直播的方式推荐商品
- 在产品内部实行多种动态的邀请机制增加接触到邀请机会的比例
实行以上方案后应跟踪推荐方案的转发率、转化率、K因子等指标来实时监测方案的有效性