TensorRT 简介
文章目录
- 1、简介
- 2、生态系统
- 3、开发流程
- 4、使用步骤
- 5、build阶段
-
- 5.1、算子融合详解
-
- GoogLeNet为例
- Conv+BN+Relu融合
- 5.2、INT8量化
-
- 定义
- 基本知识
- 阈值选择
- 交叉熵
- 具体步骤
- 阈值计算
- 校准算法
- 6、总结
- 7、参考资料
1、简介
- TensorRT是用于优化训练后的深度学习模型以实现高性能推理的SDK。
- TensorRT包含用于训练后的深度学习模型的深度学习推理优化器,以及用于执行的runtime。
- TensorRT能够以更高的吞吐量和更低的延迟运行深度学习模型。
- TensorRT is a high-performance neural network inference optimizer and runtime engine for production deployment.
2、生态系统
TensorRT的生态系统包含两部分:转换(Convesion)与部署(Deployment)
1、转换(Convesion)
- 用户可以遵循的各种路径将其模型转换为优化的TensorRT引擎。

2、部署(Deployment)
- 部署优化的TensorRT引擎时,各种runtime用户可以使用TensorRT到不同的目标平台

3、开发流程

-
Inputs:可以输入多种类型的模型框架。
-
Network definition :TensorRT中模型的表示。 网络定义是张量和运算符的图。
-
Optimization Parameters:对Batch Size 与Precision进行设定。
推理时,当优先考虑延迟时选择小的batch,而优先考虑吞吐量时选择较大的batch。 较大的batch需要更长的处理时间,但可以减少每个sample的平均时间。
推理通常需要比训练少的数字精度。 较低的精度可以在不牺牲的精度的情况下提供更快的计算速度和更低的内存消耗。 TensorRT支持TF32,FP32,FP16和INT8精度。
-
Builder :TensorRT的模型优化器。 构建器将网络定义作为输入,执行与设备无关和针对特定设备的优化,并创建引擎。
-
Engine :由TensorRT构建器优化的模型的表示,可以对模型进行序列化。
-
Plan(Bytes) :序列化格式的优化后的推理引擎。 典型的应用程序将构建一次引擎,然后将其序列化为计划文件以供以后使用。要初始化推理引擎,应用程序将首先从plan文件中反序列化模型。
-
Runtime :TensorRT的组件,可在TensorRT引擎上执行推理。
两种类型的runtime:C++和Python绑定的独立的runtime,以及与TensorFlow的原生集成的runtime。
4、使用步骤
- 根据模型创建TensorRT的网络定义(ONNX、wts等)。
- 调用TensorRT构建器以从网络创建优化的runtime引擎。
- 序列化和反序列化引擎,以便可以在runtime快速重新创建它。
- 向引擎提供数据以执行推理。
5、build阶段
-
为了优化推理模型,TensorRT会采用你的网络定义,执行包括平台特定的优化,并生成推理引擎。 此过程称为build阶段。
-
build阶段可能会花费大量时间,尤其是在嵌入式平台上运行时。 因此,典型的应用程序将只构建一次引擎,然后将其序列化为plan文件以供以后使用。
-
构建阶段对图执行以下优化:
- 算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速。
- 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度。
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式。
- 动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作。
上述的这些算子融合、动态显存分配、精度校准、多steam流、自动调优等操作,TensorRT都帮你做了。这样通过TensorRT帮你调优模型后,自然模型的速度就上来了。
5.1、算子融合详解
GoogLeNet为例
TensorRT的这些优化策略代码虽然是闭源的,但是大部分的优化策略我们或许也可以猜到一些,也包括TensorRT官方公布出来的一些优化策略:

(1)左上角是原始网络(googlenet),
(2)右上角相对原始层进行了垂直优化,将conv+bias(BN)+relu进行了融合优化;
(3)而右下角进行了水平优化,将所有1x1的CBR融合成一个大的CBR;
(4)左下角则将concat层直接去掉,将contact层的输入直接送入下面的操作中,不用单独进行concat后在输入计算,相当于减少了一次传输吞吐;
Conv+BN+Relu融合
BN层往往用在深度神经网络的卷积层之后、激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。
借一下Pytorch官方文档中的BN公式简单回顾一下:
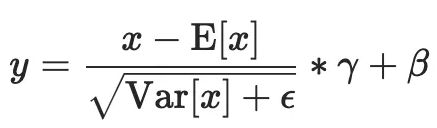
上述的式子很简单,无非就是减均值除方差(其实是标准差),然后乘以一个权重加上一个系数,其中权重和系数是可以学习的,在模型forward和backward的时候会进行更新。
BN层在推理的时候也只需要之前训练好固定的参数:均值 、方差 、权重 以及偏置,假设上一层卷积的输出为 w ∗ x + b w*x + b w∗x+b,将其带入上述的x中(上一层的输出就是这一层的输入)有:
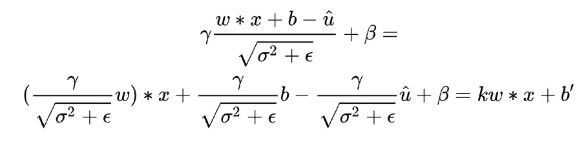
对于最后的w、x和偏置b,发现只需要将卷积权重缩放一定倍数,并对偏置进行一定变化,就可以将BN层的参数融合进Conv中了。这就相当于两次线性变化,两个线性变化是可以叠加融合的。
融合后的Conv+BN就相当于一个Conv了,因为大部分网络结构中Conv+BN这样的组合很多,所以一般来说仅仅是这个融合操作就可以使模型加速10%左右。
而一般的ReLU函数可以通过if-else与取max方式实现,因此整合起来不算很难。
在利用TensorRT进行模型解析时,比如从ONNX中解析成TensorRT的网络结构,会提前对BN层的一些操作进行合并和融合。
5.2、INT8量化
定义
训练好的模型权重一般都是FP32也就是单精度浮点型,在深度学习训练和推理的过程中,最常用的精度就是FP32。当然也会有FP64、FP16、BF16、TF32等更多的精度:

对于浮点数来说,指数位表示该精度可达的动态范围,而尾数位表示精度。
- FP32 是单精度浮点数,用8bit 表示指数,23bit 表示小数;
- FP16半精度浮点数,用5bit 表示指数,10bit 表示小数;
- BF16是对FP32单精度浮点数截断数据,即用8bit 表示指数,7bit 表示小数。
- TF32 是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10 bits,而指数位仍为 8 bits,总长度为 19 (=1 + 8 + 10) bits。
1、FP32->FP16
从FP32->FP16由于部分精度丢失,模型的精度也会下降一些。其实从FP32->FP16几乎是无损的(CUDA中使用__float2half直接进行转换),不需要calibrator去校正、更不需要retrain。
而且FP16的精度下降对于大部分任务影响不是很大,甚至有些任务会提升。NVIDIA对于FP16有专门的Tensor Cores可以进行矩阵运算,相比FP32来说吞吐量直接提升一倍,提速效果明显!

2、FP32->INT8
实际点来说,量化就是将我们训练好的模型,不论是权重、还是计算op,都转换为低精度去计算。因为FP16的量化很简单,所以实际中谈论的量化更多的是INT8的量化。
经过INT8量化后的模型:
- 模型容量变小了,这个很好理解,FP32的权重变成INT8,大小直接缩了4倍
- 模型运行速度可以提升,实际卷积计算的op是INT8类型,在特定硬件下可以利用INT8的指令集去实现高吞吐,不论是GPU还是INTEL、ARM等平台都有INT8的指令集优化
- 对于某些设备,使用INT8的模型耗电量更少,对于嵌入式侧端设备来说提升是巨大的
所以说,随着我们模型越来越大,需求越来越高,模型的量化自然是少不了的一项技术,但是FP32与INT8之间范围相差太大,不能直接进行类型转换,否则会造成很大的类型损失。

基本知识

- 两种精度的数据进行变换,首先考虑最简单的线性量化的方式。
- FP32 的 bias 对精度影响不大,可以直接舍去,最终得出两者之间成正比的关系。即对于所有的INT8 只需要1个FP32的缩放因子。

- 2种量化方式(Saturation:饱和)
- 1:不饱和量化:直接量化,大范围等比压缩,但是会明显地损失精度。
- 2:设置阈值,只将阈值左右两部分进行映射,超过的部分全都只映射为两个端点值(-127~+127),具体还可分为对称量化与非对称量化。

左边是非对称量化,右边是对称量化(也称为Affine quantization和Scale quantization)。可以观察到:
- 对称量化的实数0也对应着整数的0,而非对称量化的实数0不一定对应着整数0,而是z。
- 对称量化实数的范围是对称的( [ − α , α ] [-\alpha,\alpha] [−α,α]),而非对称量化的则不对称( [ − β , α ] [-\beta,\alpha] [−β,α])
- 对称量化整数的范围是对称的([-127,127]),而非对称量化的则不对称([-128,127])
所以上述的非对称量化过程可以简述为 f ( x ) = s ∗ x + z f(x)=s*x+z f(x)=s∗x+z ,其中z是zero-point,这个数字就代表实数0映射到整数是多少,而对称量化则是 f ( x ) = s ∗ x f(x)=s*x f(x)=s∗x。
即x = 0,直接带入算出来也是0,如果采用的是对称量化,这样算就没问题!
不论是非对称还是对称量化,是基于线性量化(也可以称作均匀量化)的一种。线性量化将FP32映射到INT8数据类型,每个间隔是相等的,而不相等的就称为非线性量化。非线性量化因为对部署并不是很友好,虽然能够更好地捕捉到权重分布的密集点,但感觉用的并不多,这里也就先不多说了。
阈值选择
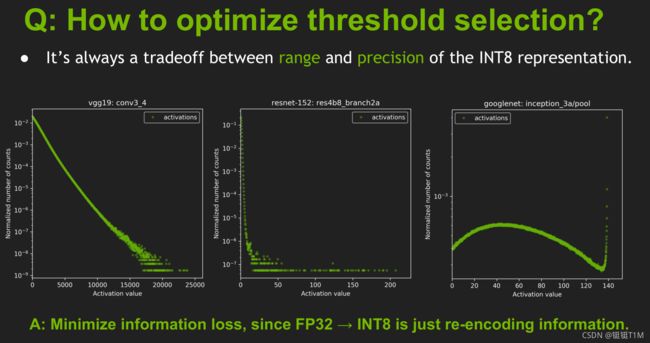
- 阈值(a/T)的选择是范围与精度的权衡
- 横轴是激活值,纵轴是归一化值出现次数
交叉熵

如何定量评估两种精度的差异? —— 考虑两种编码的相对熵(KL散度)
- 两个精度的模型表达的是同样的信息,目的是最小化信息的损失。
- 使用KL散度来衡量FP32与INT8 两个数据分布之间的差异。
具体步骤


解决方案:校准
-
在校准数据数据集上运行FP32推理,校准数据集可以由训练集中抽取一部分图片构成
-
对每一层:
- 收集激活值的直方图分布
- 选择不同的阈值来得到更多的量化分布
- 选择一个可以最小化KL散度的阈值
-
要做INT8量化,需要:
- 原来的未量化的模型
- 一个校准数据集
- 进行量化过程的校准器
-
步骤
- 在校准数据集上以FP32运行推理
- 收集所需数据
- 运行校准算法以优化缩放因子系数
- 最后生成校准表与INT8执行引擎
阈值计算
如何寻找最优的阈值T使得精度的损失最小?
NVIDIA选择的是KL-divergence,其实就是相对熵。相对熵表述的就是两个分布的差异程度,这里就是量化前后两个分布的差异程度。差异最小就是最好的了,因此问题转换为求相对熵的最小值。
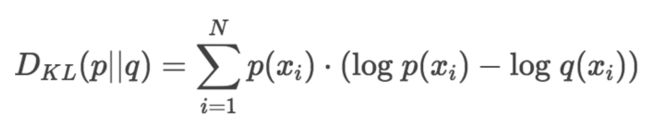
KL散度来精确测量这种最优和次优之间的差异。
FP32就是原来的最优编码,INT8就是次优的编码,用KL散度来描述这两种编码之间的差异。
相对熵表示的是采用次优编码时会多需要多少个bits来编码,也就是与最优编码之间的bit差;
而交叉熵表示的是用次优编码方式时确切需要多少个bits来表示;
因此,最优编码所需要的bits=交叉熵-相对熵。
校准算法
校准(Calibration)算法:基于实验的迭代搜索阈值。
基本步骤:
• 提供一个样本数据集(最好是验证集的子集),称为“校准数据集”,用来做校准。
• 在校准数据集上运行FP32推理。收集激活的直方图,并生成一组具有不同阈值的8位表示法,并选择具有最少KL散度的表示。
KL散度是在参考分布(即FP32激活)和量化分布之间(即INT8量化激活)之间。
TensorRT提供了IInt8EntropyCalibrator,该接口需要由客户端实现,以提供校准数据集和一些用于缓存校准结果的样板代码。

上面就是一个循环,不断地构造P和Q,并计算相对熵,然后找到最小(截断长度为m)的相对熵,此时表示Q能比较好地拟合P分布了。而阈值就等于(m + 0.5)*一个bin的长度。
校准过程我们是不用参与的,全部都由TensorRT内部完成,但是,需要告诉校准器如何获取一个batch的数据,也就是说,需要重写校准器类中的一些方法。
- 准备一个校准集,用于在转换过程中寻找使得转换后的激活值分布与原来的FP32类型的激活值分布差异最小的阈值;
- 写一个校准器类,该类需继承trt.IInt8EntropyCalibrator2父类,并重写get_batch_size, get_batch, read_calibration_cache, write_calibration_cache这几个方法。
- 使用时,需额外指定cache_file,该参数是校准集cache文件的路径,会在校准过程中生成,方便下一次校准时快速提取。
优化前后阈值的变化

6、总结
TensorRT优缺点?
-
优点:
-
量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
-
算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速。对于网络结构进行了重构和优化,主要体现在一下几个方面。
(1) TensorRT通过解析网络模型将网络中无用的输出层消除以减小计算。
(2) 对于网络结构的垂直整合,即将目前主流神经网络的Conv、BN、Relu三个层融合为了一个层,例如将图1所示的常见的Inception结构重构为图2所示的网络结构。
(3) 对于网络结构的水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,例如图2向图3的转化。
-
内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
-
动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
-
多流执行:使用CUDA中的stream技术,最大化实现并行操作
-
-
“缺点”:
- 经过infer优化后的模型与特定GPU绑定,例如在1080TI上生成的模型在2080TI上无法使用;
- 高版本的TensorRT依赖于高版本的CUDA版本,而高版本的CUDA版本依赖于高版本的驱动,如果想要使用新版本的TensorRT,更换环境是不可避免的;
- TensorRT尽管好用,但推理优化infer还是闭源的,像深度学习炼丹一样,也像个黑盒子,使用起来会有些畏手畏脚,不能够完全掌控。所幸TensorRT提供了较为多的工具帮助我们调试。
7、参考资料
内卷成啥了还不知道TensorRT?超详细入门指北,来看看吧!
不看必进坑~不论是训练还是部署都会让你踩坑的Batch Normalization
必看部署系列~懂你的神经网络量化教程:第一讲!
YOLOv5(PyTorch)目标检测实战:TensorRT加速部署