学习笔记:Two-Stage Peer-Regularized Feature Recombination for Arbitrary Image Style Transfer
[CVPR-2020] Two-Stage Peer-Regularized Feature Recombination for Arbitrary Image Style Transfer 任意图像风格迁移的两阶段对等正则化特征重组
- 摘要
- 1. 概述
-
- 1.1 背景
- 1.2 局限性
- 2. 方法
-
- 2.1 整体架构
- 2.2 两阶段对等正则化特征重组
- 3. 实验
-
- 3.1 定性比较
- 3.2 零样本风格迁移
- 3.3 消融实验
- 4. 总结
论文链接:https://arxiv.org/abs/1906.02913
摘要
本文介绍了一种神经风格迁移模型,通过一组描述所需风格的示例来生成风格化图像。提出的解决方案即使在零样本设置下也能产生高质量的图像,并允许在内容几何上有更多的自由变化。这是通过引入一个新的两阶段对等正则化层(TwoStage Peer-Regularization Layer)实现的,该层通过一个自定义的图形卷积层在潜在空间中重新组合风格和内容。与绝大多数现有解决方案相反,本文的模型不依赖于任何预先训练的网络来计算感知损失,并且由于一组新的循环损失直接在潜在空间中操作,而不是在RGB图像上,因此可以完全端到端地进行训练。一项广泛的消融研究证实了提出的损失和两阶段对等正则化层的有效性,其定性结果与目前对所有呈现风格使用单一模型的技术水平相比具有竞争力。这为更抽象和艺术的神经图像生成场景,以及更简单的模型部署打开了大门。
1. 概述
1.1 背景
-
神经风格迁移(NST)是目前的一个研究领域,它专注于研究如何构建模型,这些模型可以转换输入图像(或视频)的视觉外观模型,以匹配所需目标图像的风格。例如,用户可能希望将给定的照片转换为仿佛梵高画过的场景。
-
神经风格迁移在深度学习领域取得了巨大的发展,并跨越了多种应用,例如艺术品和照片之间的映射,面部表情迁移,转换动物种类等。
1.2 局限性
尽管目前的NST方法很受欢迎,而且通常得到高质量的结果,但它也存在局限性:
-
首先,当前的NST方法在每次迁移的过程都需要一个新的优化过程,这对于许多实际场景来说是不切实际的;
-
另外,他们的方法在很大程度上依赖于预训练的网络,通常是从分类任务中借用的,这些网络已知是次优的,并且最近被证明偏向于纹理而不是结构;
-
当使用神经网络克服该方法的计算负担时,由于传统模型在将多种风格编码到网络的权重方面的能力有限,因此需要针对每个所需的风格图像训练模型。
2. 方法
本文提出一种神经风格迁移模型,即使在零样本设置下也可以产生高质量的图像,并且在更改内容几何形状时具有更大的自由度。这是通过引入一个两阶段对等正则化层(Two Stage Peer-Regularization Layer)来实现的,该层通过自定义图卷积层将潜在空间中的风格和内容重新组合在一起。与绝大多数现有的方法不同,模型不依赖于任何预训练网络来计算感知损失,并且直接在潜在空间进行循环损失优化,因此可以完全端到端地进行训练。
2.1 整体架构
本文的核心思想是基于区域的机制,在输入和目标风格图像之间交换风格,同时保留语义内容。我们通过度量学习将风格和内容信息在潜在空间中分离,使得解码器中保留的风格信息量大大减少。为了解决绑定到某种风格的内容的几何变化,我们将风格迁移建模为两个阶段的过程,第一阶段进行风格转换,第二阶段再进行相应内容几何结构的修改。
该体系结构包含一个编码器模块和两个解码器模块。黄色模块被训练为自动编码器(AE)以重建输入。而绿色模块训练被训练为GAN,以使用来自带有固定参数的黄色模块的编码器来生成输入的风格化版本。两个模块的优化与判别器交错在一起,虚线表示缺乏梯度传播。
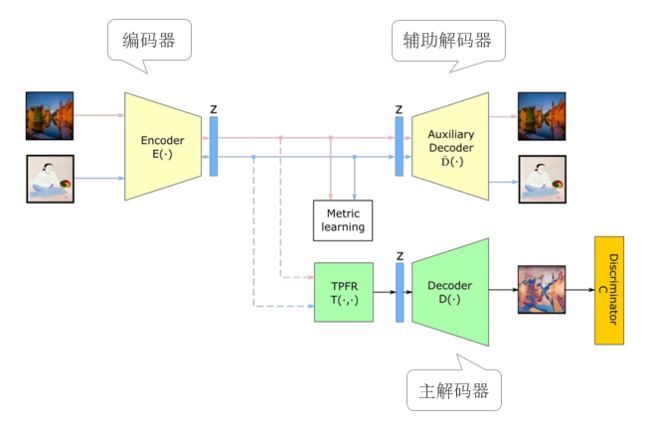
2.1.1 编码器
编码器用于生成所有输入图像的潜在表示,由几个下采样的卷积层和多重ResNet模块组成。
生成的潜码由两部分组成:内容部分和风格部分,内容部分保存关于图像内容的信息(例如位置、大小等),风格部分编码内容所呈现的风格(例如层次细节、形状等信息)。再对风格部分进行均等分:glob通过一个小的子网络进行进一步的下采样,然后生成每个特征图的单个值,loc对每个特征图的每个像素的局部风格信息进行编码。

2.1.2 辅助解码器
辅助解码器根据其潜在表示重构图像,并且仅在训练期间用于训练编码器模块。它由几个ResNet模块和小步幅卷积层组成的,以重建原始图像。为了防止主解码器对其权重进行风格化编码,在训练过程中使用辅助解码器分别对编码器和解码器的参数进行优化。
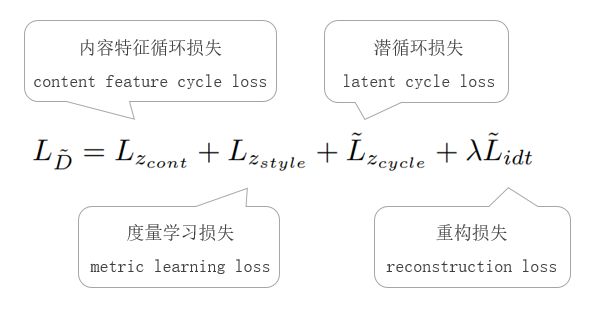
辅助解码器的损失由以下部分组成:
-
内容特征循环损失:目的是让编码器得到的潜码能够将相同内容的潜码聚合在一起;
-
度量学习损失:度量学习的目的是通过训练和学习,减小或限制同类样本之间的距离,同时增大不同类别样本之间的距离;
-
潜循环损失:保证输入的潜码和重构图像的潜码一致;
-
重构损失:使模型学习其输入的完美重构。
2.1.3 主解码器
主解码器复制辅助解码器的架构,并使用两阶段对等正则化特征重组(TPFR)模块的输出作为输入。在主解码器的训练过程中,编码器要保持固定。
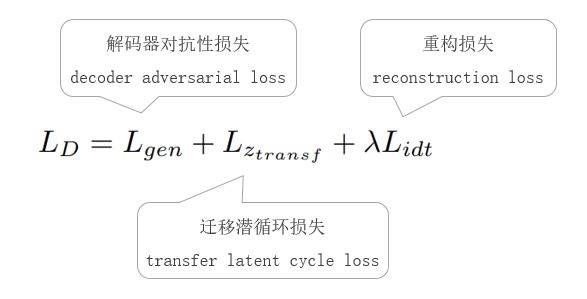
主解码器的损失由以下部分组成:
-
解码器对抗性损失:目的是提高生成图的判别分数,生成图和真实风格图的风格越像,分数就越高;
-
迁移潜循环损失:在保留潜码内容部分的同时,重新组合潜码的风格部分来代表目标风格类。为了让风格化的图像能够既保留内容图的 latent code ( z z zc 部分),又能够保留风格图的 latent code ( z z zs 部分);
-
重构损失:和辅助解码器一样。
latent code(潜码、潜在表示)简单理解就是,为了更好的对数据进行分类或生成,需要对数据的特征进行表示,但是数据有很多特征,这些特征之间相互关联,耦合性较高,导致模型很难弄清楚它们之间的关联,使得学习效率低下,因此需要寻找到这些表面特征之下隐藏的深层次的关系,将这些关系进行解耦,得到的隐藏特征,即latent code。由latent code组成的空间就是latent space(潜在空间)。
2.1.4 判别器
判别器是一个卷积网络,接收在通道维度上连接的两个图像并生成N×N的预测图。 第一个图像是要判别的图像,而第二个图像用作风格类的条件。如果两个输入来自相同的风格类,则理想的输出预测为1,否则为 0。
判别器的损失定义为:
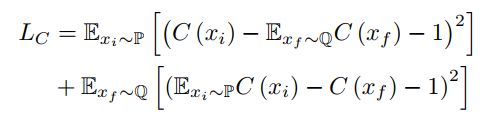
2.1.5 总损失
本文的网络可以交替的对编码器,辅助解码器,主解码器以及判别器进行端到端的迭代优化训练。总损失由以下部分组成:

2.2 两阶段对等正则化特征重组
两阶段对等正则化特征重组(TPFR)模块从利用内容和风格信息的分离,在潜在空间中执行风格迁移。对等正则化特征重组分两个阶段完成。
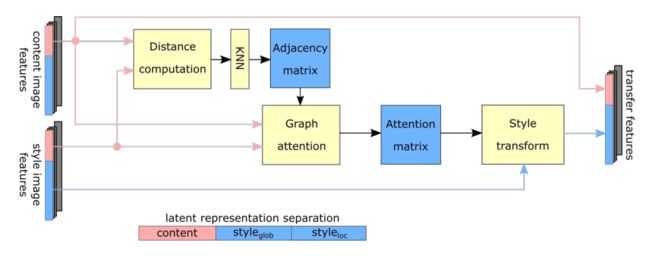
对等正则化的一个步骤是将内容图像和风格图像的潜在表示作为输入。利用潜在表示的内容部分在风格潜在空间上归纳出一个图结构,然后利用该图结构从风格图像的潜在表示中重组内容图像的潜在表示的风格部分,这就产生了一种新的潜码。两阶段对等正则化层执行两次对等正则化操作。在第二步中,内容和风格信息的角色互换。
(1)风格重组
将内容和风格图像的潜在表示( z z zi = [ ( z z zi)C, ( z z zi)S ] 和 z z zt = [ ( z z zt)C, ( z z zt)S ] )作为输入,并利用欧氏距离推导出 ( z z zi)C 和 ( z z zt)C 之间的k-最近邻(k-NN)。计算图节点上的注意力系数,并用于将 ( z z zout)S 的风格部分重新组合为其最近邻表示的凸组合。潜码的内容部分保持不变,输出结果是 z z zout = [ ( z z zi)C, ( z z zout)S ]。
像素的风格部分( z z z)S 的新值表示为:
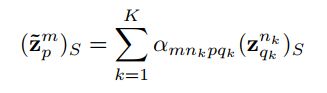
其中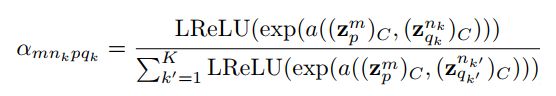
a (·, ·)表示从二维输入到标量输出的全连接层映射
(2)内容重组
重新组合风格潜码后,重复类似的过程,根据新的风格信息转换内容潜码。
在这种情况下,它从输入 z z zout = [ ( z z zi)C, ( z z zout)S ] 和 z z zt = [ ( z z zt)C, ( z z zt)S ] 开始,并在给定风格潜码 ( z z zout)S 、( z z zt)S 的情况下计算k-NN图。将此图与上述公式结合使用,计算注意力系数,并将内容潜码重组为 ( z z zfinal)C。
因此,TPFR模块的输出是一个新的潜码 z z zfinal = [ ( z z zfinal)C, ( z z zout)S ],它重新组合了潜码的风格部分和内容部分。
3. 实验
3.1 定性比较
大多数比较方法都必须为每种风格训练一个新模型,在提供竞争性结果的同时,本文的方法使用单个模型执行任意风格迁移,不需要对每种风格进行重新训练,因此能够迁移以前没见过的风格。
3.2 零样本风格迁移
(a)是在训练过程中没有见过的画家的样本,(b)是使用训练集中画家以前未见过的画作所得到的定性结果。
从图中可以观察到,生成的图像与提供的目标风格一致,并且可以处理非常抽象的绘画风格(图b,第3行,风格1),也能够展现绘画风格的细节(图a,第1行,风格1),结果表明本文的方法具有良好的泛化能力,并且能够实现零样本的风格迁移。
3.3 消融实验
第2行风格迁移的细节显示在最右边的列中
-
NoAux:在训练时不使用辅助解码器,我们观察到直接使用主解码器端到端的训练编码器是不起作用的。在训练过程中使用的辅助解码器是整个方法的核心,它可以有效地防止训练的退化失败;
-
NoSep:在TPFR模块中的特征交换过程中忽略了潜在空间中内容和风格的分离,并一次交换了整个潜码。将潜码分离到内容和风格部分允许引入的两阶段风格迁移,这对于考虑风格的对象形状的变化很重要;
-
NoTS:仅根据内容重新组合风格特征,保留原始内容特征。在某些情况下(例如图中的第1行),仅根据内容特征执行风格迁移完全失败,因此能够得出两阶段重组为各种风格提供了更好的泛化;
-
NoML:不使用度量学习。对风格潜在空间的度量学习加强了其更好的聚类,并增强了风格化图像中的一些细节;
-
NoGlob:不将风格潜码分成全局和局部部分。结合局部和全局风格的潜码很重要,能够适当地考虑边缘和笔触的变化。
4. 总结
本文提出了一种新的神经风格迁移网络:
-
引入一个两阶段对等正则化(TSPR)层,使用自定义的图卷积层,在潜在空间中重新组合风格和内容;
-
提出了一个新的组合损失,从而能够进行端到端的训练,并且无需任何预训练好的模型(如VGG)来进行计算感知损失;
-
为内容和风格信息构建全局和局部组合的潜在空间,并通过度量学习赋予其结构;
因此,本文的方法不仅能够高效实现多种风格的迁移,还能够实现零样本迁移。