实时性能评估框架nn-Meter解读
引言
随着人工智能技术的飞速发展,深度神经网络 (DNN) 模型被广泛应用到各种业务场景下,部署在许多移动端应用上。实际应用时,推理时间 (latency) 是评估模型是否能用、好用的关键指标之一。然而针对巨大的模型设计空间,实测各种设计模型的推理时间成本过高,而现有技术缺乏对部署硬件平台优化策略的理解以及对灵活多变模型架构的泛化性,所以无法做到准确的模型推理时间预测。
在神经结构搜索 (NAS) 、模型剪枝等任务中,如何快速且准确地获取模型在部署后的推理时间是一个十分关键的问题。传统方法对硬件效率的评估大多是基于 FLOPS 来预测的,准确率比较差,原因在于其部署链路过长,且涉及到部署框架、硬件优化特性等问题,这构成了一个十分复杂的系统。此外,众多新出现的设备,如 VPU 、 NPU 等也并未将内核信息开源,对用户呈现黑盒模式。
为此,微软亚洲研究院异构计算组的研究员们提出并开发了一种框架 nn-Meter ,在硬件内核信息处于黑盒的情况下,对模型推理时间实现更准确的预测。该框架核心思想是将模型图划分为若干内核 (kernel) ,即设备上的执行单元,分别针对各个内核进行训练拟合,通过内核级预测实现对整体模型图推理时间的预测,预测准确率远超过传统方法。该框架的两个核心技术是内核检测、自适应采样。其具体实现原理与逻辑是什么?本文打算一探究竟。
1. 整体介绍
nn-Meter 整体框架如下图所示:
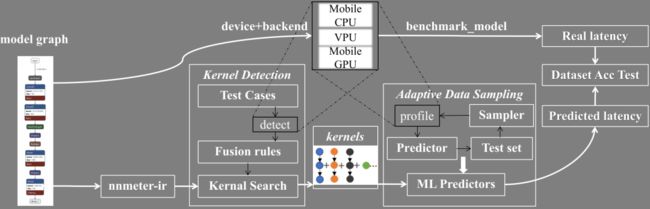
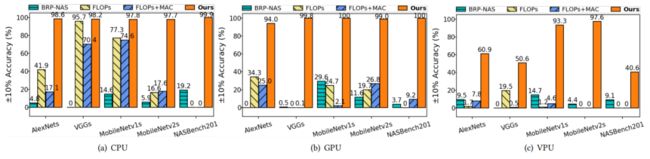
根据公开论文中的实验结果,nn-Meter 在移动端 CPU 、移动端 GPU 、 Intel VPU 上针对几种经典神经网络模型组成的数据集的预测精度远超过传统方法。特别是移动端 CPU 、移动端 GPU 上的数据集预测中,在 10% 容忍误差范围内预测准确率不低于 94% 。
对于一个神经网络模型,为了准确获取其推理时间,需要将其部署在后端设备上进行实测。nn-Meter 为了实现预测,首先将神经网络模型导入并转换成自身的 nnmeter-ir 。在 nnmeter-ir 的基础上,通过内核检测,将模型划分成若干 kernel ,所依赖的规则是在后端设备上通过若干测试样例检测出来的。然后针对不同类型的 kernel , 使用自适应数据采样方法分别生成若干 kernel 样本,将 kernel 样本放在后端设备上实测推理时间后,以 kernel 样本的特征为输入,对应的实测推理时间为输出,使用随机森林算法进行拟合,得到若干针对单个 kernel 的预测模型,以 .pkl 格式存储。之后将各个 .pkl 格式的模型组装成整体的预测器,实现整体推理时间的预测。
为了评估预测结果, nn-Meter 针对多种经典神经网络,在结构、层数不变的前提下修改其算子特征(例如 conv 算子的输入特征图尺寸 HW 、输入通道数 CIN 、输出通道数 COUT 、卷积核尺寸 KERNEL_SIZE 、 卷积步长 STRIDES,详见此处),得到多个不同的模型,分别部署在后端设备上进行实测后,构建数据集,用于评估预测器的预测准确率。
其中的关键技术点包括:
nnmeter-ir 导入
后端的注册与连接
融合规则检测
自适应数据采样及训练
预测器的组装与预测
笔者通过实际使用,认为该框架优点如下:
可扩展性强。 通过基类派生并注册导入的方式定义了接口,便于用户添加自定义的后端、算子、内核、预测器。
通用性好。 可以对不在数据集中的其他大型网络进行延迟预测,理论上也可以扩展对 Transformer 的支持
调试方便。 框架由纯 Python 实现,便于用户断点调试。
该框架的不足在于:
无法评估硬件平台中 cache 或 memory 对推理时间的影响。 虽然进行了内核级预测,但将硬件平台作为一个黑盒,内部具体架构或者模块未知。
不能用于无编译器的边缘设备。 推理时间由编译器和硬件架构共同决定,编译器的优化级别不同,推理时间也会有较大差异。
2. 关键技术点及注册接口原理介绍
(1) nnmeter-ir导入
nn-Meter 实现了对不同前端框架的支持。其将导入的 Frozen Pb 模型或 onnx 模型统一转换为内置的 nnmeter-ir 格式,而后进行后续处理。
nnmeter-ir 格式在内存中是一个字典、列表的嵌套式结构,可以保存为 json 格式文件进行查看,如下所示:
{
"input_im_0": {
"inbounds": [],
"attr": {
"name": "input_im_0",
"type": "Placeholder",
"output_shape": [
[
1,
224,
224,
3
]
],
"attr": {
"shape": [
1,
224,
224,
3
]
},
"input_shape": []
},
"outbounds": [
"conv1.conv/Conv2D"
]
},
"conv1.conv/Conv2D": {
// ………………………………………………其导入逻辑调用位于 nn_meter/ir_converter/utils.py ,将不同的前端模型统一化为 nnmeter-ir 。用户可通过如下命令将两种模型导入成 nnmeter-ir 。
nn-meter get_ir --tensorflow -o
nn-meter get_ir --onnx -o (2) 后端的注册与连接
后端的命名包括设备和运行时两部分, nn-Meter 除了调试使用的后端之外,默认提供了三种后端,分别是部署在移动 CPU 上的 tflite_cpu 、部署在移动 GPU 上的 tflite_gpu 、部署在 VPU 上的 openvino_vpu 。这三种后端可以通过如下命令进行查看。
nn-meter --list-backends以 tflite_cpu 为例,通过断点调试逐级深入,可梳理出后端的调用逻辑如下图所示:

nn-Meter 内置后端 tflite_cpu 所实现的 profile ,本质上是将模型通过 adb 方式推到移动设备上,并在 shell 里使用可执行程序 benchmark_model 进行实测,将实测结果字符串进行正则匹配解析,获取实测推理时间的平均值 (avg) 和标准差 (std) 。
profile 相关的核心代码详见 nn_meter/builder/backends/tflite/tflite_profiler.py ,字符串进行正则匹配解析的核心代码详见 nn_meter/builder/backends/tflite/cpu.py。
(3) 融合规则检测
融合规则检测所依赖的核心公式为论文中公式 (1) , 为阈值系数,配置文件中默认将其设置为 0.5 。
即假如两个算子融合后的 latency 比各自的 latency 之和要小,且二者间差距大于一定阈值,就认为两个算子确实发生了融合,形成一个 kernel。
配置文件中定义若干种算子组合,一种算子组合称为一个 test case 。假如该 test case 符合该公式,则成为一个检测到的合法 kernel。
代码中对应的部分在 nn_meter/builder/backend_meta/fusion_rule_tester/generate_testcase.py 中:
# ………………………………………………
def test(self):
secondary_op_lat = min(lat for op, lat in self.latency.items() if op != 'block' or op != self.false_case)
return self.latency[self.false_case].avg - self.latency['block'].avg > self.eps * secondary_op_lat.avg
# ………………………………………………事实上,此处虽然疑似将 误写成 ,但实则基本没有影响,因为 对应的 和 对应的 取值一致。
(4) 自适应数据采样及训练
由于某些内核所具有的数据采样空间巨大,例如 conv-bn-relu 。因此, nn-Meter 通过迭代采样对最有益的配置进行采样。
自适应数据采样主要采集两方面的数据。首先是目前模型设计空间中考虑的内核配置参数,通过计算当前设计空间的配置参数取值概率分布,进而根据此概率分布进行采样。第二是某些会触发硬件平台特殊优化的内核配置参数。
训练时针对各种内核首先生成前端模型格式,而后编译为后端所支持的模型格式,使用后端实现的 profile 和 parse 进行 latency 实测。而后以内核配置为输入,实测 latency 为输出,进行随机森林训练拟合。
nn-Meter 也验证出, conv 系列的 kernel 其实可以都用 conv-bn-relu 训练出的内核预测模型进行预测。
(5) 预测器的组装与预测
内核预测模型训练出来后, nn-Meter 使用 yaml 格式的配置文件将其组织起来组成预测器。配置文件如下图所示:
name: cortexA76cpu_tflite21
version: 2.0
category: cpu
package_location: /home/john/Projects/nn-meter/user/predictors/cortexA76cpu_tflite21
kernel_predictors:
- conv-bn-relu
- dwconv-bn-relu
- fc
- global-avgpool
- hswish
- relu
- se
- split
- add
- addrelu
- maxpool
- avgpool
- bn
- bnrelu
- channelshuffle
- concatnn-Meter 导入新的前端模型后,首先根据融合规则将其拆分为若干 kernel ,而后根据内核预测模型分别预测各个 kernel 的 latency ,最后将计算图上最长 kernel 链路的 latency 累加起来,即为整体模型的预测 latency。
3. 总结
nn-Meter 框架通过内核级预测实现了对整体模型图推理时间的预测。该框架还可以作为一个精确的预测工具,在自研芯片的设计中实现端到端预测。进而可扩展为硬件模拟仿真器,在自研芯片的设计过程中起指导作用。
本文针对 nn-Meter 框架的关键技术点和可扩展注册接口进行了梳理分析,受限于笔者知识水平,文中可能会存在某些理解身上的偏差,欢迎各位大佬进行交流,共同进步。
