[DL/论文阅读](卷积神经网络)
文章目录
- CNN组件
-
- CNN架构
- padding填白
- pooling池化
- 计算卷积输出大小、参数量和计算量
- 参数量
- 感受野( R e c e p t i v e Receptive Receptive F i e l d Field Field)
- CNN 与 MLP
- CNN 与 Transformer
-
- Self-attention
-
- 为什么要引入Self-attention
- self-attention的基本原理
- self-attention的计算过程
- Self-Attention计算矩阵
- Multi-head self-attention
- Positional Encoding
- self-attention vs CNN
- Transformer
-
- encoder和decoder
- en-decoder之间的资讯传递cross-attention
- Training
- Tips
- [2016] (CVPR)Deep Residual Learning for Image Recognition
-
- abstract
- introduction
- related work
- 实验
- 李沐精讲
-
- 函数类
- 残差块
- resnet模型
- 总结
CNN组件
CNN架构
为什么使用CNN?
_第1张图片](http://img.e-com-net.com/image/info8/79be1aacca984504a2b3de8185303527.jpg)
_第2张图片](http://img.e-com-net.com/image/info8/cafaa7ad9a5f43f189551d4d48cd80b5.jpg)
如果只是简单的用全连接层做模型的话,那么它的参数会巨大
_第3张图片](http://img.e-com-net.com/image/info8/a5eaf5118b2b4efeb86e4880f740fa04.jpg)
随着参数的增加,我们可以增加他的弹性/能力,但也增加了过拟合的风险
但实际上,做图像识别是不需要这么多参数的,所以从两个方面考虑简化:
(1)Receptive field
如同人类识别鸟是通过鸟的特征,而不是整张图片一样,一个neuron也并不需要观察整个图片,而只用观察到鸟的pattern。patten在的地方,就是receptive filed。
_第4张图片](http://img.e-com-net.com/image/info8/d1b6efe401b64d0cabca17407e18c860.jpg)
_第5张图片](http://img.e-com-net.com/image/info8/d06093fd7c264fae84f361b7e5404a4f.jpg)
_第6张图片](http://img.e-com-net.com/image/info8/2510dc85a62341d78f6ef02681a2002f.jpg)
把这一块333的receptive field,变成一个27维列向量,传入Neural
_第7张图片](http://img.e-com-net.com/image/info8/66ecd6fb3d824e06ab20c5252bb515c0.jpg)
当然,不同的Neural可以守卫任意receptive field。receptive field也可以只包含一个channel,但是CNN一般不这样搞。当然receptive field也不一定非要正方形
Receptive field存在的意义是抓pattern,所以,对于不同的目标,可以自己设计receptive field 的size,3×3,5×5都可以。size的形状也可以自己设定。
虽然receptive field size可以设置的比较小,但是它能学习到比较大的pattern
_第8张图片](http://img.e-com-net.com/image/info8/219987951527442ea5beeeb917d909a0.jpg)
我们是希望两个receptive field是有重叠的,如果pattern正好出现在两个感受野交界上面。
如果stride后超过边界了怎么办?做padding,也就是补零
(2) Weight Sharing
_第9张图片](http://img.e-com-net.com/image/info8/cc71d5cde1cf4b62bb02abf3be81f1e9.jpg)
特征不会说固定出现在一个地方,比如鸟嘴不会总在左上方出现,而是有可能出现在图片的中央、右上方等,但位置的改变没有改变本质,鸟嘴还是鸟嘴。如何利用这个特性简化模型呢?
_第10张图片](http://img.e-com-net.com/image/info8/f4291d82ea85403382f89f1f5adfe961.jpg)
_第11张图片](http://img.e-com-net.com/image/info8/352a08f9295a419683ee11da9c39225c.jpg)
不同的neuron计算时共享相同的参数,但是由于input不同,所以output也会不同。负责同一个receptive field 的neuron不会共享参数。
_第12张图片](http://img.e-com-net.com/image/info8/4a6a4f2e693940a4a84170da55e7da18.jpg)
假设一共有64组不同的参数,(实际上,一个filter就是其中的一组参数),对于同一个 receptive field,64个filter都会参与计算。而到了下一个receptive field, 还是这64组参数作为w ,与作为x 的input计算产生output。
这时,一个CNN初步成型了。
padding填白
参考
_第13张图片](http://img.e-com-net.com/image/info8/0cceaa2cbc51445ea275c1a8aea934d3.jpg)
从上面我们可以知道,原图像在经过filter卷积之后,变小了,从(8,8)变成了(6,6)。假设我们再卷一次,那大小就变成了(4,4)了。
这样有啥问题呢?
主要有两个问题:
-
每次卷积,图像都缩小,这样卷不了几次就没了;
-
相比于图片中间的点,图片边缘的点在卷积中被计算的次数很少。这样的话,边缘的信息就易于丢失。
为了解决这个问题,我们可以采用padding的方法。我们每次卷积前,先给图片周围都补一圈空白,让卷积之后图片跟原来一样大,同时,原来的边缘也被计算了更多次。通过填充的方法,当卷积核扫描输入数据时,它能延伸到边缘以外的伪像素,从而使输出和输入size相同。
_第14张图片](http://img.e-com-net.com/image/info8/9dc25ade77f84f6f8fb2e2026b7640c9.jpg)
比如,我们把(8,8)的图片给补成(10,10),那么经过(3,3)的filter之后,就是(8,8),没有变。
我们把上面这种“让卷积之后的大小不变”的padding方式,称为 “Same” 方式,(进行填充,允许卷积核超出原始图像边界,并使得卷积后结果的大小与原来的一致)
把不经过任何填白的,称为 “Valid”方式。这个是我们在使用一些框架的时候,需要设置的超参数。(不进行任何处理,只使用原始图像,不允许卷积核超出原始图像边界)
pooling池化
比如max pooling, 不会学习任何参数,只是减少计算量的手段
_第15张图片](http://img.e-com-net.com/image/info8/40804810066e4b4199ac165748e7896d.jpg)
_第16张图片](http://img.e-com-net.com/image/info8/6ee7672740fd4b15b666631928682cf4.jpg)
pooling的主要作用就是减少运算量
这个pooling,是为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。
比如下面的MaxPooling,采用了一个2×2的窗口,并取stride=2:
_第17张图片](http://img.e-com-net.com/image/info8/11fb5afcabcd455ebaaaa5a16f5ad2fb.jpg)
除了MaxPooling,还有AveragePooling,顾名思义就是取那个区域的平均值。
QA1:pooling层的作用:
池化层的一般作用是对特征图进行下采样,它本身没有参数权重,计算也简单,但它可达到降维特征(将低层次组合为高层次的特征)、突显特征、减少参数量、减少计算量、增加非线性、防止过拟合及提升模型泛化能力等作用
QA2:pooling层的反向传播:
池化层的前向传播我们都比较好理解,但是其是如何参与反向传播的呢?
池化层在反向传播时,它是不可导的,因为它是对特征图进行下采样会导致特征图变小,比如一个2x2的池化,在L+1层输出的特征图是16个神经元,那么对应L层就会有64个神经元,两层之间经过池化操作后,特征图尺寸改变,无法一一对应,这使得梯度无法按位传播。那么如何解决池化层不可导但却要参与反向传播呢?
在反向传播时,梯度是按位传播的,那么,一个解决方法,就是如何构造按位的问题,但一定要遵守传播梯度总和保持不变的原则。
对于平均池化,其前向传播是取某特征区域的平均值进行输出,这个区域的每一个神经元都是有参与前向传播了的,因此,在反向传播时,框架需要将梯度平均分配给每一个神经元再进行反向传播,相关的操作示意如下图所示。
_第18张图片](http://img.e-com-net.com/image/info8/2a5b2e18f0f944778df2280a2834cee8.jpg)
对于最大池化,其前向传播是取某特征区域的最大值进行输出,这个区域仅有最大值神经元参与了前向传播,因此,在反向传播时,框架仅需要将该区域的梯度直接分配到最大值神经元即可,其他神经元的梯度被分配为0且是被舍弃不参与反向传播的,但如何确认最大值神经元,这个还得框架在进行前向传播时记录下最大值神经元的Max ID位置,这是最大池化与平均池化差异的地方,相关的操作示意如下图所示。
_第19张图片](http://img.e-com-net.com/image/info8/ce61ae848296481bab3f767e9c74c5e4.jpg)
其中,上述表格中,前向传播时,每个单元格表示特征图神经元值,而在反向传播时,每个单元格表示的是分配给对应神经元的梯度值。
_第20张图片](http://img.e-com-net.com/image/info8/669845ed65ed4305b032e002b607761a.jpg)
计算卷积输出大小、参数量和计算量
_第21张图片](http://img.e-com-net.com/image/info8/b653887cf78844bcb484b532e40dad01.jpg)
参数量
- 计算量对应我们之前的时间复杂度,参数量对应于我们之前的空间复杂度,这么说就很明显了。也就是计算量要看网络执行时间的长短,参数量要看占用显存的量
- 计算量,参数量对于硬件的要求是不同的。计算量的要求是在于芯片的floaps(指的是gpu的运算能力)。参数量取决于显存大小。
针对于卷积层:
_第22张图片](http://img.e-com-net.com/image/info8/4b37b4c2268f458b82aa35588ffca75a.jpg)
_第23张图片](http://img.e-com-net.com/image/info8/b011dd98565a47fa925edda2f0b3ebb6.jpg)
_第24张图片](http://img.e-com-net.com/image/info8/ae37a86e5b8d4e23a6c2d854c18a75db.jpg)
_第25张图片](http://img.e-com-net.com/image/info8/f674260d61064886a82763c39f7d29f7.jpg)
![]()
针对于全连接层:
参数个数: FC前层 × FC后层
计算量/乘法计算次数/times : FC前层 × FC后层
_第26张图片](http://img.e-com-net.com/image/info8/58ad1010f7d243d3b773bc8ddeed4698.jpg)
_第27张图片](http://img.e-com-net.com/image/info8/7ef43958f14f437ca85eb0edf9b2edb5.jpg)
感受野( R e c e p t i v e Receptive Receptive F i e l d Field Field)
感受野( R e c e p t i v e Receptive Receptive F i e l d Field Field)的定义是卷积神经网络每一层输出的特征图( f e a t u r e feature feature m a p map map)上的像素点在原始输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应原始输入图片上的区域,如下图所示。
_第28张图片](http://img.e-com-net.com/image/info8/a4bf4fca75e44e18a50e31ced075526e.jpg)
感受野的作用
(1)一般 t a s k task task 要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好;
(2)密集预测 t a s k task task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好;
(3)目标检测 t a s k task task中设置 a n c h o r anchor anchor要严格对应感受野, a n c h o r anchor anchor太大或偏离感受野都会严重影响检测性能。
感受野计算:
在计算感受野时有下面几点需要说明:
(1)第一层卷积层的输出特征图像素的感受野的大小等于卷积核的大小。
(2)深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系。
(3)计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小。
下面给出计算感受野大小的计算公式:
R F l + 1 = ( R F l − 1 ) ∗ s t r i d e + k e r n e l RF_{l+1} = (RF_{l}-1)*stride + kernel RFl+1=(RFl−1)∗stride+kernel
其中 R F l + 1 RF_{l+1} RFl+1为当前特征图对应的感受野的大小,也就是要计算的目标感受野, R F l RF_{l} RFl为上一层特征图对应的感受野大小, f l + 1 f_{l+1} fl+1为当前卷积层卷积核的大小,累乘项 s t r i d e s strides strides表示当前卷积层之前所有卷积层的步长乘积。
举一个例子,7 * 7的输入图经过三层卷积核为3 * 3的卷积操作后得到 O u t 3 Out3 Out3的感受野为7 * 7,也就是 O u t 3 Out3 Out3中的值是由 I n p u t Input Input所有区域的值经过卷积计算得到,其中卷积核( f i l t e r filter filter)的步长( s t r i d e stride stride)为1、 p a d d i n g padding padding为0,,如下图所示:
_第29张图片](http://img.e-com-net.com/image/info8/bf7ab5842838480a958af48d4aba0419.jpg)
以上面举的 s a m p l e sample sample为例:
O u t 1 Out1 Out1层由于是第一层卷积输出,即其感受野等于其卷积核的大小,即第一层卷积层输出的特征图的感受野为3, R F 1 RF1 RF1=3;
O u t 2 Out2 Out2层的感受野 R F 2 RF2 RF2 = 3 + (3 - 1) * 1 = 5,即第二层卷积层输出的特征图的感受野为5;
O u t 3 Out3 Out3层的感受野 R F 3 RF3 RF3 = 3 + (5 - 1) * 1 = 7,即第三层卷积层输出的特征图的感受野为7;
常见网络的感受野如下:
_第30张图片](http://img.e-com-net.com/image/info8/b28f93793bae4bac87b5fecf9093b0e2.jpg)
CNN 与 MLP
记得之前说过,CNN限制了模型的弹性,具体如下,越内部就越限制弹性
-
FC是自己决定是看全局还是局部范围(将一些weight设置为0),而加了感受野的概念之后就只能看一个小范围,所以model弹性变小
-
参数共享之后,某些神经元(卷积核)的参数都是一模一样的,没得选,这更加增加了对神经元的限制
_第31张图片](http://img.e-com-net.com/image/info8/019fb25cd9e04a39a1dfc8cb69506f85.jpg)
所以,CNN的model bias比较大。但对CV任务不是问题
Filter:
另一种理解CNN的方式是直接从filter的角度看
_第32张图片](http://img.e-com-net.com/image/info8/861a1686eb7445f2b59ebb9568678737.jpg)
那么我们先给 定不同的Filter,每一个filter都会抓图片里面的pattern(33channel)
以黑白图片为例子
_第33张图片](http://img.e-com-net.com/image/info8/49f1a3fcc9714185a3e8c802969e9b38.jpg)
filter看到image里面出现什么东西的时候他的值最大(这里出现对角线1的时候最大)
_第34张图片](http://img.e-com-net.com/image/info8/799dc52849e749219849eff0be7045e6.jpg)
如果说我们设置64个filter,那就会得到一个channel为64的 Image,每一个矩阵就是相应的feature map
_第35张图片](http://img.e-com-net.com/image/info8/8f63295de35449e6837bf52324cd2ddc.jpg)
我们再根据Image-1进行Convolution,构造3364的filter
那么33是否太小而无法看到更大范围的pattern呢??其实根本不会,在第二层33我们看见的其实在原图是5*5,根据网络的不断叠加,我们会越看越大。
其实现在回过头来看,CNN跟我们之前学习的神经网络,也没有很大的差别。传统的神经网络,其实就是多个FC层叠加起来。
CNN,无非就是把FC改成了CONV和POOL,就是把传统的由一个个神经元组成的layer,变成了由filters组成的layer。
那么,为什么要这样变?有什么好处?
具体说来有两点:
- 参数共享机制
我们对比一下传统神经网络的层和由filters构成的CONV层:
假设我们的图像是8×8大小,也就是64个像素,假设我们用一个有9个单元的全连接层:
_第36张图片](http://img.e-com-net.com/image/info8/b61f114c36374d4ebbc8c42f06201a1f.jpg)
那这一层我们需要多少个参数呢?需要 64×9 = 576个参数(先不考虑偏置项b)。因为每一个链接都需要一个权重w。
那我们看看 同样有9个单元的filter是怎么样的:
_第37张图片](http://img.e-com-net.com/image/info8/aa4ed1efbcef4ab090faa4cda8a16ab8.jpg)
其实不用看就知道,有几个单元就几个参数,所以总共就9个参数!
(1)因为,对于不同的区域,我们都共享同一个filter,因此就共享这同一组参数。这也是有道理的,通过前面的讲解我们知道,filter是用来检测特征的,那一个特征一般情况下很可能在不止一个地方出现,比如“竖直边界”,就可能在一幅图中多出出现,那么 我们共享同一个filter不仅是合理的,而且是应该这么做的。
(2)由此可见,参数共享机制,让我们的网络的参数数量大大地减少。这样,我们可以用较少的参数,训练出更加好的模型,典型的事半功倍,而且可以有效地 避免过拟合。
(3)同样,由于filter的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征,这叫做 “平移不变性”。因此,模型就更加稳健了。
补充:
1. 在欧几里得几何中,平移是一种几何变换,表示把一幅图像或一个空间中的每一个点在相同方向移动相同距离。比如对图像分类任务来说,图像中的目标不管被移动到图片的哪个位置,得到的结果(标签)应该是相同的,这就是卷积神经网络中的平移不变性。
2. 池化:比如最大池化,它返回感受野中的最大值,如果最大值被移动了,但是仍然在这个感受野中,那么池化层也仍然会输出相同的最大值。这就有点平移不变的意思了。
所以这两种操作共同提供了一些平移不变性,即使图像被平移,卷积保证仍然能检测到它的特征,池化则尽可能地保持一致的表达。
- 局部连接
由卷积的操作可知,输出图像中的任何一个单元,只跟输入图像的一部分有关系:
_第38张图片](http://img.e-com-net.com/image/info8/feaf1317a87b452dbddbd86180153e62.jpg)
而传统神经网络中,由于都是全连接,所以输出的任何一个单元,都要受输入的所有的单元的影响。这样无形中会对图像的识别效果大打折扣。比较,每一个区域都有自己的专属特征,我们不希望它受到其他区域的影响。
_第39张图片](http://img.e-com-net.com/image/info8/71743127883645dcbd0b4bab471add0b.jpg)
CNN 与 Transformer
Self-attention
以下内容部分参考李宏毅笔记
为什么要引入Self-attention
基于RNN(LSTM)的序列模型来说,计算每个cell的输出无法进行并行化。而且单向的RNN无法很好的利用全局的信息。其中下面中的a和b均为向量。
_第40张图片](http://img.e-com-net.com/image/info8/cce4a738efbb47c4ba5d1e709d94f44d.jpg)
CNN是可以平行化的,不需要第一个filter计算完毕才计算第二个filter,可以同时计算所有的filter。但是一个缺点是要叠许多层才可以看到长期的信息,如果第一个filter就需要长时间的信息那么是做不到的,所以有了自注意力。
_第41张图片](http://img.e-com-net.com/image/info8/c8aecb91c78a422197de5dc49166b311.jpg)
self-attention取代RNN:
_第42张图片](http://img.e-com-net.com/image/info8/eb15fa5eff9a4305ab2a332499ecd157.jpg)
自注意力模型输入:
如下图所示,左侧的变长的输入序列即是自注意力模型的输入数据,注意这个向量序列的长度不是固定的。
_第43张图片](http://img.e-com-net.com/image/info8/378720f10dea48cda1ca298ab71b487d.jpg)
self-attention的基本原理
_第44张图片](http://img.e-com-net.com/image/info8/8ab8814bb3524c1884b7d302592cb8a0.jpg)
因为要建立输入向量序列的长依赖关系,所以模型要考虑整个向量序列的信息。如下图所示,Self-Attention的输出序列长度是和输入序列的长度一样的,对应的输出向量考虑了整个输入序列的信息。然后将输出向量输入到Fully-Connected网络中,做后续处理。
_第45张图片](http://img.e-com-net.com/image/info8/d8f1238370bb4f749830e8174773d315.jpg)
当然Self-Attention可以和Fully-Connected交替使用多次以提高网络的性能,如下图所示。
_第46张图片](http://img.e-com-net.com/image/info8/1fc832fac20247a18f1579659362fafb.jpg)
上边我们提到,Self-Attention可以使用多次,那么输入可能是整个网络的输入,也可能是前一个隐藏层的输出,这里我们使用[a1,a2,a3,a4]来表示输入,使用b1表示输出为例。
_第47张图片](http://img.e-com-net.com/image/info8/5f6c515489974e34bf4dd792ce3ca3b0.jpg)
_第48张图片](http://img.e-com-net.com/image/info8/be851d0a40304afb8e517182a5366b41.jpg)
首先Self-Attention会计算a1分别与[a1,a2,a3,a4]的相关性[α1,1,α1,2,α1,3,α1,4]。相关性表示了输入[a1,a2,a3,a4]对a1是哪一个label的影响大小。而相关性α的计算方式共有Dot-product和Additive两种。
Dot-product:
_第49张图片](http://img.e-com-net.com/image/info8/a170584b8fe1488c87c72f3c28354bc0.jpg)
在Dot-product中,输入的两个向量,左边的向量乘上矩阵Wq得到矩阵q,右边的向量乘上矩阵Wk得到矩阵k,然后将矩阵q和矩阵k对应元素相乘并求和得到相关性α。
Additive:
_第50张图片](http://img.e-com-net.com/image/info8/a40590f23b3d493d9963e7ac4b067480.jpg)
在Additive中同样也是先将两个输入向量与矩阵Wq和矩阵Wk相乘得到矩阵q和k。然后将矩阵q和k串起来输入到一个激活函数(tanh)中,在经过Transform得到相关性α。
self-attention的计算过程
为了提高模型能力,自注意力模型经常采用查询-键-值(Query-Key-Value,QKV)模型,其计算过程如下所示:
_第51张图片](http://img.e-com-net.com/image/info8/86c15698783d4e0e9ee67a9341e038b0.jpg)
![]()
_第52张图片](http://img.e-com-net.com/image/info8/06dda3423f82496b8a39f5c5d1f85e09.jpg)
_第53张图片](http://img.e-com-net.com/image/info8/3a95e948a17e4839b16c5d568d6c1125.jpg)
![]()
_第54张图片](http://img.e-com-net.com/image/info8/8b8f6741486d457d86a5206fb8292b2c.jpg)
![]()
_第55张图片](http://img.e-com-net.com/image/info8/453c7065bbd44aad878b4a621952cd41.jpg)
![]()
Self-Attention计算矩阵
由上边计算过程可知,每个输入a都会产生q、k和v三个矩阵。这里还是以[a1,a2,a3,a4]为输入为例:
![]()
_第56张图片](http://img.e-com-net.com/image/info8/093bce7173524394a5e83ff74bb9f61c.jpg)
![]()
_第57张图片](http://img.e-com-net.com/image/info8/67d399007d5e4f359425d7190890ddad.jpg)
![]()
_第58张图片](http://img.e-com-net.com/image/info8/07ad219459054653a21c64023cd7709e.jpg)
![]()
_第59张图片](http://img.e-com-net.com/image/info8/3b40a407efe44c2c8b47a7f377c1e4a6.jpg)
_第60张图片](http://img.e-com-net.com/image/info8/63e17582821d44b7982300f1740822f0.jpg)
_第61张图片](http://img.e-com-net.com/image/info8/77b23248bff04ff2a882924ee6818374.jpg)
_第62张图片](http://img.e-com-net.com/image/info8/41df30e6fdf445ffb8424bd32aa2cd45.jpg)
Multi-head self-attention
Self-Attention有一个使用非常广泛的的进阶版Multi-head Self-Attention,具体使用多少个head,是一个需要我们自己调节的超参数(hyper parameter)。

(可能相关性有不同的定义)
_第63张图片](http://img.e-com-net.com/image/info8/a972dbcab6a14397873570739384758e.jpg)
在后续的计算中,我们只将属于相同相关性的矩阵进行运算,如下图所示:
_第64张图片](http://img.e-com-net.com/image/info8/09f8bcca08944d76a2b2a707111a8596.jpg)
_第65张图片](http://img.e-com-net.com/image/info8/ab0dcdc11aee48409b93eddf2ac5fca3.jpg)
_第66张图片](http://img.e-com-net.com/image/info8/e2cebfed06134eb8af8f7dca689b909f.jpg)
Positional Encoding
通过前边的了解,可以发现对于每一个input是出现在sequence的最前面,还是最后面这样的位置信息,Self-Attention是无法获取到的。这样子可能会出现一些问题,比如在做词性标记(POS tagging)的时候,像动词一般不会出现在句首的位置这样的位置信息还是非常重要的。
我们可以使用positional encoding的技术,将位置信息加入到Self-Attention中。
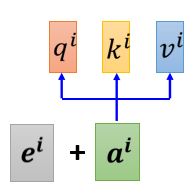
如上图所示,我们可以为每个位置设定一个专属的positional vector,用ei表示,上标i代表位置。我们先将ei和ai相加,然后再进行后续的计算就可以了。ei向量既可以人工设置,也可以通过某些function或model来生成,具体可以查阅相关论文。
_第67张图片](http://img.e-com-net.com/image/info8/da759f158ef84ac2ab8ba9ebbfb98421.jpg)
self-attention vs CNN
_第68张图片](http://img.e-com-net.com/image/info8/d9c79153f3ec4c9887c490898936a172.jpg)
_第69张图片](http://img.e-com-net.com/image/info8/7253935b76a84f43ad487145ee47cd10.jpg)
self-attention比较flexible,比较flexible的model比较需要更多的data,如果data不够就有可能过拟合。而小的model,比较有限制的model适合在data少的时候,不容易过拟合
_第70张图片](http://img.e-com-net.com/image/info8/adfd751a349347afbb6b146f7c2a4ba7.jpg)
self-attention的弹性比较大,所以需要更多的训练资料,训练资料少的时候就会overfitting。而CNN的弹性比较小,训练资料比较少的时候效果比较好,但是训练资料多的时候无法从更大量的训练资料得到好处
Transformer
Transformer是一个sequence to sequence(seq2seq)的模型,输入一个序列,输出一个序列。这两个序列的长度、关系是由模型自己确定的。相关场景包括:语音识别(一段语音转换成的文字的长度是由模型决定的)、机器翻译(翻译后的语句的长度是由机器决定的)、语音翻译(直接对语音进行翻译)、聊天机器人(输入是语句、输出也是语句)。还有很多看起来和seq2seq完全没关系的问题也可以用seq2seq硬做。
Seq2seq模型包括一个encoder和decoder
encoder和decoder
Encoder:
_第71张图片](http://img.e-com-net.com/image/info8/87d9b7f344344cf2aeef27cf0c86ba66.jpg)
_第72张图片](http://img.e-com-net.com/image/info8/0b977599f3e24c6891258c4433ca4e7b.jpg)
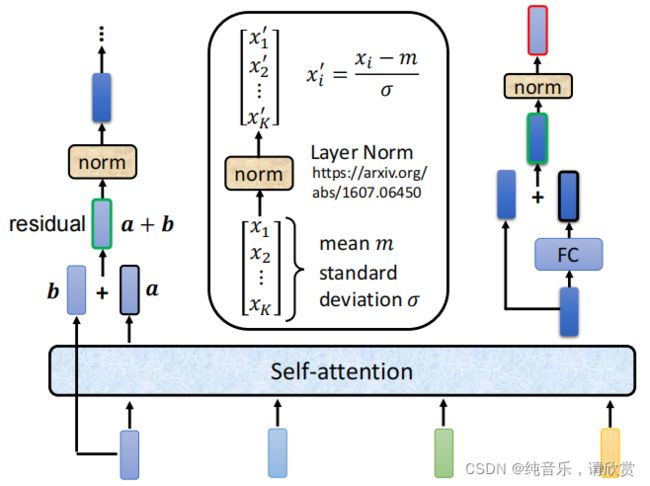
layer norm不考虑batch信息
Decoder:
_第73张图片](http://img.e-com-net.com/image/info8/1b62d7c5a2474bcba04067e14ebebcc5.jpg)
Decoder的很常见的一种是autoregressive(AT)。以语音识别为例来介绍AT。Decoder的输入是encoder的输出向量(但不完全是,看了后面就会知道原因)。Decoder的输入中会有一个标记开始的token。在中文语音识别的模型中,Decoder的输出就是一个个的汉字。那么,每个输出位可能的输出是所有汉字(不是真正意义上的所有汉字,而是训练中的用到的汉字)。对于每个输出位,可以做一个softmax,来决定这个输出位到底输出什么汉字
_第74张图片](http://img.e-com-net.com/image/info8/17a5c1d6722c4f53bf6000321ecd4b87.jpg)
有趣的部分是,当decoder决定在第一个字的位置输出“机”后,这个“机”会被当成decoder的输入,然后decoder输出“器”;同样地,“器”也被当成decoder的输入。这样进行下去,逐渐输出“机器学习”四个字。也就是说,这种decoder(具体来说,AT)的输入是它在上一个时间点的输出。那么如果decoder的上一个输出是错的该怎么办呢?即便decoder努力输出正确的结果,但也可能会造成连环错误:从一个字错了之后,后面的结果接连出错。我们暂时不考虑这个问题。
_第75张图片](http://img.e-com-net.com/image/info8/0e2f5093f18c4ffd9f31828175133d8d.jpg)
_第76张图片](http://img.e-com-net.com/image/info8/e6500bb6d2214514983df6138f61aaef.jpg)
(下面一排token都是onehot编码)
Encoder和decoder的构成对比:
_第77张图片](http://img.e-com-net.com/image/info8/afa5304666a04407b30a2678705683f5.jpg)
如果把灰色的部分遮起来,其实decoder和encoder的构成没有太大差别。细小的差别在于,decoder中的multi-head attention前面加了一个“masked”。这一部分涉及到self attention的知识,这里只是简单提一下。
对于self attention,输出向量的每一位和输入向量的每一位是有关系的。即b1与a1~a4都有关系。
_第78张图片](http://img.e-com-net.com/image/info8/ee3a26c681af4bf9b8f3720bb74386ff.jpg)
而masked self attention中,b1只与a1有关系,b2只与a1a2有关系,b3只与a1a3有关系…
_第79张图片](http://img.e-com-net.com/image/info8/d757a3cad9194f4195a88d7e52fee7fd.jpg)
具体来说:原有的:
_第80张图片](http://img.e-com-net.com/image/info8/b3521fd9fbd449c4b7fd17d214f20ea0.jpg)
masked:
_第81张图片](http://img.e-com-net.com/image/info8/6eb8ab51fca84e37afa79444640ba968.jpg)
那么为什么在decoder里面要用这种masked的形式呢?其实这和decoder的特征很符合。在decoder中,每一位的输出会被当成输入用来产生下一个输出,也就是说,decoder的输入是随着输出的过程一个一个产生的,而不是一下子就有一个完整的输入送给decoder。所以,比如,计算b2的时候,此时还没有b3和b4,所以当然只能根据a1~a2来计算b2。
这里还有一个问题没有提及,就是:到底模型要产生多长的输出?当模型产生“习”之后,就应该停止了,但模型如果不知道该停了,也许会继续把“习”当成输入继续产生输出。
_第82张图片](http://img.e-com-net.com/image/info8/5279763cdfba478589e06d26fb39f26d.jpg)
怎么办?我们可以在每一位的输出列表中加一个stop token。每一位的输出列表是汉字列表,因此要在汉字组成的列表中加一个表示结束的stop token:
_第83张图片](http://img.e-com-net.com/image/info8/8b9a2591ddf0417b8ce4967baa3f785c.jpg)
_第84张图片](http://img.e-com-net.com/image/info8/081f1de10b644848a60fffff372fcc6a.jpg)
与AT相对的是NAT(non-autoregressive)。NAT的结果一般比AT差。
_第85张图片](http://img.e-com-net.com/image/info8/d0dab034b09a48e6ae4988586b249994.jpg)
NAT的好处是平行化,因为AT的decoder是逐个产生的输出,如果你句子长度为100,就要做100次decoder。所以在速度上,NAT更快
en-decoder之间的资讯传递cross-attention
_第86张图片](http://img.e-com-net.com/image/info8/c5ce17978b29447aa20e6695ed2b797c.jpg)
_第87张图片](http://img.e-com-net.com/image/info8/c3eeb9d3512c4f28be12ac5f37d8ef7b.jpg)
_第88张图片](http://img.e-com-net.com/image/info8/b5ec98a4cfd54e3ca73791dfce81dd0b.jpg)
各式各样的cross-attention
_第89张图片](http://img.e-com-net.com/image/info8/ca97f070febd4d74b67bbd571495f490.jpg)
Training
这一部分从decoder的训练开始。训练的过程如下:
_第90张图片](http://img.e-com-net.com/image/info8/7fc99cd7013544528fba7332e125137f.jpg)
训练的时候,对于输出的每一个字,我们都给它一个独热向量,希望它输出的各汉字的分布和独热向量越接近越好。其实,对于输出的每一位,相当于在做分类问题。如果汉字列表中有4000个汉字,那么每一个汉字的输出过程就都是一个4000类的分类问题 。这里“机器学习”四个字相当于是做了4个4000类的分类问题。
虽然decoder的输入是随着输出的产生而逐渐产生的,但在训练的时候我们会直接一次性告诉decoder正确答案:
_第91张图片](http://img.e-com-net.com/image/info8/3cdd29ca240d4404aba3179fc0e24ef9.jpg)
我们希望机器可以在有begin的情况下输出“机”,在有“begin”和“机”的情况下输出“器”……在有“begin机器学习”的情况下输出“end”。这个叫做teacher foring:把ground truth(真实值)作为输入。
Tips
接下来讲一些关于训练transformer(或者不一定是transformer,也可以是其他的seq2seq模型)的小技巧。
Copy Mechanism:
在聊天机器人中,可以采用copy mechanism:
_第92张图片](http://img.e-com-net.com/image/info8/66c30723efe444feb5063079ce7730b1.jpg)
在第一段对话中,模型应该回答“库洛洛你好”,但是库洛洛对模型来说是很奇怪的词汇,也许训练数据中根本没有出现过这个词。这是,模型其实没有必要真的去生成“库洛洛”,而是可以学会在见到“我是…”这样的句式时,原封不动地输出“我是”后面的内容。这是一种从输入内容进行copy的方式。另一种情况是,模型遇到了一些不懂的内容。“不能使用念能力”是模型没有见过的内容,那么这时机器可以直接把这部分语句复制过来直接输出,而不是试图去产生这个语句。
另一种情况是做摘要的时候:
_第93张图片](http://img.e-com-net.com/image/info8/c53874ac7a9548a49a7807b41a33838a.jpg)
_第94张图片](http://img.e-com-net.com/image/info8/e8412091bdd8499ab857a68d338045f5.jpg)
摘要本身不需要产生新的词汇,而是直接从文章里选词汇就可以。当然,真实生活中,我们可能会用到一些原文中没有的词来更好的概括内容,但这是很高级的能力,在这里我们不涉及。
Guided Attention:
模型可能会犯一些低级错误。以TTS(语音合成,text to speech)为例,如果让模型重复念一个词很多次,它的读音可能会不一样。比如,让某个模型念“发财”4遍,模型念的这4遍“发财”是有区别的;只念一遍“发财”时,甚至不能完整念出“发财”二字。苹果的Siri、papago翻译都有这样的问题。这样的例子不多,但确实是存在的。
要求机器做attention的时候是有固定方式的。与此问题相关的训练技巧是强迫模型的输出的顺序和输入的顺序之间是保持单调的。比如,在语音识别,语音合成的过程中,模型必须从单调地左向右处理输入(关键词:monotonic attention, location-aware attention):
_第95张图片](http://img.e-com-net.com/image/info8/f99ad27f6d9d49da86da9d9bc1d3f50f.jpg)
beam search(集束搜索):
_第96张图片](http://img.e-com-net.com/image/info8/fee48b3d595d45da8ab597149d18dbc6.jpg)
假设世界上只有两种token:A和B。模型每次生成A或B的抉择过程可以用一棵树来表示。每次输出时,模型都用一个分数来决定到底输出什么。图中的红色路径是贪心的结果,其实绿色路径是最好的选择。如果在刚开始选择了输出A,结果可能会错过更好的结果。一种简单但幼稚不可行的方案是暴力搜索这棵树来发现最好的路径,因为计算量大到无法想象:以中文语音识别为例,如果汉字列表中有4000个字,那么树的每个节点的分叉就有4000个,这是不可能进行暴力搜索的。所以要用到beam search的方法。这个方法具体是怎么进行的,这里不提及。这个方法有时候有用,有时候没用(至少两种情况都有不少大佬的论文来证明)。对于那些有确定唯一答案的任务,比如语音识别,集束搜索很有用;而对于需要发挥一些创造力的任务,比如,根据上文续写下文,集束搜索的表现不好。
这里提到一个很神奇的现象。在进行语音合成的测试时,需要加入一些随机的噪声。这是很违反常理的,我们往往在训练的时候使用噪声来让模型可以接触到更多的可能性,让模型更强健。但在语音合成的技术中,在测试的时候也要加入一些噪声,这样反而合成的语音质量更好。
Optimizing Evaluation Metric:
有一种评估标准叫blue score:把模型产生的句子和真实的句子进行比较。但是问题在于,我们训练的时候并不是这样做的。对于识别“机器学习”这四个字的语音识别任务来说,训练的过程实际上是做了4个4000类(4000是假设的汉字总数量)的分类问题,对于每个字的产生,我们用了交叉熵。但是在评估的时候,我们用的是blue score。交叉熵和blue score之间并没有什么直接的联系。那么我们可不可以在训练的时候就用blue score进行优化呢?不行,因为对两个句子之间计算的blue score是不可微分的。那么怎么办呢?一个方法是。遇到用optimization无法解决的问题时,采用强化学习硬训练一次就行了。即便有人成功过,这依然是一个很难的方法。
_第97张图片](http://img.e-com-net.com/image/info8/dc8391ac34244f9ca266851452269391.jpg)
schedule sampling:
训练的过程中,decoder可以看到正确答案,但在测试的时候,decoder只能看到自己的输出,因此会出现一步错步步错的情况,这种情况被称为exposure bias。解决办法是训练的过程中,在给decoder展示的ground truth中故意加入一些错误,decoder反而会学得更好。
_第98张图片](http://img.e-com-net.com/image/info8/098edb29ff0f4118ade27ed2722f0283.jpg)
但是这一招会伤害到transformer平行化的能力
[2016] (CVPR)Deep Residual Learning for Image Recognition
abstract
- 提出问题:深的神经网络非常难以训练
- 干了什么:做了一个使用残差学习的框架,来使得训练非常深的网络更加容易
提出的方法:把层作为一个残差学习函数相对于层输入的一个方法,而不是说跟之前一样的学习unreferenced functions
提供了非常多的证据证明这些残差网络容易训练、能够得到很好的精度,特别是在把层增加了之后,在ImageNet数据集上使用了152层的深度,但是有了更低的复杂度
论文第一张图
_第99张图片](http://img.e-com-net.com/image/info8/ef2312d7f3c34120840a58c2567faa63.jpg)
- 一般会在第一页放上一个比较好看的图
- 左图是训练误差,右图是在CIFAR-10上的测试误差
- x轴是轮数
- y轴是错误率
- 从图中可以看到,更深(更大的)网络误差率反而更高:训练误差更高,测试误差也更高
introduction
深度神经网络好在可以加很多层把网络变得特别深,然后不同程度的层会得到不同等级的feature,比如低级的视觉特征或者是高级的语义特征
提出问题:随着网络越来越深,梯度就会出现爆炸或者消失
- 解决他的办法就是:1、在初始化的时候要做好一点,就是权重在随机初始化的时候,权重不要特别大也不要特别小。 2、在中间加入一些normalization,包括BN(batch normalization)可以使得校验每个层之间的那些输出和他的梯度的均值和方差,相对来说比较深的网络是可以训练的,避免有一些层特别大,有一些层特别小。使用了这些技术之后是能够训练(能够收敛),虽然现在能够收敛了,但是当网络变深的时候,性能其实是变差的(精度会变差)
- 文章提出出现精度变差的问题不是因为层数变多了,模型变复杂了导致的过拟合,而是因为训练误差也变高了(overfitting是说训练误差变得很低,但是测试误差变得很高),训练误差和测试误差都变高了,所以他不是overfitting。虽然网络是收敛的,但是好像没有训练出一个好的结果
深入讲述了深度增加了之后精度也会变差
-
考虑一个比较浅一点的网络和他对应的比较深的版本(在浅的网络中再多加一些层进去),如果浅的网络效果还不错的话,深的网络是不应该变差的:深的网络新加的那些层,总是可以把这些层学习的变成一个identity mapping(恒等映射)(输入是x,输出也是x,等价于可以把一些权重学成比如说简单的n分之一,是的输入和输出是一一对应的),但是实际情况是,虽然理论上权重是可以学习成这样,但是实际上做不到:假设让SGD去优化,深层学到一个跟那些浅层网络精度比较好的一样的结果,上面的层变成identity(相对于浅层神经网络,深层神经网络中多加的那些层全部变成identity),这样的话精度不应该会变差,应该是跟浅层神经网络是一样的,但是实际上SGD找不到这种最优解
-
这篇文章提出显式地构造出一个identity mapping,使得深层的神经网络不会变的比相对较浅的神经网络更差,它将其称为deep residual learning framework
-
要学的东西叫做H(x),假设现在已经有了一个浅的神经网络,他的输出是x,然后要在这个浅的神经网络上面再新加一些层,让它变得更深。新加的那些层不要直接去学H(x),而是应该去学H(x)-x,x是原始的浅层神经网络已经学到的一些东西,新加的层不要重新去学习,而是去学习学到的东西和真实的东西之间的残差,最后整个神经网络的输出等价于浅层神经网络的输出x和新加的神经网络学习残差的输出之和,将优化目标从H(x)转变成为了H(x)-x
-
上图中最下面的红色方框表示所要学习的H(x)
-
蓝色方框表示原始的浅层神经网络
-
红色阴影方框表示新加的层
-
o表示最终整个神经网络的输出
-
这样的好处是:只是加了一个东西进来,没有任何可以学的参数,不会增加任何的模型复杂度,也不会使计算变得更加复杂,而且这个网络跟之前一样,也是可以训练的,没有任何改变
非常深的residual nets非常容易优化,但是如果不添加残差连接的话,效果就会很差。越深的网络,精度就越高
introduction是摘要的扩充版本,也是对整个工作比较完整的描述
related work
一篇文章要成为经典,不见得一定要提出原创性的东西,很可能就是把之前的一些东西很巧妙的放在一起,能解决一个现在大家比较关心难的问题
残差连接如何处理输入和输出的形状是不同的情况:
- 第一个方案是在输入和输出上分别添加一些额外的0,使得这两个形状能够对应起来然后可以相加
- 第二个方案是之前提到过的全连接怎么做投影,做到卷积上,是通过一个叫做1*1的卷积层,这个卷积层的特点是在空间维度上不做任何东西,主要是在通道维度上做改变。所以只要选取一个1*1的卷积使得输出通道是输入通道的两倍,这样就能将残差连接的输入和输出进行对比了。在ResNet中,如果把输出通道数翻了两倍,那么输入的高和宽通常都会被减半,所以在做1*1的卷积的时候,同样也会使步幅为2,这样的话使得高宽和通道上都能够匹配上
implementation中讲了实验的一些细节
- 把短边随机的采样到256和480(AlexNet是直接将短边变成256,而这里是随机的)。随机放的比较大的好处是做随机切割,切割成224*224的时候,随机性会更多一点
- 将每一个pixel的均值都减掉了
- 使用了颜色的增强(AlexNet上用的是PCA,现在我们所使用的是比较简单的RGB上面的,调节各个地方的亮度、饱和度等)
- 使用了BN(batch normalization)
- 所有的权重全部是跟另外一个paper中的一样(作者自己的另外一篇文章)。注意写论文的时候,尽量能够让别人不要去查找别的文献就能够知道你所做的事情
- 批量大小是56,学习率是0.1,然后每一次当错误率比较平的时候除以10
- 模型训练了60*10^4个批量。建议最好不要写这种iteration,因为他跟批量大小是相关的,如果变了一个批量大小,他就会发生改变,所以现在一般会说迭代了多少遍数据,相对来说稳定一点
- 这里没有使用dropout,因为没有全连接层,所以dropout没有太大作用
- 在测试的时候使用了标准的10个crop testing(给定一张测试图片,会在里面随机的或者是按照一定规则的去采样10个图片出来,然后再每个子图上面做预测,最后将结果做平均)。这样的好处是因为训练的时候每次是随机把图片拿出来,测试的时候也大概进行模拟这个过程,另外做10次预测能够降低方差。
- 采样的时候是在不同的分辨率上去做采样,这样在测试的时候做的工作量比较多,但是在实际过程中使用比较少
实验
- 如何评估ImagNet以
- 各个不同版本的ResNet是如何设计的
首先阐述了ImageNet
描述了plain networks
没有带残差的时候,使用了一个18层和34层
_第100张图片](http://img.e-com-net.com/image/info8/324ce0be30bf44ccaa007b05d57fef83.jpg)
- 上表是整个ResNet不同架构之间的构成信息(5个版本)
- 第一个7*7的卷积是一样的
- 接下来的pooling层也是一样的
- 最后的全连接层也是一样的(最后是一个全局的pooling然后再加一个1000的全连接层做输出)
- 不同的架构之间,主要是中间部分不一样,也就是那些复制的卷积层是不同的
- conv2.x:x表示里面有很多不同的层(块)
- 【3*3,64】:46是通道数
- 模型的结构为什么取成表中的结构,论文中并没有细讲,这些超参数是作者自己调出来的,实际上这些参数可以通过一些网络架构的自动选取
- flops:整个网络要计算多少个浮点数运算。卷积层的浮点运算等价于输入的高乘以宽乘以通道数乘以输出通道数再乘以核的窗口的高和宽
_第101张图片](http://img.e-com-net.com/image/info8/6ed5f82f07454a0d9a44c266173c0537.jpg)
- 上图中比较了18层和34层在有残差连接和没有残差连接的结果
- 左图中,红色曲线表示34的验证精度(或者说是测试精度)
- 左图中,粉色曲线表示的是34的训练精度
- 一开始训练精度是要比测试精度高的,因为在一开始的时候使用了大量的数据增强,使得寻来你误差相对来说是比较大的,而在测试的时候没有做数据增强,噪音比较低,所以一开始的测试误差是比较低的
- 图中曲线的数值部分是由于学习率的下降,每一次乘以0.1,对整个曲线来说下降就比较明显。为什么现在不使用乘0.1这种方法:在什么时候乘时机不好掌控,如果乘的太早,会后期收敛无力,晚一点乘的话,一开始找的方向更准一点,对后期来说是比较好的
- 上图主要是想说明在有残差连接的时候,34比28要好;另外对于34来说,有残差连接会好很多;其次,有了残差连接以后,收敛速度会快很多,核心思想是说,在所有的超参数都一定的情况下,有残差的连接收敛会快,而且后期会好
输入输出形状不一样的时候怎样做残差连接
- 填零
- 投影
- 所有的连接都做投影:就算输入输出的形状是一样的,一样可以在连接的时候做个1*1的卷积,但是输入和输出通道数是一样的,做一次投影
对比以上三种方案

- A表示填0
- B表示在不同的时候做投影
- C表示全部做投影
- B和C的表现差不多,但是还是要比A好一点
- B和C虽然差不多,但是计算复杂度更高,B对计算量的增加比较少,作者采用了B
怎样构建更深的ResNet
如果要做50或者50层以上的,会引入bottleneck design
_第102张图片](http://img.e-com-net.com/image/info8/ace2291a16534544b1636eb7b503d7da.jpg)
- 左图是之前的设计,当通道数是64位的时候,通道数不会发生改变
- 如果要做到比较深的话,可以学到更多的模式,可以把通道数变得更大,右图从64变到了256
- 当通道数变得更大的时候,计算复杂度成平方关系增加,这里通过1个1*1的卷积,将256维投影回到64维,然后再做通道数不变的卷积,然后再投影回256(将输入和输出的通道数进行匹配,便于进行对比)。等价于先对特征维度降一次维,在降一次维的上面再做一个空间上的东西,然后再投影回去
- 虽然通道数是之前的4倍,但是在这种设计之下,二者的算法复杂度是差不多的
ImageNet标号的错误率本来挺高的,估计有1%
CIFAR-10是一个很小的数据集,跑起来相对来说比较容易,32*32,五万个样本,10类的数据集
在整个残差连接,如果后面新加上的层不能让模型变得更好的时候,因为有残差连接的存在,新加的那些层应该是不会学到任何东西,应该都是靠近0的,这样就等价于就算是训练了1000层的ResNet,但是可能就前100层有用,后面的900层基本上因为没有什么东西可以学的,基本上就不会动了
这篇文章没有结论
mAP:目标检测上最常见的一个精度,锚框的平均精度,越高越好
为什么ResNet训练起来比较快?
-
一方面是因为梯度上保持的比较好,新加一些层的话,加的层越多,梯度的乘法就越多,因为梯度比较小,一般是在0附近的高斯分布,所以就会导致在很深的时候就会比较小(梯度消失)。虽然batch normalization或者其他东西能够对这种状况进行改善,但是实际上相对来说还是比较小,但是如果加了一个ResNet的话,它的好处就是在原有的基础上加上了浅层网络的梯度,深层的网络梯度很小没有关系,浅层网络可以进行训练,变成了加法,一个小的数加上一个大的数,相对来说梯度还是会比较大的。也就是说,不管后面新加的层数有多少,前面浅层网络的梯度始终是有用的,这就是从误差反向传播的角度来解释为什么训练的比较快
_第103张图片](http://img.e-com-net.com/image/info8/61928d72e6a847afb2a63a65a8b01766.jpg)
-
在CIFAR上面加到了1000层以上,没有做任何特别的regularization,然后效果很好,overfitting有一点点但是不大。SGD收敛是没有意义的,SGD的收敛就是训练不动了,收敛是最好收敛在比较好的地方。做深的时候,用简单的机器训练根本就跑不动,根本就不会得到比较好的结果,所以只看收敛的话意义不大,但是在加了残差连接的情况下,因为梯度比较大,所以就没那么容易收敛,所以导致一直能够往前(SGD的精髓就是能够一直能跑的动,如果哪一天跑不动了,梯度没了就完了,就会卡在一个地方出不去了,所以它的精髓就在于需要梯度够大,要一直能够跑,因为有噪音的存在,所以慢慢的他总是会收敛的,所以只要保证梯度一直够大,其实到最后的结果就会比较好)
_第104张图片](http://img.e-com-net.com/image/info8/6dafa6f33af34dfe9f86e2a37b287819.jpg)
为什么ResNet在CIFAR-10那么小的数据集上他的过拟合不那么明显?
open question
虽然模型很深,参数很多,但是因为模型是这么构造的,所以使得他内在的模型复杂度其实不是很高,也就是说,很有可能加了残差链接之后,使得模型的复杂度降低了,一旦模型的复杂度降低了,其实过拟合就没那么严重了
- 所谓的模型复杂度降低了不是说不能够表示别的东西了,而是能够找到一个不那么复杂的模型去拟合数据,就如作者所说,不加残差连接的时候,理论上也能够学出一个有一个identity的东西(不要后面的东西),但是实际上做不到,因为没有引导整个网络这么走的话,其实理论上的结果它根本过不去,所以一定是得手动的把这个结果加进去,使得它更容易训练出一个简单的模型来拟合数据的情况下,等价于把模型的复杂度降低了
这篇文章的residual和gradient boosting是不一样的
1. gradient boosting是在标号上做residual
2. 这篇文章是在feature维度上
李沐精讲
随着我们设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要。更重要的是设计网络的能力,在ResNet这种网络中,添加层会使网络更具表现力
函数类
_第105张图片](http://img.e-com-net.com/image/info8/26fa4908053e4ee2b9def2f98a111a1e.jpg)
虽然模型更大,但是可能学偏了,所谓的模型偏差。如果更大的模型里面包含小模型,我学到的模型就会严格的比前面更大,所以至少不会变差
_第106张图片](http://img.e-com-net.com/image/info8/246fa53c27184df1a1e5aac194dd8dfd.png)
_第107张图片](http://img.e-com-net.com/image/info8/384f1cc9c5a24074b41365e16cbd34ad.jpg)
_第108张图片](http://img.e-com-net.com/image/info8/eb2ef43d44a346edbb34bcd8b2656c82.jpg)
- 矩阵乘法变加法,抑制梯度消失//利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
- 模型虽然变大,但是模型偏差也变大了,过拟合了噪声,而跳连接使得新加入的块学习目标是f(x)与前一层模型输出x的残差,就是带有明确的目的去学,缺什么学什么。
残差块
- 神经网络中的具体实现:假设我们的原始输入为x,而希望学出的理想映射为f(x),左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x)−x。而右图正是ResNet的基础架构–残差块(residual block)
_第109张图片](http://img.e-com-net.com/image/info8/dae199c56aca41f5a4c9d7548b681fc9.jpg)
_第110张图片](http://img.e-com-net.com/image/info8/94648b02592241aab5d2297828438b7a.jpg)
残差块的代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
# 第二个卷积层
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
# 如果使用1 x 1卷积以使得输入变换成需要的形状
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
# 对应第一个卷积层的批量规范化层
self.bn1 = nn.BatchNorm2d(num_channels)
# 对应第二个卷积层的批量规范化层
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
# 第一层:卷积 -> 规范化 -> relu激活
Y = F.relu(self.bn1(self.conv1(X)))
# 第二层:卷积 -> 规范化
Y = self.bn2(self.conv2(Y))
# 如果要让输入变换成需要的形状
if self.conv3:
# 对X使用1 x 1卷积,以使输出成为需要的形状
X = self.conv3(X)
# 嵌套模型的实现,即对上一次训练后的模型进行嵌套
Y += X
# relu激活并输出
return F.relu(Y)
_第111张图片](http://img.e-com-net.com/image/info8/7042042f611b447f9e2a20793dfaec25.jpg)
_第112张图片](http://img.e-com-net.com/image/info8/497b8b40db4e462084f239570da7b64b.jpg)
resnet模型
- ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7×7卷积层后,接步幅为2的3×3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
- GoogLeNet在后面接了4个由Inception块组成的模块。 ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
- 接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
- 最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
- 每个模块有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为ResNet-18。 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。 虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。
_第113张图片](http://img.e-com-net.com/image/info8/bed1b8e42ae04d85bc415052aef5b8b6.jpg)
_第114张图片](http://img.e-com-net.com/image/info8/38cd1b0d76534f29b2497f425d27b97c.jpg)
_第115张图片](http://img.e-com-net.com/image/info8/1d64380076f8498bbfdd001db3a523a1.jpg)
左conv-block 右 identity-block。右图可以看到,通过stride=2实现了图像下采样,并扩充了通道数。
_第116张图片](http://img.e-com-net.com/image/info8/8e1cc9bcd91f4d94ae019cdd7ed619b3.jpg)
进一步,在下图可以多个模板中同时存在conv-block 和 identity-block两种模式。本质区别就是有没有下采样downsample和通道转换
_第117张图片](http://img.e-com-net.com/image/info8/639ae7f5d7654ec1a03619c03c5ee7de.jpg)
总结
_第118张图片](http://img.e-com-net.com/image/info8/0cf453bb36904cd0befea86285a059d3.jpg)

如果g(x)很难训练或者训练没有什么好处的话他就会在梯度反传拿不到梯度,所以他的权重就不会被更新了
_第119张图片](http://img.e-com-net.com/image/info8/cfdafe0443644e94b8a1d0c491864900.jpg)
_第120张图片](http://img.e-com-net.com/image/info8/184c170394934232852276dc3bfb55d8.jpg)
从梯度的角度: 梯度连乘变加法,最下面的层(靠近数据层)也能拿到更大的梯度,不管网络多深,我都能拿到比较大的梯度做高效的更新
1.恒等映射 2. 梯度消失,梯度连乘变加法3.梯度相关性