线性模型--线性回归、岭(脊)回归、lasso回归
1、线性回归
给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D=\{(x_{1}, y_{1}),(x_{2}, y_{2}),...,(x_{m}, y_{m})\} D={(x1,y1),(x2,y2),...,(xm,ym)},其中 x i = ( x i 1 ; x i 2 ; . . . ; x i d ) , y i ∈ R x_{i}=(x_{i1};x_{i2};...;x_{id}),y_{i} \in \Bbb R xi=(xi1;xi2;...;xid),yi∈R。线性回归通过学习一个线性模型,用以准确预测实值的标签。
- 简单形式(一元线性回归):
线性模型试图学得公式:
f ( x i ) = w x i + b , 使 得 f ( x i ) ≃ y i f(x_{i})=wx_{i}+b,使得 f(x_{i})\simeq y_{i} f(xi)=wxi+b,使得f(xi)≃yi
均方误差是回归问题中常用的性能度量(损失函数),为了确定w和b,可以使均方误差最小化,即
( w ∗ , b ∗ ) = a r g m i n ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = a r g m i n ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 \begin{aligned} (w^{*},b^{*}) =& \mathop{arg\:min}_{(w,b)}\sum_{i=1}^{m}(f(x_{i})-y_{i})^{2} \\ =& \mathop{arg\:min}_{(w,b)}\sum_{i=1}^{m}(y_{i}-wx_{i}-b)^{2} \end{aligned} (w∗,b∗)==argmin(w,b)i=1∑m(f(xi)−yi)2argmin(w,b)i=1∑m(yi−wxi−b)2
由于 E ( w , b ) = ∑ i = 1 m ( y i − w x i − b ) 2 E_(w,b)=\sum_{i=1}^{m}(y_{i}-wx_{i}-b)^{2} E(w,b)=∑i=1m(yi−wxi−b)2为凸函数,当关于w和b的偏导都为0时,可以得到w和b的最优解。
∂ E ( w , b ) ∂ w = 2 ( w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ) , ∂ E ( w , b ) ∂ b = 2 ( m b − ∑ i = 1 m ( y i − w x i ) ) \begin{aligned} \frac{\partial E_{(w,b)}}{\partial w} =&2\Bigg(w\sum_{i=1}^{m}{x_{i}^{2}}-\sum_{i=1}^{m}{(y_{i}-b)}x_{i}\Bigg),\\ \frac{\partial E_{(w,b)}}{\partial b} =&2\Bigg(mb-\sum_{i=1}^{m}{(y_{i}-wx_{i})}\Bigg) \end{aligned} ∂w∂E(w,b)=∂b∂E(w,b)=2(wi=1∑mxi2−i=1∑m(yi−b)xi),2(mb−i=1∑m(yi−wxi))
令偏导等于0,则可解得w和b最优解的闭式:
w = ∑ i = 1 m y i ( x i − x ‾ ) ∑ i = 1 m x i 2 − 1 m ( ∑ i = 1 m x i ) 2 b = 1 m ∑ i = 1 m ( y i − w x i ) \begin{aligned} w=&\frac{\sum_{i=1}^{m}{y_{i}(x_{i}-\overline x)}}{\sum_{i=1}^{m}{x_i^2}-\frac {1}{m}(\sum_{i=1}^m{x_i})^2}\\ b=&\frac{1}{m}\sum_{i=1}^m(y_i-wx_i)\\ \end{aligned} w=b=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−x)m1i=1∑m(yi−wxi)
其中, x ‾ = 1 m ∑ i = 1 m x i \overline x=\frac{1}{m}\sum_{i=1}^m x_i x=m1∑i=1mxi为x的均值。
- 一般形式(多元线性回归):
样本由d个属性描述,此时试图学得
f ( x i ) = w x i + b , 使 得 f ( x i ) ≃ y i \begin{aligned} f(\boldsymbol {x_{i}})=wx_{i}+b,使得 f(\boldsymbol {x_{i}})\simeq y_{i} \end{aligned} f(xi)=wxi+b,使得f(xi)≃yi
类似的,可以使用最小二乘法对w和b估计,为了便于讨论,将w和b合并 w ^ = ( w ; b ) \hat w=(w;b) w^=(w;b),即
X = ( x 11 x 12 ⋯ x 1 d 1 x 21 x 22 ⋯ x 2 d 1 ⋮ ⋮ ⋱ ⋮ ⋮ x m 1 x m 2 ⋯ x m d 1 ) = ( x 1 T 1 x 2 T 1 ⋮ ⋮ x m T 1 ) X=\left(\begin{matrix} x_{11} & x_{12} & \cdots & x_{1d} & 1 \\ x_{21} & x_{22} & \cdots & x_{2d} & 1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m1} & x_{m2} & \cdots & x_{md} & 1 \end{matrix}\right) ={\left(\begin{matrix} \boldsymbol{x_1^T} & 1 \\ \boldsymbol{x_2^T} & 1 \\ \vdots & \vdots \\ \boldsymbol{x_m^T} & 1 \end{matrix}\right)} X=⎝⎜⎜⎜⎛x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd11⋮1⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x1Tx2T⋮xmT11⋮1⎠⎟⎟⎟⎞
标签的向量形式 y = ( y 1 ; y 2 ; ⋯ ; y m ) \boldsymbol y=(y_1;y_2;\cdots;y_m) y=(y1;y2;⋯;ym),则均方误差(损失函数)可得:
w ^ ∗ = a r g m i n w ^ ( y − X w ^ ) T ( y − X w ^ ) \begin{aligned} \hat w^* = \mathop {arg\:min}_{\hat w}{(\boldsymbol{y-X\hat w})^T(\boldsymbol{y-X\hat w})} \end{aligned} w^∗=argminw^(y−Xw^)T(y−Xw^)
令 E w ^ = ( y − X w ^ ) T ( y − X w ^ ) E_{\hat w}= {(\boldsymbol{y-X\hat w})^T(\boldsymbol{y-X\hat w})} Ew^=(y−Xw^)T(y−Xw^)```,对 w ^ \hat w w^求导得:
∂ E w ^ ∂ w ^ = 2 X T ( X w ^ − y ) \frac{\partial E_{\hat w}}{\partial \hat w}=2\boldsymbol X^T(\boldsymbol{X\hat w-y}) ∂w^∂Ew^=2XT(Xw^−y)
令导数为0,当 X T X \boldsymbol X^T \boldsymbol X XTX为满秩矩阵或正定矩阵,可得:
w ^ ∗ = ( X T X ) − 1 X T y \hat w^*=(\boldsymbol X^T \boldsymbol X)^{-1} \boldsymbol X^T \boldsymbol y w^∗=(XTX)−1XTy
2、岭回归和lasso回归
在实际任务中 X T X X^T X XTX往往不满秩。在许多任务中由于特征大于样本数量,导致存在多个 w ^ \hat w w^满足损失函数最小。通过引入正则化项,作为选择解的依据。正则化项,也可以看做用来衡量模型复杂程度,用来防止过拟合。
1)岭回归
在损失函数上添加惩罚项 λ ∣ ∣ w ∣ ∣ 2 \lambda||w||^2 λ∣∣w∣∣2```,称为L2正则化。等价于:
f ( w ) = ∑ i = 1 m ( y i − x i T w ) 2 s . t . ∑ i = 1 n w i 2 ≤ t \begin{aligned} &f(w)=\sum_{i=1}^m (y_i-x_i^Tw)^2 \\ &s.t. \sum_{i=1}^n w_i^2 \le t \end{aligned} f(w)=i=1∑m(yi−xiTw)2s.t.i=1∑nwi2≤t
解得
w ^ = ( X T X + λ I ) − 1 X T y \begin{aligned} \hat w=(X^T X + \lambda I)^{-1}X^Ty \end{aligned} w^=(XTX+λI)−1XTy
可以看到,就是通过将$X^T X $加上一个单位矩阵变成非奇异矩阵,则可以进行求逆运算。
- 岭回归的几何意义
以两个变量为例, 残差平方和可以表示为 w 1 , w 2 w_1,w_2 w1,w2的一个二次函数,是一个在三维空间中的抛物面,可以用等值线来表示。而限制条件 w 1 2 + w 2 2 ≤ t w_1^2+w_2^2 \le t w12+w22≤t, 相当于在二维平面上圆心为原点的一个圆。等值线与圆相切的点便是在约束条件下的最优点。
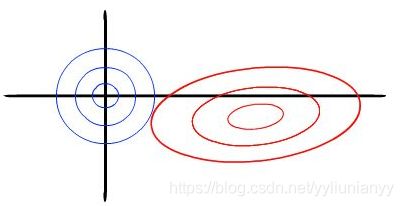
如图,可以看出岭回归更容易得到非零解。
- 岭回归的一些性质
a. 当岭参数 λ = 0 \lambda=0 λ=0 时,得到的解是最小二乘解
b. 当岭参数 λ \lambda λ 趋向更大时,岭回归系数 w i w_i wi 趋向于0,约束项 t t t很小
2)lasso回归
与岭回归相比的不同之处在于在损失函数上添加惩罚项 λ ∣ ∣ w ∣ ∣ 1 \lambda||w||_1 λ∣∣w∣∣1,称为L2正则化。等价于:
f ( w ) = ∑ i = 1 m ( y i − x i T w ) 2 s . t . ∑ i = 1 n ∣ w i ∣ ≤ t \begin{aligned} &f(w)=\sum_{i=1}^m (y_i-x_i^Tw)^2 \\ &s.t. \sum_{i=1}^n |w_i| \le t \end{aligned} f(w)=i=1∑m(yi−xiTw)2s.t.i=1∑n∣wi∣≤t
- lasso回归的几何意义
同样以两个变量为例,标准线性回归的损失函数还是可以用二维平面的等值线表示,而约束条件则与岭回归的圆不同,lasso的约束条件可以用方形表示。

如图,可以看出更容易在坐标轴上取得最优解。
3)总结
岭回归和lasso回归都是为了解决损失函数在求解过程中 X T X X^T X XTX 不可逆的问题,以及过拟合问题。其中,正则化系数 λ \lambda λ越大,则系数趋近与0,造成欠拟合; λ \lambda λ 越小,则容易造成过拟合。
相比于岭回归,lasso回归更由于岭回归,一方面是lasso重部分系数归于0,使得计算量小于岭回归;另一方面lasso更能直观的突出特征的重要程度,因为lasso得到的是稀疏解,也可以理解为降维。
参考
机器学习. 周志华
https://zhuanlan.zhihu.com/p/30535220