UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning(通过跨模态对比学习实现统一模态的理解和生成)
1.现有方法的不足:
目前的方法要么只能专注于单模态的任务,要么只能专注于多模态任务,而不能将这二者有机地统一在一起互相补充
2.创新点:
提出UNIMO这一统一模态的预训练架构,可以有效地适应单模态和多模态的理解和生成任务。预训练可以包含三部分:单一的image、单一的text、以及paired image-text。UNIMO通过从单模态提取知识融入到多模态的学习中,从而适应单模态与多模态的任务
3.模型概述:
UNIMO有效利用大规模的文本语料库和图像集合来学习general textual and visual representations。CMCL将visual representations 和 textual representations 基于image-text pairs对齐,统一到同一个语义空间。
对齐方式:text rewriting来提高跨模态信息的多样性。对于image-text pair的图片说明文字进行不同层次的重写,就能够得到各种positive examples 和 hard negative examples.此外,为了从单模态信息吸收更多的背景信息,还采用了text and image retrieval(文本和图像检索)这种方法,利用相关的文本和图像来增加每个图像-文本对
CMCL针对positive pairs,negative pairs,related images and text共同学习

4.模型详解
UNIMO采用多层的自注意力机制的Transformer来学习文本和视觉数据的统一语义表示。
对于文本输入W,W被分割为一个单词序列:
W = {[CLS] , w1 , …… , wn , [SEP] }
然后运用自注意力机制学习上下文语义信息 {h[CLS], hw1, …, hwn, h[SEP]}
对于图像输入V,V被转化为区域特征序列:
V = {[IMG], v1 ,……,vt} ([IMG]表示整张图像的表示)
然后利用自注意力机制学习相邻区域的表示 {h[IMG], hv1, …, hvt}
利用Faster R-CNN检测显著图像区域,并提取出每个区域的视觉特征
对于图像-文本对,将视觉特征和文本特征连接在一起为一个序列
{[IMG] , v1 , ……, vt , [CLS] , w1 , …… , wn , [SEP]}
提取h[IMG]和h[CLS]分别作为图像V和文本W的语义表示
基于大量的图像,文本,图像-文本对,UNIMO就可以学习视觉信息和文本信息,再通过CMCL将他们统一到同一个语义空间内
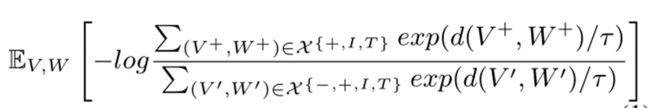
文本重写
对一张图片的caption,也就是说明文字进行不同级别的重写,包括三部分:sentence-level,phrase-level,word-level。对于句子层面的重写,采用了back-translation(反向翻译技术)来获取positive samples,具体而言,将图像的说明文字翻译成另一种语言,然后再翻译成原始语言。这种方式,可以产生几个类似的caption。对于每一个的Image-text文本,基于TFIDF相似度找出最相似的caption,找出来的结果与原始的caption非常相似,但不能准确描述对应的图像,可以作为hard negative samples,增强图像与文本的句子级对齐。
对于短语级以及词语级的重写,将一张image解析为scene graph,随机替换scene graph中的对象、属性、关系节点等等,使用不同的对象、属性、关系节点,这样就可以产生大量的hard negative samples
图像/文本检索
图像/文本检索的目的:在跨模态学习的过程中融入更多的单模态信息,每个image-text都进一步从单模态信息中检索到的图像和文本进行补充。具体来说,对于一个图像,图像集合中的其他图像将按照其视觉相似性进行排序。将那些与原始图像有高度重叠对象的图像提取出来,提供相关的视觉信息。同样,基于语义相似度提取与原字幕语义相关的句子,提供背景语言信息。将检索到的图像和文本分别用统一模态变压器进行编码,如图3所示,提取图像和文本的表示,计算公式1中的交叉模态对比损耗。这些检索到的单模态信息为更好的跨模态学习提供了丰富的背景信息。将检索到的单模态信息分别用unified-modal Transformer进行编码,学习背景信息
视觉学习
类比BERT中的MLM,对图像区域进行采样,并且将15%的图像特征mask掉,masked 的区域被0来代替。由于一幅图像中的区域是高度重叠的,选择mask所有相互交点比例高的区域,避免了信息泄露。随机选择mask 的anchors(锚点),对重叠率大于0.3以上的区域进行mask。
对于一幅图像,模型reconstruct masked regions通过给定的剩下的regions,而对于image-text则需要考虑文本的存在
使用feature regression 和 region classification 来学习视觉的表示
语言学习
两种模型:bidirectional predicition 和 sequence-to-sequence
感觉很像BERT的两大下游任务:带mask的语言模型训练以及Next Sentence Prediction
bidirectional predicition: 迭代采样直到采出15%的tokens,也就是不断地截取一句话,句子的长度从几何分布中取,对于这些句子进行8:1:1的mask,80%替代为mask,10%替代为随机的token,10%替代为原来的token,然后开始做完形填空,学习上下文信息
sequence-to-sequence: 迭代采样直到采出25%的tokens,句子长度按均匀分布U(4,32)取,将选中的句子,前后加上 [CLS] 和 [SEP],表示这被截取出来的句子的开头与结尾,将这些片段句子从文本中删除,并拼接为target sequence,剩余部分接为source sequence。训练模型使通过source sequence 能产生 target sequence
